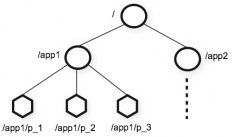
Hadoop集群的部署环境是经过虚拟化之后的四台主机,Master是Hadoop集群的管理节点,重要的hadoop安装配置工作都在它上面,至于它的功能和作用请参考HadoopAPI。

RedHadoop正在构建一个更完善的Hadoop分布式操作系统。会针对各个垂直应用领域做出持续优化比如 Data Storage,Data HouseWare,DataBase,RealTime,Data Mining,Data Search 等等方向做深度定制。

Cloudera与MasterCard的合作项目,借助HDFS和Hadoop集群以及Apache Sentry,Cloudera实现了在线与离线的所有数据与元数据的保护。
开发Hadoop相应的程序就得用JAVA,找到相应的版本进行下载,我这里用的是eclipse-SDK-3.7.1-linux-gtk版本。
Cloudera和英特尔合作实现了安全领域的技术革新,Hadoop核心技术在 Cloudera 四个发行版本中的持续优化,更好的可管理性。此外,双方的合作还帮助减少了企业使用大数据分析技术的障碍,带来了全新的解决方案、一体机和云上的部署。

Sqoop和Flume可改进数据的互操作性和其余部分。Sqoop功能主要是从关系数据库导入数据到Hadoop,并可直接导入到HFDS或Hive。而Flume设计旨在直接将流数据或日志数据导入HDFS。
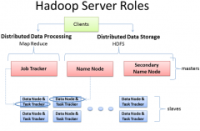
Hadoop主要的任务部署分为3个部分,分别是:Client机器,主节点和从节点。Client机器集合了Hadoop上所有的集群设置,但既不包括主节点也不包括从节点。取而代之的是客户端机器的作用是把数据加载到集群中,递交给Map Reduce数据处理工作的描述,并在工作结束
Hive是基于Hadoop的一个数据仓库工具,本质是将SQL转换为MapReduce程序,操作接口采用类SQL语法,提供快速开发的能力,Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
操作Hadoop的第一步就是要准备连接工具SSH,完成后启动验证它。在前面我们安装Java的时候把Java安装在了“/usr/lib/java/jdk1.7.0_60”,此时我们在hadoop-env.sh配置文件加入如下配置信息。

正确把握Hadoop发展趋势并不难,就像Forrester说的那样,Hadoop未来的发展主要取决于不断变化的数据基础设施,而且Hadoop已经成为“未来灵活数据管理平台的基石”。对技术供应商而言,想要跟上如今企业的步伐,它只需要一份关于Hadoop的报告。
How to Benchmark a Hadoop Cluster 博客分类: 测试 hadoopcluster How to Benchmark a Hadoop Clusterhttp:/
精通 HADOOP一书是由罗伯特.李翻译自英文书
本文注重实际安装配置,主要用于指导未使用的hadoop 的技术人员,部署Hadoop 和HBase 学习环境。本次测试采用4 台虚拟机,操作系统为RHEL 6.2。
Pivotal公司将对其 Hadoop 分支和其他数据库产品(如 Greenplum 和 HAWQ)进行开源。Hortonworks是一家完全支持开源的公司,其所有的代码都会回馈给Apache Hadoop项目。