最新消息,Databricks的Spark与UCSD的TritonSort两个系统在2014DaytonaGraySort比赛上并列第一。为了对比赛有更好的了解,笔者特采访了Databricks辛湜(ReynoldXin),并就Spark社区中的一些热门趋势进行探讨。
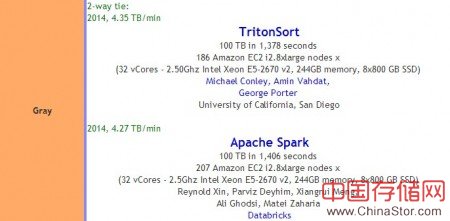
据Sort Benchmark最新消息,Databricks的Spark与加州大学圣地亚哥分校的TritonSort两个系统在2014 Daytona GraySort排序比赛上并列第一。其中,TritonSort是一个多年的学术项目,使用186个EC2 i2.8xlarge节点在1378秒内完成了100TB数据的排序;而Spark则是一个生产环境通用的大规模迭代式计算工具,它使用了207个EC2 i2.8xlarge节点在1406秒内排序了100TB的数据,在“前文”中我们曾详细介绍过。
为了更好的了解这次比赛始末,以及当下Spark社区中存在的一些热门问题,笔者特采访了Databricks的辛湜(Reynold Xin,@hashjoin)。(PS:感谢@徽沪一郎的技术支持)
以下为采访原文
CSDN:本次比赛的规则?考量的是哪些方面?
辛湜:这个比赛最早是由Jim Gray(对数据库领域做出了不可磨灭贡献的图灵奖得主)在八十年代提出的,测量计算机软件和硬件性能优化上的提升。这个比赛有多个不同的类别,其中最有挑战性的类别就是测量参赛系统在多快的时间内能排序一定量的数据。
最早始的时候Jim Gray制定的比赛规则要求参赛者排序100MB的数据,到了2001年数据量上升到了1TB。2007年Jim Gray出海航行失踪之后比赛由一个委员会负责举办。2009年为了纪念Jim Gray,将最有挑战的类别改名为了Daytona GraySort,并把数据量提升到了100TB。除此之外,这个类别还有很多苛刻的规则,比如说所有的排序输出必须在不同的节点上复制,使得储存数据能够容忍节点宕机,排序系统必须能够支持任意长度,且排序分布极端不均的数据。
大赛委员会非常认真,会对参赛系统和技术报告进行长达一个月的审核。详细规则可以参见大赛官方网页: http://sortbenchmark.org/FAQ-2014.html
这个比赛参赛系统一般都出自规模很大的公司(Microsoft、Yahoo和当年的Tandem、DEC)或者学术机构(UC Berkeley, UCSD加州大学圣地亚哥分校)。有不少的参赛者为了提高性能会专门为这个比赛特制一些硬件系统和软件系统。
CSDN:Spark以什么样的成绩获得了比赛的第一名?与其他参赛者对比如何?
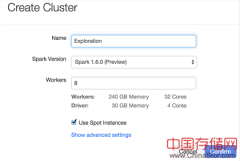
辛湜:我们基于Spark搭建的系统用了207台Amazon EC2上的虚拟机,在23分钟内排序了100TB的数据。去年的冠军Hadoop用了2100台Yahoo内置的机器,花了72分钟。相比之下,我们用了不到十分之一的机器,排序速度是Hadoop记录的三倍。值得注意的是这是比赛历史上第一次基于公有云的系统获得了第一。
大赛委员会曾告知参赛系统每年都非常多,但是因为这个大赛最终只会通告冠军,所以我们并不知道究竟有多少其他的参赛者。
今年有两个系统并列第一:Databricks的Spark和UCSD的Themis都花了23分钟左右的时间。Themis是一个多年的学术项目,专门研究如何高效的shuffle数据和排序,为此他们牺牲了很多通用系统需要的功能,比如说容错性等等。Spark作为一个通用系统,能够在一个排序比赛里面和UCSD的Themis并列第一是一件非常不容易的事情。一个有趣的事情:带领Themis团队的George Porter教授也是Berkeley毕业的博士,所以最后是两个Berkeley校友并列第一,呵呵。
CSDN:什么样的特性让Spark获得如此优异的成绩,是否可以从技术角度详细分析一下?
辛湜:这个成绩主要归于三点:我们前期对Spark工程上的投入,Spark的灵活性,以及我们团队自身对大规模系统优化的经验。
Databricks成立之后我们加大了对Spark工程系统上的投入,有不少的资源都用来提高shuffle的性能。谈到排序,其实最重要的一步就是shuffle,在提升shuffle方面最近有三个工作对这个比赛影响很大:
第一个是sort-based shuffle。这个功能大大的减少了超大规模作业在shuffle方面的内存占用量,使得我们可以用更多的内存去排序。第二个是新的基于Netty的网络模块取代了原有的NIO网络模块。这个新的模块提高了网络传输的性能,并且脱离JVM的GC自己管理内存,降低了GC频率。第三个是一个独立于Spark executor的external shuffle service。这样子executor在GC的时候其他节点还可以通过这个service来抓取shuffle数据,所以网络传输本身不受到GC的影响。
过去一些的参赛系统软件方面的处理都没有能力达到硬件的瓶颈,甚至对硬件的利用率还不到10%。而这次我们的参赛系统在map期间用满了3GB/s的硬盘带宽,达到了这些虚拟机上八块SSD的瓶颈,在reduce期间网络利用率到了1.1GB/s,接近物理极限。
准备这次比赛我们从头到尾用了不到三个礼拜的时间。这个和Spark本身架构设计的灵活使得我们可以很快的实现一些新的算法以及优化密切相关。
CSDN:关于SQL的支持。SQL on Spark是个老生长谈的问题,前一阶段终止Shark,并开启Spark SQL项目,可否具体谈谈原因?另外,Spark SQL的规划是什么?当下对SQL的支持如何?大家期待的SQL92或者以上的标准什么时候能得到满足?
