
Teradyne Titan HP 平台为 AI 和云设备提供高功率、真实世界的 SLT
泰瑞达 Titan HP 代表了测试为当今云和人工智能基础设施提供动力的领先设备方面的重大进步。...
泰瑞达 Titan HP 代表了测试为当今云和人工智能基础设施提供动力的领先设备方面的重大进步。...

PEAK Open pNFS是一个开放、可扩展的并行存储解决方案,具有无与伦比的 AI 和 HPC 性能。...

ExaPOD 与英特尔、Solidigm 和 Supermicro 合作设计,提供具有行业领先密度、性能和经济性的下一代 AI 数据基础。...

中国存储网消息,HPE 宣布被选中为美国能源部 (DOE) 橡树岭国家实验室 (ORNL) 构建两个系统,作为美国能源部推进美国在支持科学、能源和国家安全的人工智能 (AI) 和超级计算方面的领...

新的超级计算产品组合具有直接液冷多合作伙伴、多工作负载刀片、统一管理软件和现代高性能互连,可帮助客户在融合 AI 和 HPC 工作负载时代实现大规模生产力。...


由最新的 NVIDIA Blackwell GPU 提供支持的 SKT 新的主权 AI 基础设施上部署其先进的 AI 平台。
...

最新全球超级计算机排名,也就是第65届超级计算机TOP500榜单,基于AMD架构的超算系统在前十榜单中占据主导地位。...

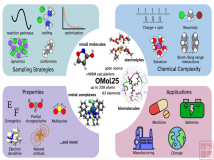
Meta 还分享了其通用原子模型 (UMA),这是一种基于机器学习数据的工具,用于模拟原子在各种材料和分子中的相互作用。...





新的超级计算机将建立在 Vega 超级计算机的现有功能之上,支持人工智能、大数据分析、生物技术和环境科学等领域的复杂研究和尖端解决方案的开发。...


随着加速器技术的进步和数据集规模的不断增加,ML 系统提供商必须确保其存储解决方案能够满足计算需求。...
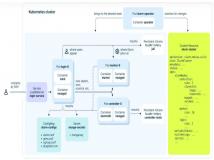
用于 Slurm 的全功能 Kubernetes 运算符,旨在优化现代机器学习 (ML) 和高性能计算 (HPC) 环境中的工作负载管理和编排。...

这个被称为 Ultra Accelerator Link (UALink) 的初始小组将定义并建立一个开放的行业标准,使 AI 加速器能够更有效地进行通信。...




Fluid Dynamic Sciences利用创新的 AI 和 GPU提供了一种更智能、更快速、更可持续的流体动力学方法。...
这些改进使 HPE 能够将 AI 规模的吞吐量提高两倍,并将功耗降低多达 50%。...




