选择Hadoop的原因最重要的就是这三点:1,可以解决问题; 2,成本低 ; 3,成熟的生态圈。一,Hadoop帮助我们解决了什么问题无论国内还是国外的大公司对于数据都有着无穷无尽的渴望,都会想尽一切办法收集一切数据,因为通过信息的不对称性可以不断
选择Hadoop的原因最重要的就是这三点:1,可以解决问题; 2,成本低 ; 3,成熟的生态圈。
一,Hadoop帮助我们解决了什么问题
无论国内还是国外的大公司对于数据都有着无穷无尽的渴望,都会想尽一切办法收集一切数据,
因为通过信息的不对称性可以不断变现,而大量的信息是可以通过数据分析得到的。
数据的来源途径非常的多,数据的格式也越来越多越来越复杂,随着时间的推移数据量也越来越大。
因此在数据的存储和基于数据之上的计算上传统数据库很快趋于瓶颈。
而Hadoop正是为了解决了这样的问题而诞生的。其底层的分布式文件系统具有高拓展性,通过数据冗余保证数据不丢失和提交计算效率,同时可以存储各种格式的数据。
同时其还支持多种计算框架,既可以进行离线计算也可以进行在线实时计算。
二,为什么成本可以控制的低
确定可以解决我们遇到的问题之后,那就必须考虑下成本问题了。
1, 硬件成本
Hadoop是架构在廉价的硬件服务器上,不需要非常昂贵的硬件做支撑
2, 软件成本
开源的产品,免费的,基于开源协议,可以自由修改,可控性更大
3,开发成本
因为属于二次开发,同时因为有非常活跃的社区讨论,对开发人员的能力要求相对不高,工程师的学习成本也并不高
4,维护成本
当集群规模非常大时,开发成本和维护成本会凸显出来。但是相对于自研系统来说的话,还是便宜的很多。
某司自研同类系统几百名工程师近4年的投入,烧钱亿计,都尚未替换掉Hadoop。
5,其他成本
如系统的安全性,社区版本升级频繁而现实是无法同步进行升级所引入的其他隐形成本。
三, 成熟的生态圈有什么好处
成熟的生态圈代表的未来的发展方向,代表着美好的市场前景,代表着更有钱途的一份工作(好吧,“三个代表”).
看图(引自:Hadoop Ecosystem Map ? myNoSQL)
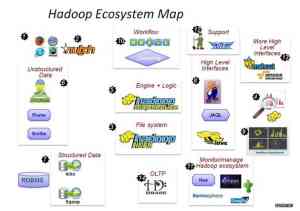
部分系统归类:
部署,配置和监控 Ambari,Whirr
监控管理工具 Hue, karmasphere, eclipse plugin, cacti, ganglia
数据序列化处理与任务调度 Avro, Zookeeper
数据收集 Fuse,Webdav, Chukwa, Flume, Scribe , Nutch
数据存储 HDFS
类SQL查询数据仓库 Hive
流式数据处理 Pig
并行计算框架 MapReduce, Tez
数据挖掘和机器学习 Mahout
列式存储在线数据库 HBase
元数据中心 HCatalog (可以和Pig,Hive ,MapReduce等结合使用)
工作流控制 Oozie,Cascading
数据导入导出到关系数据库 Sqoop,Flume, Hiho
数据可视化 drilldown,Intellicus
使用到的公司也非常的多
(引自: A New Version of the Hadoop Ecosystem Map)

声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。


































