
Hadoop2.6.0运行mapreduce之推断(speculative)执行(上)
在mapreduce中设计了Speculator接口作为推断执行的统一规范,DefaultSpeculator作为一种服务在实现了Speculator的同时继承了AbstractService,DefaultSpeculator是mapreduce的默认实现。...
在mapreduce中设计了Speculator接口作为推断执行的统一规范,DefaultSpeculator作为一种服务在实现了Speculator的同时继承了AbstractService,DefaultSpeculator是mapreduce的默认实现。...

在Mapreduce 的程序设计中,有时候会遇到多文件输出的使用,目前总结为两种方法:第一种方法:使用MultipleOutputFormat,第二种方式:使用MultipleOutputs。...
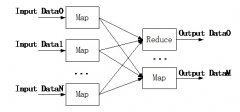
大数据处理模型MapReduce(接《大数据处理——Hadoop解析(一)》)大数据时代生产的数据最终是需要进行计算的,存储的目的也就是为了做大数据分析。通过计算、分析、挖掘数据背后的东西,才是大数据的意义所在。Hadoop不仅...
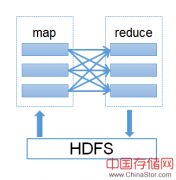
MapReduce在实现大数据处理上有着多个基础理论思想的支撑,虽然这些基础理论甚至实现方法都未必是MapReduce所创,但它们却由MapReduce采用独特的方式加以利用而重新大放光彩。MapReduce在大数据问题的处理上采用了与传统数据处理方式架构上几乎完全不同的解决方案....

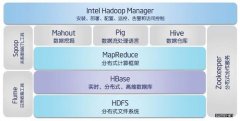
HDFS、MapReduce、Hbase、Hive是如何运行,以及基于Hadoop数据仓库的构建和分布式数据库内部具体实现。如有不足,后续及时修改。...

重谈下MapReduce框架中用户经常使用的一些接口或类的详细内容。了解这些会极大帮助你实现、配置和优化MR任务。当然javadoc中对每个class或接口都进行了更全面的陈述,这里只是一个指引教程。...
这篇文章将介绍基于物品的协同过滤推荐算法案例在TDWSpark与MapReudce上的实现对比,相比于MapReduce,TDWSpark执行时间减少了66%,计算成本降低了40%。...

据测试结果得知,在使用了206个EC2节点的情况下,Spark将排序用时缩短到了23分钟。这意味着在使用十分之一计算资源的情况下,相同数据的排序上,Spark比MapReduce快3倍!...

YARN本质上是Hadoop的新操作系统,突破了MapReduce框架的性能瓶颈。Murthy认为Hadoop和YARN的组合是企业大数据平台致胜的关键。...
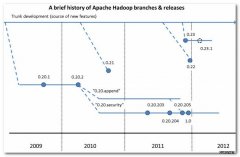
Cloudera Hadoop对应Apache Hadoop版本。(1) Apache Hadoop版本介绍Apache的开源项目开发流程 :-- 主干分支 : 新功能都是在 主干分支(trunk)上开发;-- 特性独有分支 : 很多新特性稳定性很差, 或者不完善, 在这些分支的独有特定很完善之后。...
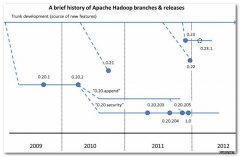
HDFS Federation:NameNode制约HDFS扩展,该功能让多个NameNode分管不同目录,实现访问隔离和横向扩展。。Hadoop版本和生态圈1. Hadoop版本(1) Apache Hadoop版本介绍Apache的开源项目开发流程:主干分支:新功能都是在主干分支(trunk)上开发。...
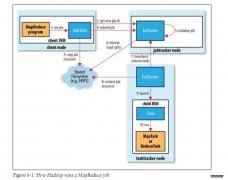
本文将分析Hadoop MapReduce(包括MRv1和MRv2)的两种常见的容错场景,第一种是,作业的某个任务阻塞了,长时间占用资源不释放,如何处理?另外一种是,作 业的Map Task全部运行完成后,在Reduce Task运行过程中,某个Map Tas...

过去两年,Hadoop社区对MapReduce做了很多改进,但关键的改进只停留在了代码层,Spark作为MapReduce的替代品,发展很快,其拥有来自25个国家超过一百个贡献者,社区非常活跃,未来可能取代MapReduce。...

MapReduce相关配置参数分为两部分,分别是JobHistory Server和应用程序参数,Job History可运行在一个独立节点上,而应用程序参数则可存放在mapred-site.xml中作为默认参数,也可以在提交应用程序时单独指定,注 意,如果用...
1.开发环境:Windows 2008 64bitJava 1.6.0_30MyEclipse 6.5环境部署见:http://www.linuxidc.com/Linux/2014-02/96528.htm2.Hadoop集群环境:O...
本文主要讲对key的排序,主要利用Hadoop的机制进行排序。1、Partitionpartition作用是将map的结果分发到多个Reduce上。当然多个reduce才能体现分布式的优势。2、思路由于每个partition内部是有序的,所以只...
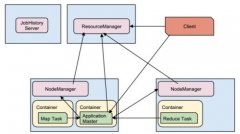
本文将分析Hadoop MapReduce(包括MRv1和MRv2)的两种常见的容错场景,第一种是,作业的某个任务阻塞了,长时间占用资源不释放,如何处理?另外一种是,作 业的Map Task全部运行完成后,在Reduce Task运行过程中,某个Map Tas...
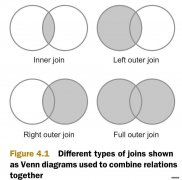
MapReduce的连接操作可以用于以下场景:用户的人口统计信息的聚合操作(例如:青少年和中年人的习惯差异)。当用户超过一定时间没有使用网站后,发邮件提醒他们。(这个一定时间的阈值是用户自己预定义的)分析用户的浏览习惯。让系统可以基于这个分析提示用...
对于业界的大数据存储及分布式处理系统来说,Hadoop 是耳熟能详的卓越开源分布式文件存储及处理框架,对于 Hadoop 框架的介绍在此不再累述,随着需求的发展,Yarn 框架浮出水面, @依然光荣复兴的 博客给我们做了很详细的介绍,读者通过本文中新旧 Had...

Hadoop被认为是运行在HDFS(分布式文件系统)上的MapReduce。通过YARN,Hadoop 2.0扩大了潜在应用的数量。Hadoop一直是各种或多或少整合了统一大数据架构的开源创新的统称。部分人认为,Hadoop的核心是一个分布式文件系统(HD...
我们的需求是想统计一个文件中用IK分词后每个词出现的次数,然后按照出现的次数降序排列。也就是高频词统计。由于hadoop在reduce之后就不能对结果做什么了,所以只能分为两个job完成,第一个job统计次数,第二个job对第一个job的结果排序。 第一个...

IDC:Hadoop MapReduce收入将迅猛增长 发布时间:2012.05.14 17:10来源:赛迪网作者:赛迪网来自IDC的最新研究显示,2011年全球Hadoop-MapReduce生态系统软件市场收入大约是7700万美元,预计2016年将增长至8...