Hadoop开发者刊首语 2010年1月,《Hadoop开发者》沐着2010年的第一缕春光诞生了。正是有了DougCutting这样的大师级开源者,正是有了无数个为Hadoop贡献力量的开源者们的共同努力,才有了Hadoop自诞生时的倍受关注到现在。
在Hadoop集群学习与使用过程中经常遇见这样那样的小问题,这里为大家分享Hadoop集群设置中经常出现的一些问题,以下为译文:1.Hadoop集群可以运行的3个模式?单机(本地)模式伪分布式模式
在mac os上安装hadoop的文章不多,本文安装环境的操作系统是 MAC OS X 10.7 Lion,共分7步,注意第三个配置在OS X上最好进行配置,否则会报错“Unable to load realm info from SCDynamicStore”。
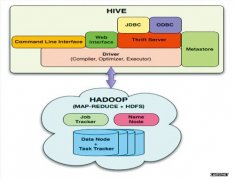
Pig可以非常方便的处理HDFS和HBase的数据,和Hive一样,Pig可以非常高效的处理其需要做的,通过直接操作Pig查询可以节省大量的劳动和时间。当你想在你的数据上做一些转换,并且不想编写MapReduce jobs就可以用Pig.

Hive在处理动态分区的时候,主要经历这么几个步骤tablescan->filesink->movetask,在进行filesink的时候是根据记录来处理的,会起N(part)个record writer然后开始处理动态分区字段,即这里的dt。
教你如何进行Hadoop + Hive + Map +reduce 集群安装部署:环境准备:CentOS 5.5 x64 (3台)10.129.8.52 (master) ======>> NameNode, SecondaryNameNode,JobTracker10.129.8.76。
配置hive+mysqlt的详细方法和步骤介绍,首先配置hive+mysqlt配置文件:Hive配置文件介绍•hive-site.xml hive的配置文件•hive-env.sh hive的运行环境文件•hive-default.xml.template 默认模板。
自动安装的Hadoop在/usr/local/Cellar/hadoop路径下。需要注意的是,在使用brew安装软件时,会自动检测安装包的依赖关系,并安装有依赖关系的包
以 Hadoop 作为后端的计算集群,计算得出来的数据如果要反向推到前面去,用什么方式存储更为恰当? 再放到 DB 里面的话,构建索引是麻烦事。
SAP特别设立了一个“大数据”合作伙伴理事会。该理事会致力于进行合作创新,研发基于SAP实时数据平台和Hadoop的新产品解决方案,探索新应用和架构
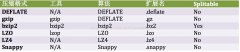
bzip2压缩比gzip更有效,但是速度更慢。bzip2的解压速度比它的压缩速度要快。但是和其他压缩格式比又是最慢的,但是压缩效果明显是最好的。snappy和lz4的解压速度比lzo好很多。
Hadoop故障排除:jps 报process information unavailable解决办法,jps时出现如下信息:4791 -- process information unavailable
在Hadoop中,调用文件系统(FS)Shell命令应使用 bin/hadoop fs