大家好,我是来自GrowingIO的数据工程师付旗,今天跟大家分享的是我们GrowingIO在使用Spark中的经验,遇见的一些问题,以及我们修复的方法。在来之前,昨天晚上我在跟我们组同事讨论的时候,我说我发给他们简要写的我是GrowingIO的大数据工程师,我们组的几
大家好,我是来自GrowingIO的数据工程师付旗,今天跟大家分享的是我们GrowingIO在使用Spark中的经验,遇见的一些问题,以及我们修复的方法。在来之前,昨天晚上我在跟我们组同事讨论的时候,我说我发给他们简要写的我是GrowingIO的大数据工程师,我们组的几个工程师都非常的不屑,说现在大数据已经烂大街了,所以他们对外自称数据工程师,不叫大数据工程师。
GrowingIO业务功能背后的考验
事实上,我们是一个刚成立一年的公司,今年5月份刚过了一周岁的生日,是一个标准的创业公司,但是到目前为止我们每天处理的数据量已经超过了几百亿条,所以在我看来是一个标准的大数据公司。
每天处理这么多数据的话,我们当然会遇到很多问题,今天主要的内容就是首先介绍我们公司,我们的业务模型和我们遇到的一些问题。第二部分我们会根据这些问题讲一下我们是如何思考和选择搭建我们自己的大数据平台。最后一部分,当我们平台搭建完之后,会遇到一些问题,我们会想办法去优化在Spark使用过程中的这些问题。
第一部分就是我们公司介绍,我们是去年刚成立的一家公司,是做数据分析的,我们跟之前的数据公司不一样就是我们提供的是全量采集的数据,不需要埋点,只要接入我们SDK之后,你就立刻能够获得你想要的数据分析的结果。我们现在提供iOS、安卓、Web、H5的SDK。
我们采用的是全量采集的方案,所以不需要提前埋点,就是说所有的浏览、访问、点击所有的行为都会被采集到,这个数据量是非常大的,而且我们提供按需筛选数据的功能,如果你想要知道某一个按键的点击量,我们会立刻帮你筛选出来。还有我们支持随时回溯任意一个事件。我们也支持不同的图表功能、不同的维度、相互的拖拽和组合,我们提供40多种不同的维度。
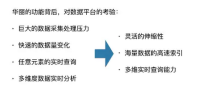
提供这么多功能的话对我们平台的压力是非常大的。首先就是我们的数据处理压力非常大,我们每天要处理好几百亿条数据,我们的数据量变化也非常快,有些应用可能周五是高峰期,有些应用是周末的高峰期,所以我们的数据有一个波峰和波谷的概念。我们支持任意元素的实时查询,以及支持多维度的组合,所以需要整个数据平台有很强的伸缩性。我们还要支持海量数据的高速索引,不能让用户等待时间过长,同时我们要支持多维数据的实时查询。
GrowingIO数据平台搭建
为了支持这么多功能,我们怎么搭建我们的数据平台的呢?
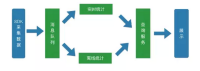
先看一下我们数据处理的主要步骤,首先是我们SDK采集数据,采集数据之后,首先把它扔到我们的消息队列里做一个基础的持久化,之后我们会有两部分,一部分是实时统计,一部分是离线统计,这两部分统计完之后会把统计结果存下来,然后提供给我们的查询服务,最后是我们外部展示界面。我们的数据平台主要基于中间的四个绿色的部分。
关于要求,对消息队列来说肯定是吞吐量一定要大,要非常好的扩展性,如果有一个消息的波峰的话要随时能够扩展,因为所有的东西都是分布式的,所以要保证节点故障不会影响我们正常的业务。
我们的实时计算目前采用的是分钟级别的实时,没有精确到秒级,离线计算需要计算速度非常快,这两部分我们当初在考虑的时候就选用了Spark,因为Spark本身既支持实时,又支持离线,而且相对于其他的实时的方案来说,像Flink或者是Storm和Samza来说,我们不需要到秒级的这种实时,我们需要的是吞吐量,所以我们选择Spark。实时部分用的是Spark streaming,离线部分用的是Spark offline的方案。
查询方案因为我们要支持多个维度的组合排序,所以我们希望支持sql,这样的话各种组合排序就可以转化成sql的group和order操作。
消息队列 -- Kafka
