大数据是现在非常热门的一个话题,SQL on Hadoop是目前大数据技术发展的一个重要方向,如何可以迅速的了解掌握这门技术,CSDN特地邀请梁堰波来为我们做这次讲座“用SQL-on-Hadoop构建互联网数据仓库与商务智能系统”,通过
大数据是现在非常热门的一个话题,SQL on Hadoop是目前大数据技术发展的一个重要方向,如何可以迅速的了解掌握这门技术,CSDN特地邀请梁堰波来为我们做这次讲座“用SQL-on-Hadoop构建互联网数据仓库与商务智能系统”,通过对业务需求与SQL-on-Hadoop现状的分析,详细阐述SQL on Hadoop中各个技术点,分享一线的经验实践,帮助从业技术人员更快的掌握相关技术要点,少走弯路。
对于一个工程师或者分析师来说,如何查询和分析TB/PB级别的数据是在大数据时代不可回避的问题。SQL on Hadoop就成为了一个重要数据分析与挖掘工具。此时可能会有疑问,为什么非要把SQL放到Hadoop上? 因为SQL易于使用;那为什么非得基于Hadoop呢?因为Hadoop架构具备很强的鲁棒性和可扩展性。
梁堰波表示大数据时代,数据的价值是所有企业都能看见的宝贵财富,大数据的核心也是将有效数据从海量的数据中挖掘分析出来,从而利用有效数据创造价值。在互联网企业和有大数据处理需求的传统企业中,基于Hadoop构建的数据仓库的数据来源主要有通过Apache/Nginx的日志收集到的数据、一般存储在Oracle/MySQL中的用户和业务数据、通过ETL工具从其他外部DW数据源里导入的数据等。他讲到其实目前所有的SQL on Hadoop产品其实都是在某个或者某些特定领域内适合的,没有万能的产品。像当年Oracle/Teradata这样的满足几乎所有企业级应用的产品在大数据时代是不现实的。所以每一种SQL on Hadoop产品都在尽量满足某一类应用的特征。
以Hive和Impala为例来说,Hive是目前互联网企业中处理大数据、构建数据仓库最常用的解决方案,甚至在很多公司部署了Hadoop集群不是为了跑原生MapReduce程序,而全用来跑Hive SQL的查询任务。
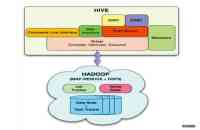
对于有很多data scientist和analyst的公司,会有很多相同表的查询需求。那么显然每个人都从Hive中查数据速度既慢又浪费资源。如果能把经常访问的数据放到内存组成的集群中供用户查询那样效率就会高很多。Facebook针对这一需求开发了Presto,一个把热数据放到内存中供SQL查询的系统。这个设计思路跟Impala和Stinger非常类似了。使用Presto进行简单查询只需要几百毫秒,即使是非常复杂的查询,也只需数分钟即可完成,它在内存中运行,并且不会向磁盘写入。Facebook有超过850名工程师每天用它来扫描超过320TB的数据,满足了80%的ad-hoc查询需求。
Impala则可以看成是Google Dremel架构和MPP (Massively Parallel Processing)结构的混合体。
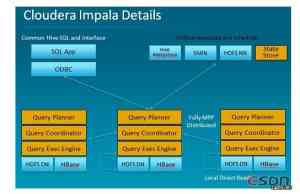
目前主要是Cloudera在主导这个项目。以百度为例,百度尝试把MySQL接入Impala的后端作为存储引擎,同时实现相应操作对应的PlanFragment,那么用户来的query还是按照原来的解析方法解析成各种PlanFragment,然后直接调度到对应的节点(HDFS DataNode/HBaseRegionServer/MySQL)上执行。会把某些源数据或者中间数据放到MySQL中,用户的query涉及到使用这部分数据时直接去MySQL里面拿。
梁堰波从技术架构和最新进展两个角度分析一下各种SQL on Hadoop产品的优缺点和适用范围:Hive、Tez/Stinger、Impala、Shark/Spark、Phoenix、 Hdapt/HadoopDB、Hawq/Greenplum。梁堰波对此7种最新技术从产品的原理,使用场景,架构,优缺点,性能优化等方面做了深度阐述。文章详情点击:SQL on Hadoop的最新进展及7项相关技术分享
此次CSDN在线培训:“用SQL-on-Hadoop构建互联网数据仓库与商务智能系统”中,梁堰波会介绍目前在互联网领域数据仓库和商务智能系统构建的业务需求和解决方案。SQL-on-Hadoop产品的原理,使用场景,架构,优缺点,性能优化等。最后会介绍几个实际案例帮助大家理解互联网数据仓库和SQL-on-Hadoop产品。本次培训将会讲到的技术点有:Hadoop、Hive、Impala、Shark、Flume、Oozie、Sqoop、Zookeeper、HBase、Tableau、MicroStrategy框架的对比介绍,以及优缺点比较、使用场景、目前在企业的应用案例,同时还将带来几种常用的解决方案与比较!
本次在线培训采用三分屏模式,在听课的同时可以和讲师进行互动,让你感受真实的课堂环境。还在为Hadoop“手艺”无处可学而烦恼?还在为Hadoop企业级应用而头疼?快来看看吧!
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。


































