Intel李锐:Hive on Spark解析
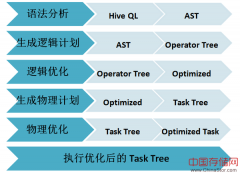 Hive是基于Hadoop平台的数据仓库,已经成为Hadoop事实上的SQL引擎标准。相较于Impala、Shark等,Hive拥有更为广泛的用户基础以及对SQL语法更全面的支持。这里,将走进H...
Hive是基于Hadoop平台的数据仓库,已经成为Hadoop事实上的SQL引擎标准。相较于Impala、Shark等,Hive拥有更为广泛的用户基础以及对SQL语法更全面的支持。这里,将走进H...
Hive是基于Hadoop平台的数据仓库,已经成为Hadoop事实上的SQL引擎标准。相较于Impala、Shark等,Hive拥有更为广泛的用户基础以及对SQL语法更全面的支持。这里,将走进H...
 在实际生产环境,百度运行着1300台规模的单集群(包含数万核心和上百TB内存),公司内部同时还运行着大量的小型Spark集群。2015Spark技术峰会上,马小龙将分享Spark在百度...
在实际生产环境,百度运行着1300台规模的单集群(包含数万核心和上百TB内存),公司内部同时还运行着大量的小型Spark集群。2015Spark技术峰会上,马小龙将分享Spark在百度...
关于spark的三个常见疑问解惑,如果以前没有部署过其它的大数据集群,集群中的计算框架只有Spark,建议直接使用Standalone,如果集群中在运行Spark计算平台的同时还运行...
借助GraphX强大的图计算能力,在小时级别内完成对TB数量级的图数据挖掘已经不是什么难事。但是随着互联网电子商务的快速发展,各种各样的图场景应运而生,从而对图的计...
 王联辉表示,早在2013年腾讯就开始使用Spark实现了广告模型的实时训练和更新,在2014年更将原有涉及迭代计算、图计算、DAG-MapReduce和HiveSQL等多种计算任务利用Spa...
王联辉表示,早在2013年腾讯就开始使用Spark实现了广告模型的实时训练和更新,在2014年更将原有涉及迭代计算、图计算、DAG-MapReduce和HiveSQL等多种计算任务利用Spa...
 过去一年,Spark从开源到火爆,展现了其成为通用大数据平台的潜质。本期封面报道“Spark新特性,新实战”内容涵盖SparkSQL、SparkMLlib、Tachyon、HiveonSpark多项技术...
过去一年,Spark从开源到火爆,展现了其成为通用大数据平台的潜质。本期封面报道“Spark新特性,新实战”内容涵盖SparkSQL、SparkMLlib、Tachyon、HiveonSpark多项技术...
 在2015年4月16-18日,一场由CSDN打造的技术盛宴OpenCloud2015将正式对外开放,汇聚近40名国内外大牛讲师,为业界梳理云计算与大数据的技术创新与应用实践。大会前夕,CSD...
在2015年4月16-18日,一场由CSDN打造的技术盛宴OpenCloud2015将正式对外开放,汇聚近40名国内外大牛讲师,为业界梳理云计算与大数据的技术创新与应用实践。大会前夕,CSD...
 Databricks、微软、Intel、百度、阿里、腾讯、小米、亚信都来了,你在哪里?2015Spark峰会最后一场议题已被保留,你想听谁讲、讲什么、亦或是自己讲?...
Databricks、微软、Intel、百度、阿里、腾讯、小米、亚信都来了,你在哪里?2015Spark峰会最后一场议题已被保留,你想听谁讲、讲什么、亦或是自己讲?...
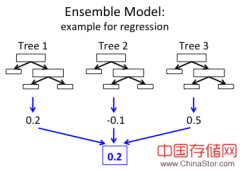 这篇文章介绍了RandomForests和Gradient-BoostedTrees(GBTs)算法和他们在MLlib中的分布式实现,以及展示一些简单的例子并建议该从何处上手。...
这篇文章介绍了RandomForests和Gradient-BoostedTrees(GBTs)算法和他们在MLlib中的分布式实现,以及展示一些简单的例子并建议该从何处上手。...
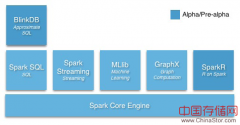 自2014年3月份跻身Apache顶级项目(TLP),Spark已然成为ASF最活跃的项目之一,得到了业内广泛的支持——2014年12月发布的Spark1.2版本包含了来自172位Contributor贡献的...
自2014年3月份跻身Apache顶级项目(TLP),Spark已然成为ASF最活跃的项目之一,得到了业内广泛的支持——2014年12月发布的Spark1.2版本包含了来自172位Contributor贡献的...
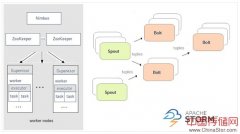 本文将对对Storm、Spark和Samza等三种Apache框架分别进行简单介绍,然后尝试快速、高度概述其异同。这三种框架在处理连续性的大量实时数据时的表现均出色而高效,那...
本文将对对Storm、Spark和Samza等三种Apache框架分别进行简单介绍,然后尝试快速、高度概述其异同。这三种框架在处理连续性的大量实时数据时的表现均出色而高效,那...
 OpenCloud2015将覆盖OpenStack、Spark、Container三大时下最热门的云计算大数据核心技术,荟萃国内外真正的云计算专家。懂技术的人都在这里!...
OpenCloud2015将覆盖OpenStack、Spark、Container三大时下最热门的云计算大数据核心技术,荟萃国内外真正的云计算专家。懂技术的人都在这里!...
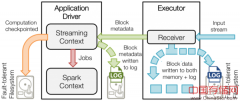 实时流处理系统必须要能在247时间内工作,因此它需要具备从各种系统故障中恢复过来的能力。最开始,SparkStreaming就支持从driver和worker故障恢复的能力。这篇文章...
实时流处理系统必须要能在247时间内工作,因此它需要具备从各种系统故障中恢复过来的能力。最开始,SparkStreaming就支持从driver和worker故障恢复的能力。这篇文章...
 自从Spark1.0版本的SparkSQL问世以来,它最常见的用途之一就是作为从Spark平台上面获取数据的一个渠道。到了Spark1.2版本,我们已经迈出了下一步,让Spark的原生资源和...
自从Spark1.0版本的SparkSQL问世以来,它最常见的用途之一就是作为从Spark平台上面获取数据的一个渠道。到了Spark1.2版本,我们已经迈出了下一步,让Spark的原生资源和...
Spark1.2.1发布,此版本是个维护版本,包括69位贡献者,修复了一些Spark的bug,包括核心API,Streaming,PySpark,SQL,GraphX和MLlib方面的。...
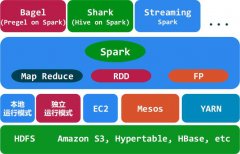 什么是Spark?Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点,Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。...
什么是Spark?Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点,Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。...
 在第九期“七牛开发者最佳实践日”上,陈超就Spark整个生态圈进行了讲解,而刘奇则分享豌豆荚在Redis上的摸索和实践。...
在第九期“七牛开发者最佳实践日”上,陈超就Spark整个生态圈进行了讲解,而刘奇则分享豌豆荚在Redis上的摸索和实践。...
 由CSDNCODE翻译社区组织的长篇论文翻译AnArchitectureforFastandGeneralDataProcessingonLargeClusters经过40余名译者的努力终于全部翻译完成。...
由CSDNCODE翻译社区组织的长篇论文翻译AnArchitectureforFastandGeneralDataProcessingonLargeClusters经过40余名译者的努力终于全部翻译完成。...