消息队列我们选择的是Kafka,因为在我们看来,Kafka目前是最成熟的分布式消息队列方案,而且它的性能、扩展性也非常好,而且支持容错方案,你可以通过设置冗余来保证数据的完整性。 Kafka目前得到了所有主流流式计算框架的支持,像Spark, Flink, Storm, Samza等等;另外一个就是我们公司的几个创始人都来自于LinkedIn,他们之前在LinkedIn的时候就已经用过Kafka,对Kafka非常熟,所以我们选择了Kafka。
消息时序 -- HBase
但选定Kafka之后我们发现了一个问题就是消息时序的问题。首先我们的数据采集 程中,因为不同的用户网络带宽不一样,数据可能是有延迟的,晚到的消息反而可能更早发生,而且Kafka不同的partition之间是不保证时序的。
但是我们所有的离线统计程序都是需要按时间统计的,所以我们就需要一个支持时序的数据库帮我们把数据排好序,这里我们选了HBase。我们用消息产生的时间加上我们生成消息的ID做成它唯一的row key,进行排序和索引。
SQL On HBase -- Apache Phoenix
对于sql的方案来说,我们选择的是Phoenix。选Phoenix是因为我们考虑了目前几个SQL On HBase的方案,我们发现Phoenix的效率非常好,是因为它充分的利用了HBase coprocessor的特性,在server端进行了大量的计算,所以大量减轻了client的数据压力还有计算压力。
还有就是它支持HBase的Column Family概念,比如说我们要支持40个纬度的时候我们会有一张大宽表,如果我们把所有的列都设置一个列族的话,在查询任意一个列的时候都需要把40列的数据都读出来,这样是得不偿失的,所以Phoenix支持Column Family的话,我们就可以把不同的列根据它们的相关性分成几个列族,查询的时候可能只会命中一个到两个列族,这样大大减少了读取量。
Phoenix还支持Spark的DataSource API,支持列剪枝和行过滤的功能,而且支持数据写入。什么是Spark的DataSource API呢, Spark在1.2的时候提供了DataSource API,它主要是给Spark框架提供一种快速读取外界数据的能力,这个API可以方便的把不同的数据格式通过DataSource API注册成Spark的表,然后通过Spark SQL直接读取。它可以充分利用Spark分布式的优点进行并发读取,而且Spark本身有一个很好的优化引擎,能够极大的加快Spark SQL的执行。
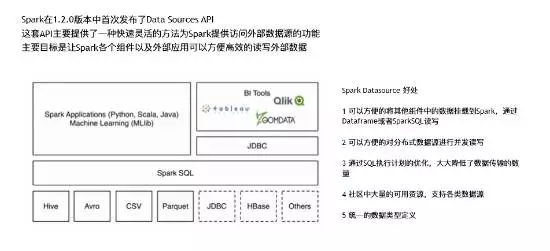
因为Spark最近非常的火,所以它的社区资源非常的多,基本上所有主流的框架,像我们常见的Phoenix,Cassandra, MongoDB都有Spark DataSource相关的实现。还有一个就是它提供了一个统一的数据类型,把所有的外部表都统一转化成Spark的数据类型,这样的话不同的外部表能够相互的关联和操作。
在经过上述的思考之后,我们选择了这样的一个数据框架。
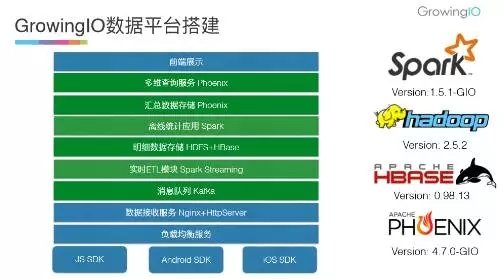
首先我们最下面是三个SDK,JS、安卓和iOS,采集完数据之后会发到我们的负载均衡器,我们的负载均衡器用的是AWS,它会自动把我们这些数据发到我们的server端,server在收集完数据之后会进行一个初步的清洗,把那些不规律的数据给清洗掉,然后再把那些数据发到Kafka里,后面就进入到我们的实时和离线过程。
最终我们的数据会统计到HBase里面,对外暴露的是一个sql的接口,可以通过各种sql的组合去查询所需要的统计数据。目前我们用的主要版本,Spark用的还是1.5.1,我们自己根据我们自己的业务需求打了一些定制的patch,Hadoop用的还是2.5.2,HBase是0.98,Phoenix是4.7.0,我们修复了一些小的bug,以及加了一些自己的特性,打了自己的patch。
Spark实践与优化
