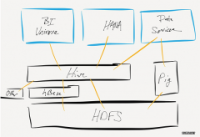
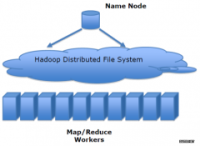
hadoop dfs 常用命令行:* 文件操作* 查看目录文件* $ hadoop dfs -ls /user/cl** 创建文件目录* $ hadoop dfs -mkdir /user/cl/temp** 删除文件* $ hadoop dfs -rm /us
* 文件操作
* 查看目录文件
* $ hadoop dfs -ls /user/cl
*
* 创建文件目录
* $ hadoop dfs -mkdir /user/cl/temp
*
* 删除文件
* $ hadoop dfs -rm /user/cl/temp/a.txt
*
* 删除目录与目录下所有文件
* $ hadoop dfs -rmr /user/cl/temp
*
* 上传文件
* 上传一个本机/home/cl/local.txt到hdfs中/user/cl/temp目录下
* $ hadoop dfs -put /home/cl/local.txt /user/cl/temp
*
* 下载文件
* 下载hdfs中/user/cl/temp目录下的hdfs.txt文件到本机/home/cl/中
* $ hadoop dfs -get /user/cl/temp/hdfs.txt /home/cl
*
* 查看文件
* $ hadoop dfs –cat /home/cl/hdfs.txt
*
* Job操作
* 提交MapReduce Job, Hadoop所有的MapReduce Job都是一个jar包
* $ hadoop jar <local-jar-file> <java-class> <hdfs-input-file> <hdfs-output-dir>
* $ hadoop jar sandbox-mapred-0.0.20.jar sandbox.mapred.WordCountJob /user/cl/input.dat /user/cl/outputdir
*
* 杀死某个正在运行的Job
* 假设Job_Id为:job_201207121738_0001
* $ hadoop job -kill job_201207121738_0001
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。