用于 Slurm 的全功能 Kubernetes 运算符,旨在优化现代机器学习 (ML) 和高性能计算 (HPC) 环境中的工作负载管理和编排。
2024 年 9 月 25 日 ,AI 基础设施公司 Nebius 宣布推出 Soperator 的开源版本,这是世界上第一个用于 Slurm 的全功能 Kubernetes 运算符,旨在优化现代机器学习 (ML) 和高性能计算 (HPC) 环境中的工作负载管理和编排。

Soperator 由 Nebius 开发,旨在将 Slurm(一种旨在管理大规模 HPC 集群的作业编排器)的强大功能与 Kubernetes 灵活且可扩展的容器编排相结合。在计算密集型环境中工作时,它可提供简单性和高效的作业调度,特别是对于 GPU 密集型工作负载,使其成为 ML 训练和分布式计算任务的理想选择。
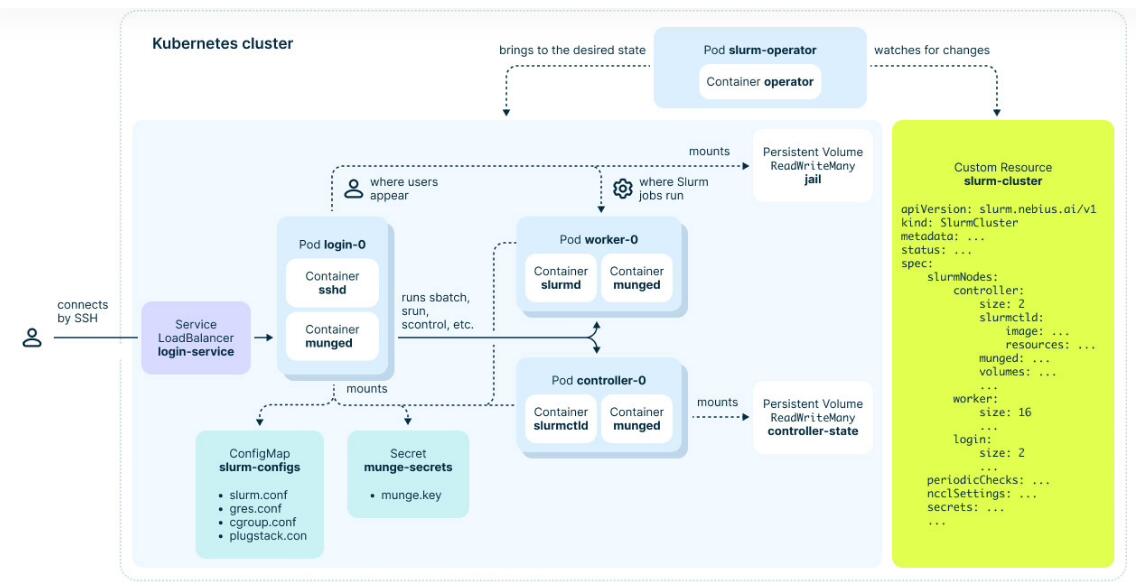 Soperator 的顶级架构
Soperator 的顶级架构
Nebius 云平台产品管理总监 Narek Tatevosyan 表示:“Nebius 正在通过应对我们知道的 AI 和 ML 专业人士面临的挑战,为 AI 时代重建云。目前市场上没有专门用于 GPU 密集型工作负载的工作负载编排产品。通过发布 Soperator 作为开源解决方案,我们的目标是将强大的新工具交到 ML 和 HPC 社区手中。
“我们坚信社区驱动的创新,我们的团队在开源创新产品方面有着良好的记录。我们很高兴看到这项技术将如何继续发展,并使 AI 专业人士能够专注于增强他们的模型和构建新产品。
Nebius 首席技术官 Danila Shtan 补充道:“通过开源 Soperator,我们不仅仅是发布一种工具——我们是在坚持我们对开源创新的承诺,在这个许多人保持其解决方案专有的行业中。我们正在推动对传统保守的 HPC 工作负载采用云原生方法,实现 GPU 密集型任务的工作负载编排现代化。这一战略举措反映了我们致力于促进社区协作和在全球范围内推进 AI 和 HPC 技术的决心。
Soperator 的主要功能包括:
增强的调度和编排:Soperator 在大型计算集群之间提供精确的工作负载分配,优化 GPU 资源使用并支持并行作业执行。这可以最大限度地减少空闲 GPU 容量,优化成本,并促进更高效的协作,使其成为从事大规模 ML 项目的团队的重要工具。 容错训练:Soperator 包括硬件健康检查机制,可监控 GPU 状态,在出现硬件问题时自动重新分配资源。即使在高度分布式的环境中,这也能提高训练稳定性,并减少完成任务所需的 GPU 小时数。 简化集群管理:通过跨所有集群节点共享根文件系统,Soperator 消除了在多节点安装之间保持相同状态的挑战。与 Terraform 操作员一起,这简化了用户体验,使 ML 团队能够专注于其核心任务,而无需广泛的 DevOps 专业知识。
未来计划的增强功能包括对安全性和稳定性、可扩展性和节点管理的改进,以及根据新兴软件和硬件更新进行升级。
从今天开始,Soperator 的第一个公开版本作为开源解决方案在 Nebius GitHub 上提供给所有 ML 和 HPC 专业人员,以及相关的部署工具和软件包。Nebius 还邀请任何想要尝试该解决方案的人,用于在多节点 GPU 安装上运行的 ML 训练或 HPC 计算;该公司的解决方案架构师随时准备在 Nebius 环境中的安装和部署过程中提供帮助和指导。
关于 Nebius
Nebius 是一家科技公司,致力于构建全栈基础设施,为全球 AI 行业的爆炸式增长提供服务,包括大规模 GPU 集群、云平台以及面向开发人员的工具和服务。该公司总部位于阿姆斯特丹并在纳斯达克上市,其研发中心遍布欧洲、北美和以色列。Nebius 的核心业务是一个以 AI 为中心的云平台,专为密集型 AI 工作负载而构建。凭借内部设计的专有云软件架构和硬件(包括服务器、机架和数据中心设计),Nebius 为 AI 构建者提供了构建、调整和运行模型所需的计算、存储、托管服务和工具。作为 NVIDIA 首选的云服务提供商,Nebius 提供针对 AI 训练和推理优化的高端基础设施。该公司拥有一支由 500 多名技术娴熟的工程师组成的团队,为 AI 构建者提供真正的超大规模云体验。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。