第三部分讲一下我们在使用这个数据平台的过程中的一些实践和优化的地方,因为搭建完平台之后这种东西不是一蹴而就的,分布式的方案会有很多的问题,现在开源的东西进化的很快,新的东西出来之后可能会有很多bug,包括我们当时在用DataFrame API的时候发现了重复计算、包括内存泄露等bug,所以就需要很好的优化能力,及时的发现这些问题并优化它。
我们目前实时处理的流程是这样的。
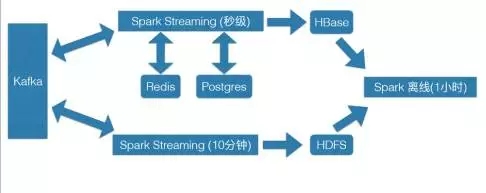
从Kafka之后,分成两块,一块是秒级的Spark Streaming,大概在10秒-20秒的一个batch,然后把这些数据进行初步的清洗,把一些重要的数据存到HBase里面,然后提交Spark任务做计算。
还有一部分会把全量的数据存到HDFS里,但是存HDFS会有一个问题,就是如果你batch时间过短的话会产生大量的碎文件,我们的想法就是把Spark Streaming的batch时间设长,10分钟一个batch,这样的话会大量减少我们写入HDFS的文件数量。
同时在Spark Streaming里面,我们借助了Redis和Postgres的一些存储的方案。比如说在Redis里,我们会进行一些简单的计数,或者存一些相应关联的信息。然后在Postgres里,我们存了大量用户自定义的规则和属性,Spark Streaming处理过程中会去读Redis或者是关联对应的Postgres。
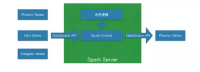
我们离线任务使用我们自己定制的Spark Server,我们写好对应的业务逻辑,然后提交任务给Spark Server。Spark Server执行这些任务,从HBase和Hive表里通过DataSource API读入一些数据,然后进行计算,清洗和整理之后,再通过DataSource API存到HBase里,用来查询的。
优先使用Spark SQL & DataFrame
我们的数据逻辑有很多,所以分了不同的任务,每个任务会定义单独的Job,会定时的去提交Job。在我们使用Spark的时候,优先使用了DataFrame的API和SparkSQL,这也是新的Spark使用的方法,为什么呢?
因为首先SQL的表达更加简洁,因为SQL是一个比较通用的计算方案,各种表达很清晰,这种东西它表达能力远远比RDD要简洁。也更容易理解,更容易理解带来的好处就是更容易维护。
当然DataFrame和SQL比RDD的另一个好处就是,RDD对于Spark完全是一个黑盒,所以Spark并不知道如何去优化这个RDD的读取和存储,但DataFrame本身就包含了一个schema,它描述了它每个列都是什么样的数据类型。这样的话Spark在执行的时候就能够充分的理解它需要读哪些数据,这些数据是什么类型,在后续的时候,它就会去优化它的存储,从而大大的减少它在内存里的存储空间。
另外,Spark Dataframe, SQL还有现在刚出来的DataSet共享一套优化引擎,它会去优化一些没必要的操作和数据的读取,包括一些冗余的计算等等,这也会大大加快执行速度。
还有一点就是RDD、DataFrame和SQL它们之间可以相互转化,比如我们可以把Dataframe注册成一个临时表,这样就可以用SQL来进行操作,同时我们可以把DataFrame map成一个RDD,这样的话就可以重回到一个RDD的操作,Dataframe和SQL虽然表达能力很强,但是有时候会遇到一些无法表达的业务逻辑,这时我们就需要从SQL里转到DataFrame里,再重新转回RDD的模型来执行我们这些比较复杂的计算,当执行完之后我们把RDD的这部分数据重新注册成临时表,转回SQL模型,这样能大大的提高我们的开发速度,因为可以在三个模型之间相互转化。
Spark Server设计
下面讲一下Spark Server在设计过程中的一些思考。我们的Spark Server设计的首要的目标就是共享一个Spark Context,从而共享Spark资源。
之所以这样是因为如果用Spark Submit来提交任务的话,我们会遇到一个问题,就是任务如果执行的时间比较长,它可能会有一两个task执行的非常慢,导致整个资源无法释放。比如你申请了100核,但你可能98个任务都执行完了,剩下2个任务卡在那个地方会导致100个核都无法释放。
