我们决定重做一次性能测试,与之前帖子不同,这次的重心不是C*可扩展性,而是量化这些新实例的性能指标.Netflix公布Cassandra新性能:基于AWS的百万次写入每秒
在2011年11月发表的文章“ NetFlix测试Cassandra——每秒百万次写入”中我们展示了Cassandra (C*)如何在集群节点增加时实现性能线性增长。随着新型EC2实例类型的产生,我们决定重做一次性能测试,与之前帖子不同,这次的重心不是C*可扩展性,而是量化这些新实例的性能指标。下面是此次测试的详细信息及结果。
节点数量,软件版本及配置信息
C*集群
此次测试的C*集群运行于Datastax 3.2.5企业版,C*版本为1.2.15.1,共有285个节点。实例类型为i2.xlarge器,运行于Heap为12GB的JVM 1.7.40_b43之上。使用的OS为Ubuntu 12.04 LTS。数据与日志使用相同的EXT3格式挂载文件。
尽管上次测试使用了较高规格的m1.xlarge服务器,此次测试的吞吐量结果依然与上次持平,而且选择(支持SSD)i2.xlarge规格服务器更加贴近现实用例,能更好的展示其吞吐量与延迟。
完整的schema如下:
create keyspace Keyspace1
with placement_strategy = ‘NetworkTopologyStrategy’
and strategy_options = {us-east : 3
and durable_writes = true;
use Keyspace1;
create column family Standard1
with column_type = ‘Standard’
and comparator = ‘AsciiType’
and default_validation_class = ‘BytesType’
and key_validation_class = ‘BytesType’
and read_repair_chance = 0.1
and dclocal_read_repair_chance = 0.0
and populate_io_cache_on_flush = false
and gc_grace = 864000
and min_compaction_threshold = 999999
and max_compaction_threshold = 999999
and replicate_on_write = true
and compaction_strategy = ‘org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy’
and caching = ‘KEYS_ONLY’
and column_metadata = [
{column_name : 'C4',
validation_class : BytesType},
{column_name : 'C3',
validation_class : BytesType},
