
基于Spark MLlib的证券账户行为模式分析-上交所黄寅飞
本文基于Spark MLlib软件库,对证券账户特征进行K均值和高斯混合模型聚类,并对投影空间进行三维展示。利用距离指标和熵指标,指导K值选择,观察聚类效果和训练时间间的关系,并分析离群点特性。结果表明,开源机器学习工具在分布式环境可获得良好计算效果。...
本文基于Spark MLlib软件库,对证券账户特征进行K均值和高斯混合模型聚类,并对投影空间进行三维展示。利用距离指标和熵指标,指导K值选择,观察聚类效果和训练时间间的关系,并分析离群点特性。结果表明,开源机器学习工具在分布式环境可获得良好计算效果。...

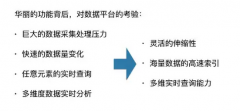
证券交易数据属于典型的结构化数据,采用Sql on Hadoop[1]技术,既可用廉价PC服务器获得良好的容量线性扩展能力,又可提供便于统计分析的SQL接口方便数据应用开发。...

本文中阐述的原理基于 Spark 2.1 版本,阅读本文需要读者有一定的 Spark 和 Java 基础,了解 RDD、Shuffle、JVM 等相关概念。...
大家好,我是来自GrowingIO的数据工程师付旗,今天跟大家分享的是我们GrowingIO在使用Spark中的经验,遇见的一些问题,以及我们修复的方法。在来之前,昨天晚上我在跟我们组同事讨论的时候,我说我发给他们简要写的我是GrowingIO的大数据工程师,我们组的几...
基于Apache Spark推出的IBM z/OS平台具备Apache Spark core、Spark SQL、Spark Streaming、Machine Learning Library (MLlib)和Graphx等开源功能,可提供业内唯一的主机常驻Spark数据提取解决方案。...

IBM公司宣布将主要承担Apache Spark项目,充分展现了IBM公司对于Apache Spark的重要性充满信心。...

IBM表示,Spark就像是MapReduce——一种规模几乎无限的架构——能够对大规模数据处理带来革命性的改变。当然,Spark在某些地方开始取代MapReduce。...
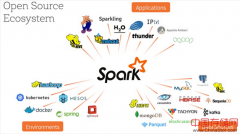
在生态建设上,Spark取得极大的成功,其主要体现在application、environment及datasource三方面。Spark的贡献者目前超过650人,围绕Spark创业的公司同样增多,“SparkasaService”这个概念也被越来越多人接受。...

英特尔推出了Apache Spark,为Hadoop集群带来了速度极高的内存内分析能力,从而将大规模数据集的处理周期由几小时成功缩短为几分钟。目前英特尔和优酷合作,帮助优酷将传统业务迁移到Spark上,优化大数据分析,分析时间从40个小时缩短到3个小时以下。...

Spark可能并不成熟,但将会持续下去。这篇文章作者PeterSchlampp是大数据分析提供商Platfora产品副总裁,他认为Spark的时代才刚刚开始。...
随着数据量的爆炸式增长、数据来源和结构的多样化,传统IT基础架构已无法满足企业对数据处理的需求,Hadoop、Spark等支持PB级别数据的分布式存储和分布式计算框架应运而生。...

Spark Windows 调试环境搭建教程,1、安装Scala。(建议2.10.2版本),完成后,在windows命令行中输入scala,检查是否识别此命令。...

IBM承诺将Spark嵌入IBM业内领先的分析和商务平台,并将Spark作为一项服务在IBM Bluemix平台上提供给客户。...

üWA是业界首个完全基于商用芯片的解耦架构微服务器,其计算节点和存储节点可以任意混搭,在简化管理的同时,耗电量相比普通PC服务器降低50%以上,设备体积压缩到25%以下。...

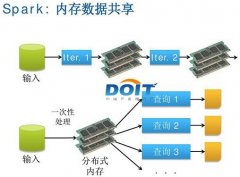
Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发,Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的概念。...
尽管Spark还仅仅是个相对年轻的数据项目,但其能够满足前面提到的全部需求,甚至可以做得更多。在今天的文章中,我们将列举五大理由,证明为什么由Spark领衔的时代已经来临。...

关于spark的三个常见疑问解惑,如果以前没有部署过其它的大数据集群,集群中的计算框架只有Spark,建议直接使用Standalone,如果集群中在运行Spark计算平台的同时还运行了Hadoop的MapReduce、Storm等其它框架,建议使用mesos或者yarn。...
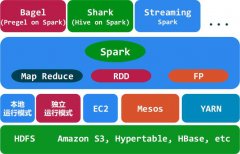
什么是Spark?Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点,Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。目前大数据系统的三大产品是hadoop、spark、storm,三者计算方式不同,各有特点。...

由CSDNCODE翻译社区组织的长篇论文翻译AnArchitectureforFastandGeneralDataProcessingonLargeClusters经过40余名译者的努力终于全部翻译完成。...

Spark火了。在国外 Yahoo!、Twitter、Intel、Amazon、Cloudera 等公司率先应用并推广 Spark 技术,Spark能否成为Hadoop的替代者呢?为什么?它们有哪些相似点与区别?...
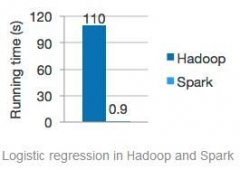
基于Hadoop就需要分别构建实时流处理团队、数据统计分析团队、数据挖掘团队等,而且这些团队之间无论是代码还是经验都不可相互借鉴,会形成巨大的成本,而使用Spark就不存在这个问题。...

这篇文章将介绍腾讯TDW使用千台规模的Spark集群来对千亿量级的节点对进行相似度计算这个案例,通过实验对比,我们优化后的性能是MapReduce的6倍以上,是GraphX的2倍以上。...

《数据湖(Data Lake)的未来架构:基于Tachyon和Apache Spark的In-memory数据交换平台》的文章,表达Pivotal与EMC对下一代数据湖技术的展望。...
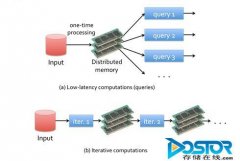
Spark内存计算框架适合各种迭代算法和交互式数据分析,能够提升大数据处理的实时性和准确性。“Spark记录着数据产生的每一个操作,能够可靠地将这些数据存储在内存之中,这使得它非常适用于第掩饰的计算和有效的迭代算法。”Cloudera表示。...