还有一个就是我们现在会跑很多临时的小任务 ,每个小任务时间可能只有十几秒,如果单独为这些小任务去申请资源的话,可能申请资源都得30秒或者1分钟。
还有一个就是没有法正确的预估我们所需要的资源,因为我们不同的任务有不同的任务模型,读的数据量是有差距的,所以计算的成本也是不一样的。我们数据量是有波峰波谷的,所以更加难以预估到某一个时间点,每个任务需要多少个核。
所以在这个情况下,我们共享一个Spark Context就可以给这个Spark申请更多的资源,这样其他的人来共享这个资源。
同时,在使用同一个Hive Context的时候会遇到一个问题,像长时间运行任务和一些比较快速的任务,它可能所需要的配置是不一样的,比如说你要读一个100G的任务,可能它需要的shuffle数量是1000,但比如说只1G的数据,可能10个shuffle就够了,所以我们支持使用不同的Hive Context,给不同的Context设置不同的参数,这样的话你在运行的时候可以自己指定你需要哪个Hive Context。
同时我们使用Fair Scheduler能够保证不同的任务同时共享资源。
我们给任务设定了一个优先级,每个任务提交的时候指定自己的优先级,我们根据任务的优先级与它创建的时间来选择执行顺序,我们同样支持非常重要的任务临时插队的方案,就是说在创建完之后立刻执行。
为了支持上面这个优先级和任务插队的这个方案,我们使用了Postgres作为任务的持久化。
它有很多好处,比如说支持重跑,如果任务有问题,最终跑下来的数字是不对的,就可以在Postgres里把这个任务重新提交一下。
同时在任务执行的时候,如果遇到了Exception我们会把对应的消息和堆栈信息存到Postgres表里,这样就可以知道每个任务失败的原因,什么时候失败的,在哪一行失败的。
因为是放在Postgres里,所以我们支持手动修改优先级,这样的话遇到一些紧急的情况我们可以优先启动一些比较紧急的任务。我们现在会定时的统计一下我们每个任务创建时间、被调起时间,以及最后完成的时间,来找到每个任务执行平均时间以及不同任务的瓶颈,从而找到优化点。
我们的任务逻辑是同样一个任务,可能是按时间来跑,比如说一个小时统计一次,这样的话同一个任务是有时间概念的。为了支持这种时间概念,我们就需要支持任务以单例模式运行,因为不同的任务不同时间段它的缓存表还有输出路径会相互影响的,以及任务之间可能是有依赖的,比如说九点到十点,可能依赖于八点到九点的结果,这样的话就需要这个任务以单例形式运行,而不是并行的运行。
为了避免任务之间的相互影响,我们为每个Executor配一个核,因为我们之前遇到一个问题, Spark支持每个Executor配多核,但是问题是,可能在这一个Executor上同时跑了不同的几个任务,这几种之间是相互影响的,如果这个Executor在跑一个很长的任务,它跑了一半的时候突然这边加了一个小任务,这个小任务可能会极大的影响、拖慢速度。第二它可能会把整个Executor卡死,这种情况在Spark中还是很常见的,比如数据有倾斜,内存溢出等等,可能会把整个Executor卡死,这就会导致这个Executor所有跑的任务都会挂掉,会影响那种长时间运行任务的效率。所以我们目前为每一个Executor只配了一个核。
我们还使用了Spark REST API来监控任务跑的时间,自动杀掉时间过长的任务,这种时间过长的任务有很多原因,比如说是数据倾斜,这是Spark任务中一个很常见的情况,还有可能就是代码逻辑有问题,或者说数据量有激增,这些都需要在杀掉之后去分析原因来进行优化。
遇到的问题
我们在使用Spark的过程中还遇到一些问题。这些问题可能有一些人也遇到过,我们可以分享一下我们在处理这些问题过程中的一些想法。
比如说我们遇到的Kafka重复消费的问题,对于我们来说Kafka的消费的目标不是用Exactly Once。当我们遇到一些问题一些统计逻辑或者一些数据晚到的问题的时候,我们需要从某一个时间点重新回追所有的数据,这样的话Kafka就要支持重复消费。
