烽火将在武大超算中心同时提供Intel KNL以及NVIDIA GPU超算解决方案,两种顶尖HPC方案在同一项目中实施,配合OPA 100G网络,极大提升超算中心整体性能。
近日,继“武汉大学100G高速网络及网格计算集群采购项目”中标后,烽火GPU高性能服务器再次中标“武汉大学GPU集群采购项目”。作为行业首例,此次烽火将在武大超算中心同时提供Intel KNL以及NVIDIA GPU超算解决方案,两种顶尖HPC方案在同一项目中实施,配合OPA 100G网络,极大提升超算中心整体性能。
根据客户需求,烽火提供业界最新超算解决方案,包括最大GPU密度、最新的NVLink 2.0技术两大特点。本次武汉大学GPU集群项目采用了55套烽火FitServer G1480 GPU服务器作为计算节点,配置220块NVIDIA 最新架构的V100 GPU,通过Intel® Omni-Path fabric网络进行节点间高速互联,具有最大GPU到GPU带宽,可支持重要的高性能计算(HPC)集群和超大型工作负载,轻松满足武汉大学对于HPC计算和AI计算的需求。
极致密度,极致性能,业界规格最高的1U高性能并行计算平台
烽火FitServer G1480 GPU服务器在1U高度机箱,集成4路Tesla V100 GPU,支持NVLink 2.0高速互联技术,具备GPU无需预加热、GPU Direct RDMA技术、专业成熟的散热设计、集成超高能效比电源等多个特点,整机混合精度计算性能高达500万亿次每秒。FitServer G1480作为业界规格最高的1U高性能并行计算平台,在提供超高计算性能的同时,降低超算中心在机房空间上的成本投入。

FitServer G1480服务器
同构计算,NVLink 2.0高速互联技术,具备超高并行计算效率
FitServer G1480服务器采用Cube Mesh拓扑,实现了同构计算,4块GPU可以在不依赖CPU的前提下,实现机内点到点通讯,大幅减少异构通讯的次数。采用NVLink 2.0高速互联技术,GPU间互连带宽可达300GB/s,使GPU性能发挥至极致,单卡混合精度浮点计算性能高达125万亿次每秒,并具有极低的延迟,
满足武汉大学超算中心对于并行计算效率的高要求。
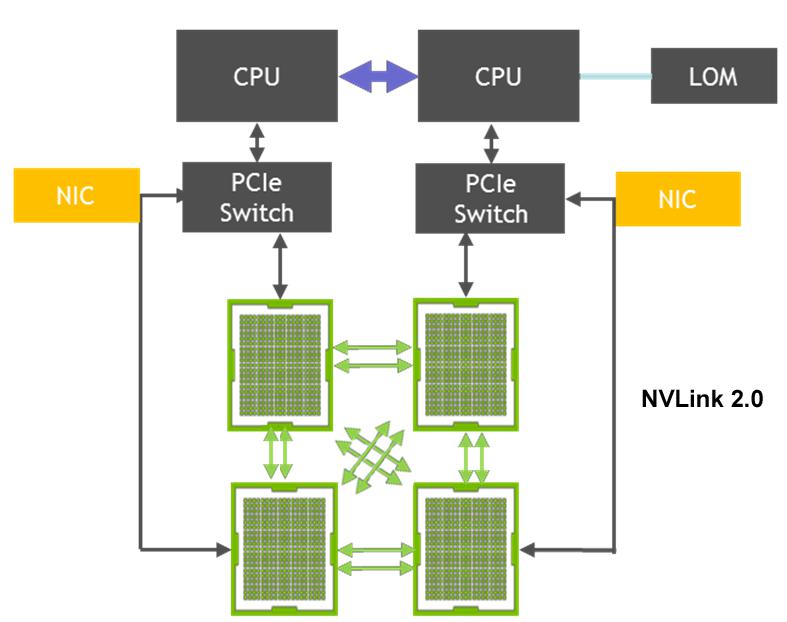
NVLink 2.0 Cube Mesh拓扑,300GB/s互联带宽
搭载全新架构GPU,整机性能大幅提升
服务器搭载的NVIDIA Tesla V100 GPU,采用最新的12nm工艺设计,芯片面积达815平方毫米,210亿颗晶体管,5120个CUDA Core,640个Tensor Core,芯片计算和节能性能都显著提升,平均加速比可以达到3倍。Tesla V100 GPU相比Tesla P100 GPU,针对深度学习中的Training(训练)和Inference(推理)大量的矩阵运算,新增Tensor Core单元,矩阵运算提升了12倍,并采用最新的NVLink 2.0技术和HBM2技术,有效地提升了CPU与GPU或者GPU与GPU之间传输带宽及显存的带宽和利用率。

NVIDIA Tesla V100 GPU
强大的软硬件设计能力,提供领先的整体解决方案
在高速网络与智能化飞速发展的今天,烽火提出的解决方案完美满足了武汉大学建设高性能、大容量超算中心的需求,并利用其强大的技术研发实力、完善的质量保证体系、先进的生产工艺和测试方案,为超算中心提供先进、稳定、可靠的基础建设产品及解决方案。
烽火在“武汉大学GPU集群采购项目”中,从众多参与厂家中脱颖,充分体现了烽火在大ICT领域的实力,以及客户对烽火在服务器领域技术实力和交付能力的认可。而烽火将持续发力,为全面进入信息化大市场,打造ICT基础设施和解决方案的领导者而不断努力。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。





























