如何实现双倍提升Apache Spark排序性能
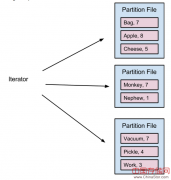 在本文中,我们将会逐层解析——介绍目前Spark shuffle的运作实现模式,提出修改建议,并对性能的提高方式进行分析。更多的工作进展可以于正在进行中的SPARK-2926发现...
在本文中,我们将会逐层解析——介绍目前Spark shuffle的运作实现模式,提出修改建议,并对性能的提高方式进行分析。更多的工作进展可以于正在进行中的SPARK-2926发现...
在本文中,我们将会逐层解析——介绍目前Spark shuffle的运作实现模式,提出修改建议,并对性能的提高方式进行分析。更多的工作进展可以于正在进行中的SPARK-2926发现...
 在Spark1.2中,通过与AMPLab(UCBerkeley)合作,一个pipelineAPI被添加到MLlib,再次简化了MLlib的建立工作,并添加了针对MLpipelines的调优机制。...
在Spark1.2中,通过与AMPLab(UCBerkeley)合作,一个pipelineAPI被添加到MLlib,再次简化了MLlib的建立工作,并添加了针对MLpipelines的调优机制。...
 越来越多的设备使用无线传感器,这要求工程师通过像Matlab这类的软件做出HTTP请求,如GET、POST等,在这里可以通过使用cURL、urlread实现简单的HTTP操作。当然如若想使...
越来越多的设备使用无线传感器,这要求工程师通过像Matlab这类的软件做出HTTP请求,如GET、POST等,在这里可以通过使用cURL、urlread实现简单的HTTP操作。当然如若想使...
Spark火了。在国外 Yahoo!、Twitter、Intel、Amazon、Cloudera 等公司率先应用并推广 Spark 技术,Spark能否成为Hadoop的替代者呢?为什么?它们有哪些相似点与区别?...
 基于Hadoop就需要分别构建实时流处理团队、数据统计分析团队、数据挖掘团队等,而且这些团队之间无论是代码还是经验都不可相互借鉴,会形成巨大的成本,而使用Spark就...
基于Hadoop就需要分别构建实时流处理团队、数据统计分析团队、数据挖掘团队等,而且这些团队之间无论是代码还是经验都不可相互借鉴,会形成巨大的成本,而使用Spark就...
 在“基于Spark软件栈的下一代大数据分析”演讲之后,我们采访了英特尔大数据首席架构师戴金权。深入了解了Spark应用场景、技术制约和未来发展方向,解读了“Spark是H...
在“基于Spark软件栈的下一代大数据分析”演讲之后,我们采访了英特尔大数据首席架构师戴金权。深入了解了Spark应用场景、技术制约和未来发展方向,解读了“Spark是H...
 BDTC2014大数据技术论坛上,百度大数据部副总监薛正华和中国移动集团公司业务支撑系统部项目经理何鸿凌共同主持了上午的论坛。涵盖数据库压缩技术、Spark、12306系...
BDTC2014大数据技术论坛上,百度大数据部副总监薛正华和中国移动集团公司业务支撑系统部项目经理何鸿凌共同主持了上午的论坛。涵盖数据库压缩技术、Spark、12306系...
 2014中国大数据技术大会14日下午大数据基础设施论坛上,来自存储、计算、架构的技术专家分别发表演讲,分享了他们在大数据领域中的技术应用与实践。...
2014中国大数据技术大会14日下午大数据基础设施论坛上,来自存储、计算、架构的技术专家分别发表演讲,分享了他们在大数据领域中的技术应用与实践。...
 2014中国大数据技术大会第二日上午大数据生态系统论坛上,ApacheSparkPMC成员孟祥瑞、ApacheHadoop和Tez项目PMC成员BikasSaha、美国俄亥俄州立大学鲁小亿、华为徐...