第二个就是当业务逻辑越来越多的时候, Spark Streaming就很难扩展。
第三、同时运行任务过多的时候,Spark Server的任务调度就会变慢,因为目前我们一天要跑一万多个任务,Spark Server同时运行的任务可能在100-200,当同时运行任务过多的时候,Spark Server就会变慢。
第四、遇到一个小bug,Spark在写Hive表的时候它会先把数据写到一个临时目录里,通过挪文件的方式把所有的数据挪回Hive表里,但是它会留下大量的临时目录没有清。
还有一个就是Phoenix在遇到多表union的时候速度变慢,以及逐条写HBase的方案会比较慢。
最后就是count distinct的数量太大,count distinct是sql的语法,它的问题是当数量过多的时候,就会在client端造成很大的压力,比如说对于我们来说,就是count distinct user,user就是一个用户,我们需要知道昨天有10万人,今天有10万人,这两个10万人之间可能有5万人重复,我们要知道这两个10万人加起来一共是多少distinct的数量,所以就需要把所有的20万人都拿到client端进行过滤。假如10万级别的话可能还没有问题,但当我们的用户量达到百万、千万级别的时候就会大大的影响查询的性能。
问题1:Kafka消息重复消费
首先Kafka重复消费的问题。
我们目前使用的是Spark的Kafka Direct API,Direct API不维护offset,所以我们选择在zookeeper自己维护,这样的话如果想重复消费的时候我们只需要找到对应时间点的offset,然后从这个offset重跑就可以了。
目前有很多其他的公司,会定期的维护一个offset到时间的映射,然后当他们需要找到某个时间的时候他到这个映射表里去反查。我们的消息虽然不是严格时序的,但它都是接近时序的,可能两个消息之间最多差一二十秒,所以我们可能通过近似二分法来从Kafka里找到对应的时间点的offset。
同时我们使用Kafka的partition加offset作为这个消息的唯一ID,这样的话在生成一个消息的时候,我们的ID就不会重复,即使你重跑很多次,HBase会自动把它去重。
问题2:Streaming业务逻辑较多,难以维护
第二就是我们的业务逻辑过多,我们把DStream全部映射成DataFrame,然后通过抽象,把我们的业务逻辑抽象成两种,一种是Operation,一种是Pipeline,一个Operation就是对DataFrame进行一个操作,然后把所有的Operation排列起来就是一个Pipeline。比如说我们可能从DStream过来之后,把它映射成DataFrame,第一步要解析IP,解析IP的操作就是把这个DataFrame的IP拿出来,解析完之后可能生成国家、城市、地区,然后把它重新塞到DataFrame里面。

第二个Operation比如说我们需要知道北京的用户是多少,就在这个Pipeline里面加一个Filter,城市等于北京。之后我们可能需要把分析出来的数据给存下来,比如说我们要存到北京的这张用户表里,我们同时要存到中国这张用户表里,所以它的输出可能是多个输出,为了解决这种多个输出问题我们会自动在Pipeline分支的地方加上persist和unpersist的过程,减少重复计算。
同时我们支持把Pipeline定义成一个可插拔的配置文件,现在要开发一个新的业务逻辑的话首先就要重写一个Operation类,定义你的操作类型,输入和输出,大部分可能是里面写了udf,之后要把Opeartion写到你认为正确的流程定义里面,这样的话Spark Streaming就会从正确的流程开始,并且继承之前的逻辑。
问题3:同时运行任务过多,任务调度变慢