{column_name : 'C2',
validation_class : BytesType},
{column_name : 'C0',
validation_class : BytesType},
{column_name : 'C1',
validation_class : BytesType}]
and compression_options = {‘sstable_compression’ : ”};
请注意到这里的min_compaction_threshold和max_compaction_threshold值很高,尽管在实际产品中不可能使用完全一致的数据,但也能实际反映我们所想掌握的数据。
客户端
客户端应用程序使用Cassandra Stress,有60个客户端节点,实例类型为r3.xlarge,为之前m2.4xlarge规格实例数量的一半,价格也是之前的一半,但依然能够推动所需负载(使用线程低于40%)并达到与之前相同的吞吐量。客户端运行在基于Ubuntu 12.04 LTS系统的JVM 1.7.40_b43之上。
网络拓扑
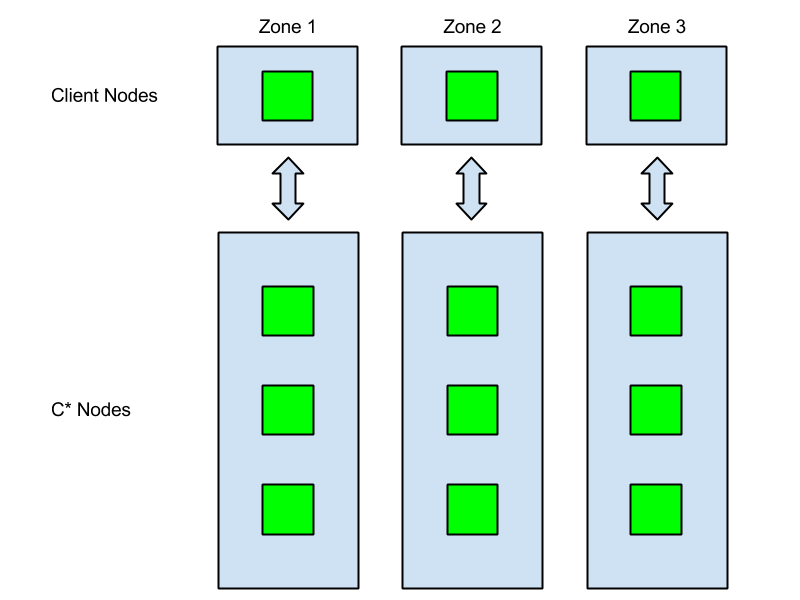
Netflix的Cassandra集群有3个副本,部署在3个不同的可用区域(Availability Zones,即AZ)。这样,如果其中一个AZ断电,余下的2个副本依然可以继续工作。
之前帖子里所有的客户端都部署同一个AZ中,这次的改变遵从实际产品都部署在三个不同AZ的真实应用场景。客户端请求一般交于相同AZ的C*节点,我们称之为zone-aware连接,这一特征被构建到Netflix C* Java客户端Astyanax中。Astyanax客户端通过查询记录信息向相应实例服务端发送读写请求。尽管C*协调器能够实现所有请求,但当实例不在副本集中的情况发生时,则需要一个额外的网络跃点,即token-aware请求。
此次测试使用Cassandra Stress,因此不需要token-aware请求。而通过一些简单的grep和awk-fu,我们可以得知此次测试属于zone-aware连接范畴,是网络拓扑结构里比较典型的实际产品案例。
延迟及吞吐量测量
我们已经文档化了使用Priam完成令牌任务、备份和存储的方法。Priam内部版本添加了一些额外功能,我们使用Priam协助收集C* JMX自动测量结果并发送到分析平台Atlas, 此功能将在未来几周添加至Priam 开源版本中。
以下是用于测量延迟与吞吐量的JMX属性:
延迟
- AVG & 95% ile协调延迟
- 读。StorageProxyMBean.getRecentReadLatencyHistogramMicros() 提供可计算AVG & 95%ile 的数组
- 写。StorageProxyMBean.getRecentWriteLatencyHistogramMicros()提供可计算AVG & 95%ile 的数组
吞吐量
- 协调器操作数量
- 读。StorageProxyMBean.getReadOperations()