辛湜:Shark对Hive的依赖性太强,而Hive自身设计比较糟糕,有大量传统遗留的代码,使得Shark在新功能上的更新非常缓慢。去年年中的时候Michael Armbrust(Spark SQL主要设计者)在Google内部设计F1的新一代的query optimizer。当时他有一个新的设计想法(Catalyst),我们和他交流之后感觉这个新的架构借鉴了过去三十年学术和工业界研究的成果,再加上了他自己新颖的诠释,和传统的架构相比更灵活,有很大架构上的优势。花了几个月时间我们终于说服了Michael加入Databricks,开始Spark SQL的开发。
Spark SQL现在可能是最大的Big Data SQL开源项目,虽然从开源到现在不到半年时间,已经有接近一百位代码贡献者。和Spark的灵活性一样,Spark SQL的架构让开源社区可以很快的迭代,贡献新的功能,很多类似SQL92的功能都有不少开源社区的贡献者感兴趣,应该都会很快得到实现。
CSDN:关于计算方面。运行Spark时,应用的中间结果会通过磁盘传递,势必会影响到性能,而业内李浩源的Tachyon可以剥离spark,并且对HDFS文件系统有很好的支持,在不更改用户使用情况下大幅度提高性能,当下也受到Intel、EMC等公司的支持,在Spark生态圈发展良好。那么Databricks对这方面的打算是什么?提供更原生的支持,或者是提升自己的?
辛湜:Spark的中间结果绝大多数时候都是从上游的operator直接传递给下游的operator,并不需要通过磁盘。Shuffle的中间结果会保存在磁盘上,但是随着我们对shuffle的优化,其实磁盘本身并不是瓶颈。这次参赛也验证了shuffle真正的瓶颈在于网络,而不是磁盘。
Tachyon印证了储存系统应该更好利用内存的大趋势。我预测未来越来越多的存储系统会有这方面的考虑和设计,Spark项目的原则就是能够更好的利用下层的储存系统,所以我们也会对这方面做出支持。
值得注意的是,把shuffle数据放入Tachyon或者HDFS cache(HDFS的新功能)其实不是一个好的优化模式。原因是shuffle每个数据块本身非常的小,而元数据量非常的多。直接把shuffle数据写入Tachyon或者HDFS这种分布式储存系统多半会直接击垮这些系统的元数据存储,反而导致性能下降。
CSDN:算法方面考虑。大数据的核心在数据建模和数据挖掘,那么对于算法玩家来说,对R等语言的支持无疑很有必要。而据我所知,当下Spark 1.1发行版还未包括SparkR,那么这方面的roadmap会是什么?
辛湜:SparkR是Spark生态系统走入传统data scientist圈很重要的一步。Databricks和Alteryx几个月前宣布合作开发SparkR。这个项目不在Spark自身主要是因为项目许可证(license)的问题。R的许可证和Apache 2.0冲突,所以SparkR短期内应该会以一个独立项目的形式存在。
CSDN:数据仓库互通。上面说到了数据的计算,那么数据的计算将存向何处?你们在工作中看到用户使用的常用数据仓库是什么?Cassandra还是其他?Spark更看好哪些数据仓库?更看好哪些NoSQL?是否已经有打通数据仓库的计划,提供一个更原生的支持,这里的趋势是什么?
辛湜:和对储存系统的态度一样,Spark本身不应该限制用户对数据库的使用。Spark的设计使得他可以很容易的支持不同的储存格式以及存储系统。我们希望对最热门的几个数据库,比如说Cassandra能够有原生的支持。
在Spark 1.2里面我们会开放一个新的储存接口(API),这个接口使得外界储存系统和数据库可以非常容易的连接到Spark SQL的SchemaRDD,并且在查询时候optimizer甚至可以直接把一些过滤的filter直接发送到实现这个接口的数据库里面,最大限度的利用这些数据库自身的过滤功能减少网络传输。
目前我们内部一些存储格式和系统的实现(比如说JSON、Avro)都已经转移到了这个新的接口。1.2虽然还没有发布,但是已经有很多社区成员开始了对不同数据库的实现。我预计未来绝大多数的数据库都会通过这个接口和Spark SQL集成起来,使得Spark SQL可以成为一个统一的查询层,甚至在一个查询语句里面利用多个不同数据库的数据。
免费订阅“CSDN云计算(左)和CSDN大数据(右)”微信公众号,实时掌握第一手云中消息,了解最新的大数据进展!

 CSDN发布虚拟化、Docker、OpenStack、CloudStack、数据中心等相关云计算资讯, 分享Hadoop、Spark、NoSQL/NewSQL、HBase、Impala、内存计算、流计算、机器学习和智能算法等相关大数据观点,提供云计算和大数据技术、平台、实践和产业信息等服务。
CSDN发布虚拟化、Docker、OpenStack、CloudStack、数据中心等相关云计算资讯, 分享Hadoop、Spark、NoSQL/NewSQL、HBase、Impala、内存计算、流计算、机器学习和智能算法等相关大数据观点,提供云计算和大数据技术、平台、实践和产业信息等服务。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。