同时运行过多的情况,我们第一个反应就是增加driver内存,使用更好性能的机器,但发现这个会有一点点提升,但是提升不大,后来我们发现Spark在在查找cache data的时候,需要解析Logical Plan,当我们在内存里存里几百张表的时候,每张表可能都很小,但每张表都对应了一个Logical Plan。当我需要某一个cache数据的时候它会把这个Logical Plan跟所有的内存表里的Logical Plan重新比对一下,它比对的时候会重新解析一个这个Logical Plan,所以你每次比对都要解析一两百个Logical Plan。这种情况在你的cache data越来越多的时候,会越来越慢,所以我们修改了相关代码,把这个解析Logical Plan改成只执行一次。
问题4:Spark写Hive表时,临时目录未清理
Spark写Hive表的时候临时目录没有清理,我们就修改了一下,加了两行代码,在结束之后把这种临时目录直接删掉就可以了,这是一个很小的修改。
问题5:Phoenix查询遇到多表union时速度过慢
还有就是Phoenix union的问题,比如说我要查三月份、四月份、五月份数据的时候,我其实就需要这三个union,但Phoenix在union的时候有一个问题,就是说它是串行执行的,它需要先去查三月份的数据,结束之后查四月份的数据,结束之后再查五月份的数据。
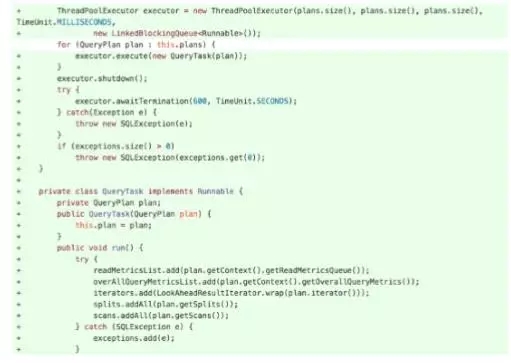
这样的话就很慢,所以我们改成并行,这样它会同时执行三四五月的数据,然后把所有的数据并行的拿回来。这样会大大加快我们union的速度。
问题6:逐条写HBase太慢
下一个问题就是写HBase太慢的问题。因为我们一天要写几千万行、上亿上数据,HBase带宽有很大压力,另外要重复的进行compact。HBase提供了Bulkload的方法,但它提供的是MapReduce的版本,Bulkload的方法就是把所需要的数据提前整理好,整理成HFile,然后一次性通过挪文件的方式挪到HBase里面,这样就大大减轻了HBase的压力。
我们基于MapReduce版的方法写了Spark版的。归功于Spark的优化能力,我们发现Spark版的会比MapReduce要快五倍,大大减少了HBase的压力。
同时我们会把那些需要重复计算的数据临时存在HDFS上,比如说今天统计了一点、两点、三点、四点的数据,但可能晚上统计的时候需要一点到二十四点的数据全部统计下来,所以我们不需要反复的去读HBase,因为HBase单条查是很快的,但如果你要查大量的数据的话,压力非常大,所以我们就会把这些需要重复利用的数据存入临时表,这样的话可以直接从临时表里出所需要的统计数据。
问题7:count distinct数量太大
还有count distinct过多的问题,有两种方案。
一种方案是BitMap的方式。我们可以把每个人进行一个编号,分配一个唯一的ID,把所有出现的ID存成一个BitMap,这样的话就可以把一个人压成一个bit。这样count distinct操作就能转换成对应的BitMap的操作。
比如说昨天和今天的人,其实就是两个BitMap或操作,再比如查昨天并且是北京的用户,那就需要把昨天的用户拿出来,把北京的用户拿出来,做一下BitMap与操作,这样就出了昨天北京的用户。同时,当出现人特别稀疏的时候,比如说很多人昨天来了,今天没来,今天出现了大量的空位。因为ID分配好了,所以我们采用了压缩的方法,就是把这些不需要的零或者一的位置全部压缩一下。
还有一种方案是Hyperloglog的方案。它的优点就是说不需要编号,占用空间也小,像Redis的话也提供Hyperloglog的方法,一个Hyperloglog可能就需要十几K的存储空间,它的误差跟你所使用的寄存器的数量有关,Redis中误差率小于1%。
但它不是一个精确的方案,它还有一个缺点就是说它只能做并集不能做交集,你可以把昨天的用户和今天的用户拿出来,merge一下就是这两天的总数,但你不能把昨天的用户和北京的用户做一下交集的操作。像Spark的话它在2.0的时候,它的window操作里面的也会启用这种方案。
我们目前离线计算会用BitMap的方法,它的优点是很准确,支持各种操作,我们实时计算用的是Hyperloglog方案,虽然会有误差,但实时计算误差小于1%的话其实是可以接受的。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。