- 写。StorageProxyMBean.getWriteOperations()
测试
我执行了以下4组测试:
- CL One全写入测试
- CL Quorum全写入测试
- CL One读写综合测试
- CL Quorum读写综合测
100%写入
与原帖测试不同,此次测试展示了持久性大于每秒100万次写入的用例。现实中只写入的应用程序很少,这种类型的应用要么是遥测系统要么是物联网应用,其相关测试数据被输入BI系统进行分析。
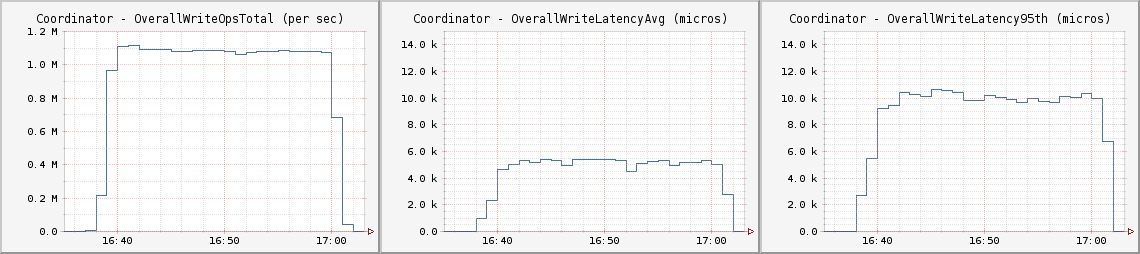
CL One
与原帖测试相似,此次测试运行在CL One上。其平均延迟略高于5毫秒,第95百分位为10毫秒
每个客户节点都运行如下Cassandra Stress命令:
cassandra-stress -d [list of C* IPs] -t 120 -r -p 7102 -n 1000000000 -k -f [path to log] -o INSERT
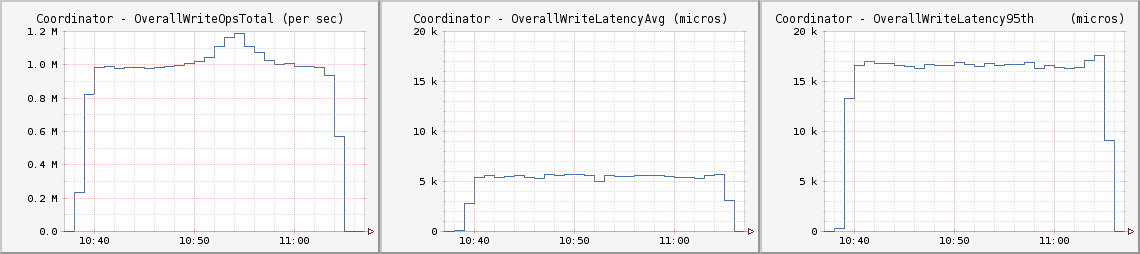
CL LOCAL_QUORUM
为了保证用例读入的高一致性,这次我们测试了运行于LOCAL_QUORUM CL上吞吐量大于每秒百万次写入的用例。每秒100万次写入吞吐量平均延迟低于6毫秒,第95百分位为17毫秒
每个客户节点都运行如下Cassandra Stress命令:
cassandra-stress -d [list of C* IPs] -t 120 -r -p 7102 -e LOCAL_QUORUM -n 1000000000 -k -f [path to log] -o INSERT
综合测试——10%写入90%读入
每秒100万次写入只是一个醒目的标题,大多数应用程序都是读写混合的。在对Netflix主要应用程序调研之后,我决定做一个10%写入90%读入的综合测试,这一混合测试占用总线程的10%用于写入90%用于读取。这虽然不是实际应用程序的真实复现,但也能很好的测量数据拥塞时集群吞吐量及延迟
CL One
使用CL One配备时,C*实现了最高的吞吐量及可用性,开发人员需要接受其结果的一致性,并模仿这一范例设计他们的应用程序。
- 写入吞吐量大于每秒20万次写入,平均延迟大约为1.25毫秒,第95%百分位为2.5毫秒。
- 读出吞吐量大约为每秒90万次读出,平均延迟2毫秒,第95%百分位为7.5毫秒。
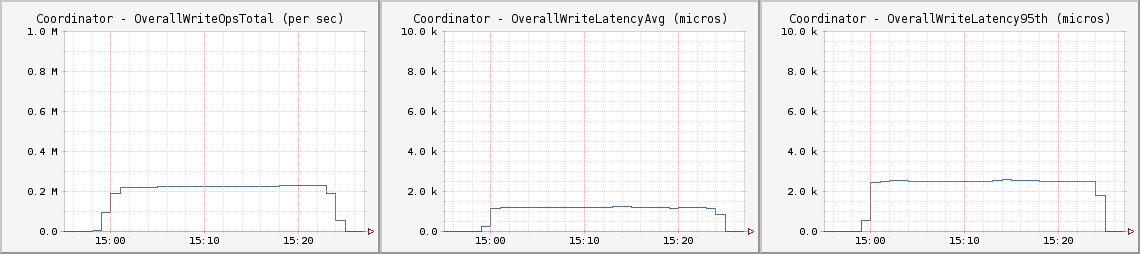

每个客户节点都运行如下Cassandra Stress命令:
cassandra-stress -d $cCassList -t 30 -r -p 7102 -e LOCAL_QUORUM -n 1000000000 -k -f /data/stressor/stressor.log -o INSERT<br>cassandra-stress -d $cCassList -t 270 -r -p 7102 -e LOCAL_QUORUM -n 1000000000 -k -f /data/stressor/stressor.log -o READ
