如今SDS领域玩家众多,技术流派也很多,有开源的、有闭源的;有对称结构、有非对称结构;有叫SDS的、也有叫HCI(Hyper-Converged Infrastructure)、还有叫ServerSAN、云存储的,令人眼花缭乱、摸不清头脑。
中存储网消息,如今SDS领域玩家众多,技术流派也很多,有开源的、有闭源的;有对称结构、有非对称结构;有叫SDS的、也有叫HCI(Hyper-Converged Infrastructure)、还有叫ServerSAN、云存储的,令人眼花缭乱、摸不清头脑。
应该说SDS还处在发展的初期阶段,相应的技术和测试标准都还不完善,客户对其技术了解的深度也不够。两大因素综合起来造成客户选择SDS的时候会感觉无从下手。
三类SDS应用场景的三大关键指标
SDS按照提供的数据组织方式分为块存储、文件存储和对象存储三类。按照交付模式又分成独立存储形态和HCI形态(也就是把SDS、计算和网络集成在一个系统里)两种。本文仅以SDS的块存储类别为例,从企业用户的角度如何选择一款适合自己的SDS。
SDS块存储的主要应用场景和传统的SAN设备类似,主要应用在需要提供裸磁盘(块设备)的场景,例如:服务器虚拟化、桌面虚拟化、数据库等。当然SDS块存储提供出的块设备也可以格式化成本地文件系统,存放一些非结构化数据,但这不是主要应用场景。
建议客户选择SDS的时候,首先需要问一下自己两个问题:1、主要应用场景是什么?2、最关注的前三位的技术指标是什么?而且还要清楚SDS发展在什么阶段(目前SDS还处在社会主义的初级阶段),把预期和现实拉得近一些,有些过高的要求在这个阶段SDS还不能提供。
关于SDS技术评价通常包括以下7个维度:可靠性、稳定性、扩展性、功能、性能、易用性、兼容性。
针对SDS块存储前三位技术指标维度为: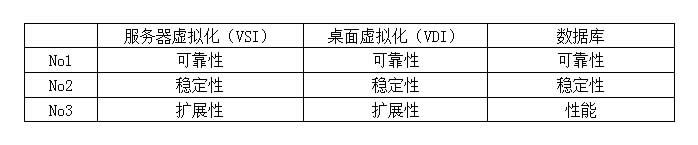
三大应用场景都把可靠性和稳定性排在了前两位,之因此这样排列因为存储是IT系统的基石。所谓的可靠性就是局部故障不会导致数据丢失和业务中断,这一点理所应当排在第一位;稳定性是指不会因为局部故障造成性能大幅抖动,给业务响应造成影响,比如说看个小电影中途老卡谁受得了。
说到这有人会问,这两点对于传统阵列是必须和默认的要求?我想说,传统阵列都是昂贵、专用的硬件堆起来,发生硬件故障的概率很低,而SDS大都部署在廉价的标准x86服务器上,x86服务器发生硬件故障的概率要高很多;并且SDS都是分布式系统,要管理几十台、乃至成千上万台x86服务器上,这样发生硬件故障的概率会呈数量级的上升。如何保证大规模分布式系统的可靠性和稳定性也正是SDS首要解决的难点。
Amazon的S3系统由上百万台服务器组成,每分钟都会有很多设备下线和上线,能保证这样大规模集群的可靠性和稳定性,应该没几个厂家有这样的技术吧?
另外还别忘了,SDS还处在“社会主义初级阶段”并不是拿出来一个厂家就能保证几千台服务器的SDS系统可靠和稳定的。
VSI和VDI环境通常规模很大,而且规模增长的速度也较快,因此把扩展性放在了第三位。对于数据库应用,性能是毋容置疑非常重要的一个指标,因此排在了第三位。
眼见未必为实,测试中的那些“猫腻”
终于想清楚我要的SDS长什么样了,忽然又想起一件大事“谁家的产品能达到我的要求呢?”
一个最直接的办法就是拿测试来说吧(测试还是蛮麻烦的一件事,准备测试环境、编写测试规范、查看测试结果……)。或许还有一个偷懒的办法,就是“你们有和我的需求差不多的案例吗?我去问问那家企业用的咋样啊”,但耳听为虚眼见为实,听一面之词总是不踏实。
相比之下测试是一个较为让人放心的办法,但如果你不熟悉SDS的水,同样有些坑你也发现不了,嘿嘿。
好了,下面这一段就是从测试和技术构架角度帮助客户判断关键技术指标优劣。
1、B域、C域,1/3节点损坏和RTO为0
可靠性在SDS上主要体现在两个方面,当集群中磁盘或节点发生故障时,数据会不会丢失?业务会不会中断?中断的时长是多少?