2014中国大数据技术大会第二日上午大数据生态系统论坛上,ApacheSparkPMC成员孟祥瑞、ApacheHadoop和Tez项目PMC成员BikasSaha、美国俄亥俄州立大学鲁小亿、华为徐...
 BDTC2014中国大数据技术大会首日全体大会上,卡耐基梅隆大学教授、ICML2014程序主席邢波带来了名为“ANewPlatformforCloud-basedDistributedMachineLearningonBigD...
BDTC2014中国大数据技术大会首日全体大会上,卡耐基梅隆大学教授、ICML2014程序主席邢波带来了名为“ANewPlatformforCloud-basedDistributedMachineLearningonBigD...
 虽然Spark活跃在Cloudera、MapR、Hortonworks等众多知名大数据公司,但是如果Spark本身的缺陷得不到及时处理,将会严重影响Spark的普及和发展。...
虽然Spark活跃在Cloudera、MapR、Hortonworks等众多知名大数据公司,但是如果Spark本身的缺陷得不到及时处理,将会严重影响Spark的普及和发展。...
 随着数据暴增,单服务器开始疲于应对海量用户的访问。自本期《问底》,徐汉彬将带大家开启异地跨集群分布式系统打造,本次关注的重点则是架构从单机到分布式集群的转变...
随着数据暴增,单服务器开始疲于应对海量用户的访问。自本期《问底》,徐汉彬将带大家开启异地跨集群分布式系统打造,本次关注的重点则是架构从单机到分布式集群的转变...
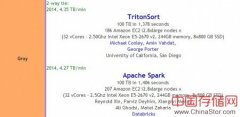 最新消息,Databricks的Spark与UCSD的TritonSort两个系统在2014DaytonaGraySort比赛上并列第一。为了对比赛有更好的了解,笔者特采访了Databricks辛湜(ReynoldXin),并就...
最新消息,Databricks的Spark与UCSD的TritonSort两个系统在2014DaytonaGraySort比赛上并列第一。为了对比赛有更好的了解,笔者特采访了Databricks辛湜(ReynoldXin),并就...
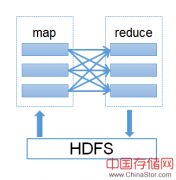 这篇文章将介绍基于物品的协同过滤推荐算法案例在TDWSpark与MapReudce上的实现对比,相比于MapReduce,TDWSpark执行时间减少了66%,计算成本降低了40%。...
这篇文章将介绍基于物品的协同过滤推荐算法案例在TDWSpark与MapReudce上的实现对比,相比于MapReduce,TDWSpark执行时间减少了66%,计算成本降低了40%。...
这篇文章将介绍腾讯TDW使用千台规模的Spark集群来对千亿量级的节点对进行相似度计算这个案例,通过实验对比,我们优化后的性能是MapReduce的6倍以上,是GraphX的2倍以...
Amazon EMR对于Spark来说一点都不陌生,事实上,客户通过在Amazon EMR运行Spark来管理Hadoop集群很久了。为了能够让客户更加方便的在Amazon EMR集群上运行Spark,亚马...
为了方便更多国内开发者深入了解Spark技术,CSDNCODE计划组织人员翻译一系列Spark相关技术文档。我们首先推荐的是Spark主要开发者MateiZaharia的博士论文。...
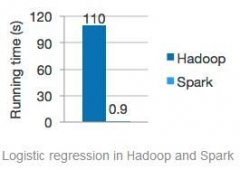
 据测试结果得知,在使用了206个EC2节点的情况下,Spark将排序用时缩短到了23分钟。这意味着在使用十分之一计算资源的情况下,相同数据的排序上,Spark比MapReduce快3倍!...
据测试结果得知,在使用了206个EC2节点的情况下,Spark将排序用时缩短到了23分钟。这意味着在使用十分之一计算资源的情况下,相同数据的排序上,Spark比MapReduce快3倍!...