CL LOCAL_QUORUM
大多数用C*开发的应用程序都将默认为CL Quorum读写,这为其相关开发人员进入分布式数据库系统提供了机会,也避免了解决应用程序最终一致性的难题。
- 写入吞吐量小于每秒20万次写入,平均延迟大约为1.75毫秒,第95%百分位为20毫秒。
- 读出吞吐量大约为每秒60万次读出,平均延迟3.4毫秒,第95%百分位为35毫秒。
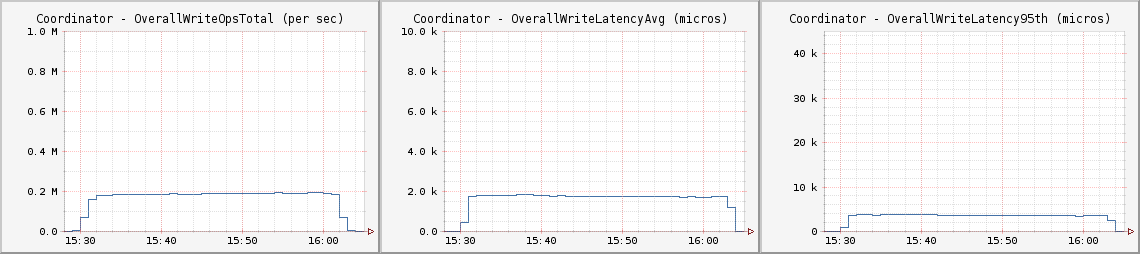
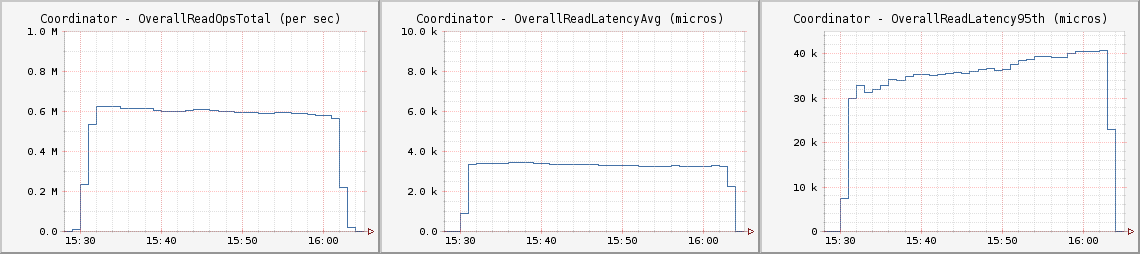
每个客户节点都运行如下Cassandra Stress命令:
cassandra-stress -d $cCassList -t 30 -r -p 7102 -e LOCAL_QUORUM -n 1000000000 -k -f [path to log] -o INSERT<br>cassandra-stress -d $cCassList -t 270 -r -p 7102 -e LOCAL_QUORUM -n 1000000000 -k -f [path to log] -o READ
费用
这次测试的总开销包括EC2实例费用和inter-zone网络流量费用,我使用Boundary监控C*网络使用情况。
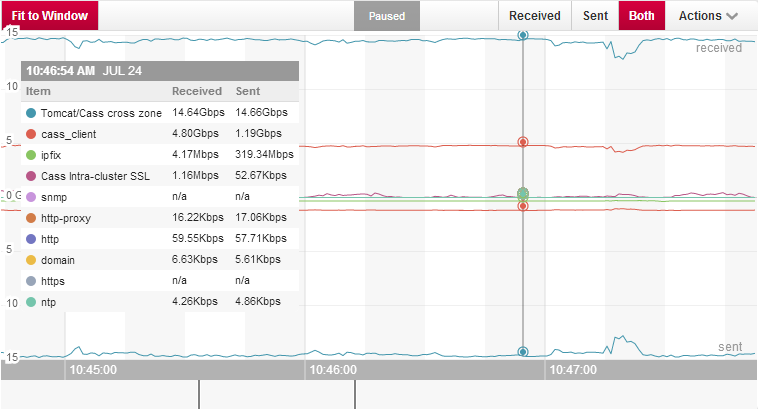
上图显示了可用服务区域间30Gbps的传输速度。
这里是执行每秒100万次写入测试的费用:
|
Instance Type / Item |
Cost per Minute |
Count |
Total Price per Minute |
|
|
i2.xlarge |
$0.0142 |
285 |
$4.047 |
|
|
r3.xlarge |
$0.0058 |
60 |
$0.348 |
|
|
Inter-zone traffic |
$0.01 per GB |
3.75 GBps * 60 = 225GB per minute |
$2.25 |
|
|
Total Cost per minute |
$6.645 |
|||
|
Total Cost per half Hour |
$199.35 |
|||
|
Total Cost per Hour |
$398.7 |
结语
大多数企业可能不需要处理这么多数据,这项测试很好的展示了新型AWS i2和r3实例类型的花费、延迟及吞吐量。每一个应用程序都是不一样的,你的情况也会不尽相同。
这次测试耗费了我一周的空闲时间,并不是一个详尽的性能研究,我也没有对C*系统或JVM作深入调研,你有可能会比我做的更好。如果你有兴趣研究大规模分布式数据库及性能提升,欢迎加入Netflix CDE组。
原文链接:Revisiting 1 Million Writes per second
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。