这里有两个指标需要关注:1、容错度,2、故障恢复时间。
先说一下容错度这个指标。
因为主流的SDS都采用副本技术,以三副本为例,丢失1份数据,应该还有2份数据存在,数据不会丢,也就是容错度为1/3个节点。但如果超过1/3的节点同时down机,集群还能工作吗?这个不一定所有厂家都能做到。
很多SDS的容错域都是提前配置好的。以3副本9个节点为例,通常会配置3个容错域ABC、每个容错域各3个节点,每个容错域保存独立的副本数据。例如当以一个容错域A的3台机器都故障时,还有两2个副本存在,数据不会丢失,业务照常运行,这就是通常所说的能容忍1/3节点宕机。这样的要求大多数厂家都能做到,但如果同时B域或者C域也有机器down机呢?这时候多半会出现两副本都丢失情况,系统异常了。
故障恢复时间这个指标也很关键。当系统中发生节点宕机,故障恢复的时间当然越快越好了,最高的要求是故障恢复时间等于0。要实现这个指标很不容易,因为当SDS系统中节点发生故障时,要恢复这个故障,需要做很多事:第一步,发现这个故障;第二步,选出一个节点接替故障节点,并进行数据重构;第三步,重新刷新寻址空间,让客户机能获取数据位置的变化。每一步都需要时间花费,特别对大规模集群来讲,想把故障恢复时间控制得很小更是难上加难。宣称故障恢复时间为零的SDS厂家并不多。
因此故障恢复时间的数量级是衡量一个SDS可靠性等级的一个非常重要的因子。用户可以根据前端业务对故障恢复时间的敏感程度,设立相应的要求标准。
2、Ceph性能抖动的问题
对于SDS来讲,它的稳定性主要关注点在:当系统发生磁盘/节点故障,恢复数据而产生数据迁移时,前端的性能表现是否稳定。
在前面可靠性段落中谈到了,SDS故障恢复有三个步骤,每一步处理不好都会影响性能表现。特别是数据重构和重新寻址这两个环节,会对性能稳定性造成很大的影响。
例如著名的开源产品Ceph,不止一个客户反映当系统中出现节点宕机的情况下,性能下降和波动很厉害,对业务影响很大。只因此出现这个问题首先是和它元数据管理和寻址的方式(Crush算法)关于,即在节点动荡时,元数据(其实是ceph内部保存的资源列表)发生变化,从而导致数据的地址发生变化,最终导致大量的没有必要的数据迁移,规模越大,这个问题暴露的越明显。其次是它数据迁移采用整盘拷贝的方式,会有无效迁移导致的网络带宽的拥挤。
还有一个坑透露一下,有些SDS系统在拔盘或者宕节点时,可以不发生数据重构,当磁盘或者节点重新上线或归位时才重构。因此,稳定性测试时最好观察一下,磁盘或者节点归位后的表现。甚至建议,用频繁的节点上/下线来测试它的稳定性,因为节点抖动还是会时常发生的。
3、VSAN的局限
扩展性很难测试,因为你要准备几百台、上千台的服务器环境是不可能,除非你是土豪,那怎么办?没办法,看构架吧。市场上主流SDS分为有中央元数据管理节点的非对称构架和无中央管理节点的全对称构架两大类,前者相比后者扩展性受限。简单的理解就是“非对称构架”中好比有个指挥官,一个指挥官能管的人比较有限的。“全对称构架”中是没有指挥官的,全凭自觉性,像是一大堆人在干活,一个病了,无需向领导请假,会有另外一个人立马自动接替他的工作。举例证明:VSAN是有中央管理节点的,它官方宣称的单集群支持最大节点数64个;鹏云网络的ZettaStor是无中央节点的,能支持万级的节点数量。因此从具体实例上也能看出,构架决定了其扩展能力。
4、SSD缓冲击穿
目前闪存技术发展得很快,性能比传统磁介质硬盘高了几个数量级,正是因为闪存技术的发展也给SDS造就了可以在性能上PK传统阵列的基础。
如果你很有钱的话完全可以用SSD做主存。但目前SSD价格还较贵,性价比较高的方式是用SSD做缓存,通常一个存储节点上配个几百GB-1TB的SSD做缓存。SSD缓存对性能的贡献在小数据量时会表现的非常好,一旦数据量足够大,SSD被穿透,那就实打实地看落盘(写到硬盘持久化层)的性能表现了。如果你的系统数据量很小,SSD缓存的容量足够你支持业务峰值,那可以多些关注SDS缓存加速的性能表现。如果你的系统数据量很大,那SSD会长时间被穿透,那你就重点一下落盘的性能表现了。
目前SDS厂家在SSD缓存利用效率上,水平都差不太多,没有太多很独到的算法出现。倒是落盘这个环节,因为选择的技术路线不同,表现不一。有的就是差不多发挥原有磁盘的性能,甚至还低;有的利用一些IO算法,把普通磁盘的性能表现提升几倍,像鹏云网络的ZettaStor在落盘时采用了“变随机为半顺序”的IO优化算法,把随机IO裸盘的速度提升了3-5倍。鹏云网络之因此能做这样的IO优化,因为ZettaStor是完全自主开发的。采用开源方案的厂家要实现起来估计会很难,这是要动到其核心文件系统层的。
有些厂家在性能测试时会用很小的卷、很小的数据去测试,看上去IOPS会很高,但真实环境不会是这么小的负载,因此一旦多创建些大卷,进行长时间大数据量的性能测试,SSD被写穿透时,性能立马一落千丈,凤凰变乌鸡了。
不记得那位大咖说过一句话,“不谈延迟的性能测试都是耍流氓”。
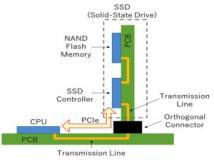
看一个系统的延迟小不小,一个是实测,另外从构架上也能看出些端倪。就是看一下它的IO路径是否够短。例如,直接写裸磁盘的总比经过文件系统层转换再写裸磁盘的IO路径短很多吧,这就是为什么Ceph想降低延迟很难的原因所在。众所周知,Ceph的块存储不是直接访问裸磁盘的,而是通过文件系统把裸磁盘转换成块设备给应用的。
小结
看到了这些问题,是不是让你对SDS望而却步了?如果这样,你就把孩子、脏水一起泼掉了。
就像改革开放,阳光和苍蝇总会一起进来,良莠不齐,这是目前SDS市场的正常现象,鹏云网络之因此把些伤疤揭开,是因为相信,真金不怕火炼!用户可以不选择鹏云网络,但一定要争取选择正确!这是写作本文所期待的!
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。