
大讨论:Spark能否成为Hadoop的替代者
Spark火了。在国外 Yahoo!、Twitter、Intel、Amazon、Cloudera 等公司率先应用并推广 Spark 技术,Spark能否成为Hadoop的替代者呢?为什么?它们有哪些相似点与区别?...
Spark火了。在国外 Yahoo!、Twitter、Intel、Amazon、Cloudera 等公司率先应用并推广 Spark 技术,Spark能否成为Hadoop的替代者呢?为什么?它们有哪些相似点与区别?...
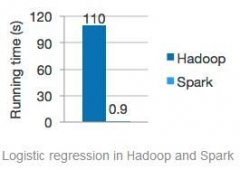
基于Hadoop就需要分别构建实时流处理团队、数据统计分析团队、数据挖掘团队等,而且这些团队之间无论是代码还是经验都不可相互借鉴,会形成巨大的成本,而使用Spark就不存在这个问题。...

配置hive+mysqlt的详细方法和步骤介绍,首先配置hive+mysqlt配置文件:Hive配置文件介绍•hive-site.xml hive的配置文件•hive-env.sh hive的运行环境文件•hive-default.xml.template 默认模板。...

Hadoop太复杂了,国内基本上没有什么人可以搞定。作为一种开源平台,获取Hadoop很容易,但驾驭Hadoop就比较难了,特别对于传统行业/企业而言。...

hadoop dfs 常用命令行:* 文件操作* 查看目录文件* $ hadoop dfs -ls /user/cl** 创建文件目录* $ hadoop dfs -mkdir /user/cl/temp** 删除文件* $ hadoop dfs -rm /us...

EMC公司和Pivotal发布数据湖Hadoop2.0包,包括EMC的数据计算设备(DCA),这是一个高性能的大数据计算设备,可大幅简化部署以及扩展基于Hadoop的高级分析计算。...

Facebook发布了新的开源项目 WebScaleSQL。WebScaleSQL是人气数据库MySQL的一个分支,已获Google、LinkedIn及Twitter等大型互联网公司的支持。WebScaleSQL包含了该公司大量的MySQL运营经验,同时也有许多来自其他公司的贡献。...

国内大数据技术服务商百分点公司已将机器学习的相关技术应用到大数据分析中,在百分点合作的某一团购网站,我们选取了10个基于商品和用户的特征属性,结合机器学习中的分类算法,构建了一个基于用户推荐的分类器。...
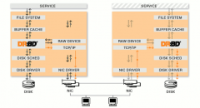
hadoop-0.20.2没有提供name node的备份,只是提供了一个secondary node,采用drbd实现共享存储,采用heartbeat实现心跳监控,所有服务器都配有双网卡,其中一个网卡专门用于建立心跳网络连接。...

hive 是Hadoop中最常用的工具,可以说是必装工具,按apache官方文档,推荐使用svn下载后编译,推荐使用tar.gz包,直接安装,很简单搞定hadoop hive的安装。...

Hadoop被公认是一套行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力(Gartner)。几乎所有主流厂商都围绕Hadoop开发工具、开源软件、商业化工具和技术服务。今年大型IT公司,如EMC、Microsoft、Intel、Teradata、Cisco都明显增加了Hadoop方面的投入。...
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,坦白说HDFS是一个不错的分布式文件系统,它有很多的优点,但也存在有一些缺点,包括:不适合低延迟数据访问、无法高效海量存储等。...

hadoop 在win系统中的eclipse开发测试问题及解决汇集,分享 hadoop 在win系统中的eclipse开发中遇到的各种错误代码及相关解决方法和命令行。...
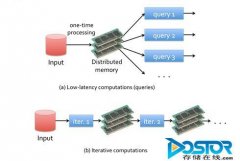
Spark内存计算框架适合各种迭代算法和交互式数据分析,能够提升大数据处理的实时性和准确性。“Spark记录着数据产生的每一个操作,能够可靠地将这些数据存储在内存之中,这使得它非常适用于第掩饰的计算和有效的迭代算法。”Cloudera表示。...

从Oracle到Hadoop,阿里云解决了海量数据如何存储和分析的问题,阿里的数据业务不再受制于规模的瓶颈;从Hadoop到ODPS,更是一次质的飞跃,为后续大数据业务的开展扫清了障碍。...

本文将介绍3个Scala Spark编程实例,分别是WordCount、TopK和SparkJoin,分别代表了Spark的三种典型应用。...

将Spark部署到Hadoop 2.2.0上需要经过以下几步:步骤1:准备基础软件,步骤2:下载编译spark 0.8.1或者更高版本,步骤3:运行Spark实例。...

开源大数据Hadoop社区内专注于可用性和数据安全优化的MapR最新筹集了1.1亿美元资金。有8000万美元是通过股权融资的方式筹得的,由谷歌(微博)旗下风投公司谷歌资本(Google Capital)领投。...

想在大数据的海洋中遨游,您首先需要一艘高性能存储旗舰,帮您征服非结构化数据的巨浪。EMC Isilon横向存储系统,以及强大的操作系统OneFS 7.0将 其可扩展性、管理简便性以及安全性推上了一个新台阶。...

摘要:介绍Hadoop全分布模式操作,实现真正意义上的集群架构。关键词:Hadoop 全分布模式 文件配置利用Hadoop解决大数据问题时,我们是用全分布模式来操作Hadoop。如何基于全分布模式来操作Hadoop,构建Hadoop集群呢?具体步骤...
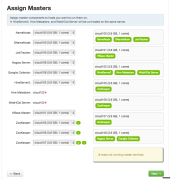
前言做大数据相关的后端开发工作一年多来,随着Hadoop社区的不断发展,也在不断尝试新的东西,本文着重来讲解下Ambari,这个新的Apache的项目,旨在让大家能够方便快速的配置和部署Hadoop生态圈相关的组件的环境,并提供维护和监控的功能.作为新...

【《网络世界》专稿】自从今年3月英特尔宣布以7.4亿美元收购大数据[注]软件解决方案提供商Cloudera的18%股份之后,一系列问题随之而来:例如,两家公司都有各自的Apache Hadoop发行版,两种产品与服务如何整合?原有Apache Hadoop...
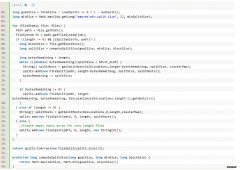
很多文档中描述,Mapper的数量在默认情况下不可直接控制干预,因为Mapper的数量由输入的大小和个数决定。在默认情况下,最终input占据了多少block,就应该启动多少个Mapper。如果输入的文件数量巨大,但是每个文件的size都小于HDFS的bloc...

接触Hadoop也快两年了,也一直没自己总结过安装教程,最近又要用hadoop,需要自己搭建一个集群来进行试验,所以就利用这个机会来写个教程以备以后自己使用,也用来和大家一起探讨。要安装Hadoop先安装其辅助环境 javaUbuntu下java的安装与配置将...
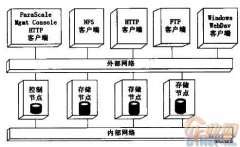
云计算(Cloud Computing)是一种基于因特网的超级计算模式,在远程的数据中心里,成千上万台电脑和服务器连接成一片电脑云。用户通过电脑、笔记本、手机等方式接人数据中心,按自己的需求进行运算。目前,对于云计算仍没有普遍一致的定义。结合上述定义,可以...