、默认项目名称为MapReduceTools,然后在项目MapReduceTools中新建lib目录,先将hadoop下的hadoop-core-1.0.4.jar重命名为hadoop.core.jar,并把hadoop.core.jar、及其lib目录下的commons-cli-1.2.jar、commons-lang-2.4.jar、commons-configuration-1.6.jar、jackson-m
重谈下MapReduce框架中用户经常使用的一些接口或类的详细内容。了解这些会极大帮助你实现、配置和优化MR任务。当然javadoc中对每个class或接口都进行了更全面的陈述,这里只是一个指引教程。
hadoop常见问题解决:WARN mapred.LocalJobRunner: job_local910166057_0001o
大数据新手入门hadoop的初步理解:hadoop的初步理解 1:hadoop到底是什么呢? hadoop是一个解决方案,是一个能够处理大数据量的的分布式处理系统。
hadoop dfs 常用命令行:* 文件操作* 查看目录文件* $ hadoop dfs -ls /user/cl** 创建文件目录* $ hadoop dfs -mkdir /user/cl/temp** 删除文件* $ hadoop dfs -rm /us
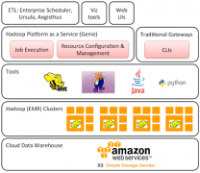
在大数据蔓延的今天,传统的数据仓库厂商都为客户做了哪些努力?在本文中,您将了解到如何将现有数据仓库架构的功能发挥到最大,Hadoop的优势与劣势,以及大数据时代中每一个数据仓库厂商的发展等。
以Hadoop Tutorial为主体带大家走一遍如何使用Hadoop分析数据!MapReduce框架由一个Jobracker(通常简称JT)和数个TaskTracker(TT)组成(在cdh4中如果使用了Jobtracker HA特性,则会有2个Jobtracer,其中只有一个为active,另一个作为standby处于inactive状态)。JobTr
已经发布了早期代码,让客户可以将这个Java架构接入到SQL Server 2008 R2、SQL Server Parallel,微软目前已经开始提供Hadoop Connector for SQL Server Parallel Data Warehouse和Hadoop Connector for SQL Server社区技术预览版本的连接器。

YARN本质上是Hadoop的新操作系统,突破了MapReduce框架的性能瓶颈。Murthy认为Hadoop和YARN的组合是企业大数据平台致胜的关键。
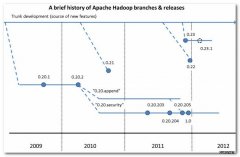
Cloudera Hadoop对应Apache Hadoop版本。(1) Apache Hadoop版本介绍Apache的开源项目开发流程 :-- 主干分支 : 新功能都是在 主干分支(trunk)上开发;-- 特性独有分支 : 很多新特性稳定性很差, 或者不完善, 在这些分支的独有特定很完善之后。
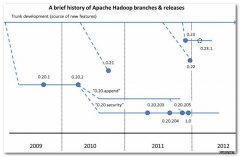
HDFS Federation:NameNode制约HDFS扩展,该功能让多个NameNode分管不同目录,实现访问隔离和横向扩展。。Hadoop版本和生态圈1. Hadoop版本(1) Apache Hadoop版本介绍Apache的开源项目开发流程:主干分支:新功能都是在主干分支(trunk)上开发。
国内大数据技术服务商百分点公司已将机器学习的相关技术应用到大数据分析中,在百分点合作的某一团购网站,我们选取了10个基于商品和用户的特征属性,结合机器学习中的分类算法,构建了一个基于用户推荐的分类器。
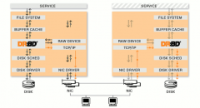
存储/计算分离模型:将存储节点(Data Node)和计算节点(Task Tracker)部署在不同的虚拟机中,并且根据特定的业务需求,通过相应的分布算法决定集群在vSphereESX物理主机上的拓扑结构。
Hadoop的框架最核心的设计就是:HDFS和MapReduce、HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。