什么是PIM?这是一种通过利用任何内存芯片中可用的非常大的带宽来提高处理速度的方法。PIM背后的概念是将处理器直接构建到DRAM芯片中。
国外技术网站Memory Guy消息,8月31日的HotChips会议展示了一个名为“处理内存”(PIM)的概念,该概念已经存在了很长时间,但尚未进入主流计算领域。一位主持人表示,他的公司,一家名为UPMEM的法国公司,希望改变这种状况。
什么是PIM?这是一种通过利用任何内存芯片中可用的非常大的带宽来提高处理速度的方法。

存储器芯片内部的阵列非常方形:字线选择大量的位(数十或数十万),它们一次变为活动状态,每个位都在其自己的位线上。然后这些无数位慢慢转入I / O引脚。
高带宽内存(HBM)和混合内存多维数据集(HMC)试图通过堆叠特殊的DRAM芯片并运行来克服这一瓶颈数千总线垂直向下到底部的逻辑芯片,可以高速驱动多达1,024个I / O引脚。这是一个帮助,但它仍然比堆栈中任何DRAM芯片的内部带宽慢得多。
PIM背后的概念是将处理器直接构建到DRAM芯片中,并将它们直接连接到所有内部位线,以利用存储器芯片所提供的惊人内部带宽。这不是一个新的想法。我在20世纪80年代首次听说过这个概念,当时一位发明家找到了当时的雇主IDT,希望我们将处理器放入我们的4Kbit SRAM中!即使在那些日子里,PIM架构也会大大加速图形处理,这是本发明人的目标。
大约8年前,Memory Guy还发布了一篇关于一家名为Venray的公司的博客文章,该公司试图说服各种DRAM厂商建立基于DRAM的PIM芯片。最近与Venray的对话表明,他们终于在这个方向上取得了进展,很快就会有一些好消息要分享。
回到UPMEM:该公司的名称似乎源于微处理器“μP”的简写术语与“Memory”一词的缩写形式的融合,但在“μP”中用“U”代替“μ” ”。一些读者可能从未见过“μP”这个术语,因为近几十年来它已被“MPU”取代。
我向UPMEM管理层询问了他们的方法与我上面提到的两种替代架构之间的差异:VenRay的TOMI和Micron最近分拆到一家名为Natural Intelligence Semiconductor的新公司的Automata处理器。(Memory Guy 在大约六年前的2013年也在Automata处理器上发布了一篇文章。我有没有提到这个想法已经存在了很长时间?)他们解释说,虽然这三种方法都利用了DRAM芯片巨大的内部带宽,处理器架构非常不同,每个都有不同的目标:
- Automata是一个可编程的大门,非常强大,但由于这一点,编程非常具有挑战性。它旨在解决极其复杂的算法,包括NP难问题:最终难度的计算测试。
- TOMI在DRAM中插入了一个功能非常强大的处理器,其目标是允许用户通过将大部分工作卸载到TOMI芯片来替换昂贵的服务器处理器,使用更加适中且成本更低的CPU。
- UPMEM将适度的RISC处理器与DRAM相结合,旨在加速某些非常特定的任务,这些任务可以卸载到DIMM,以减少服务器处理器的负载,同时减少内存通道上的大量流量。
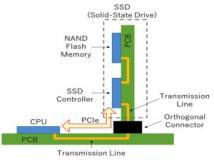
自动机通常插入PCIe附加卡的服务器中。UPMEM使用标准格式的DIMM(如本文的图形所示 - 点击放大),以支持内存和服务器处理器之间更高的带宽。当不使用PIM处理器时,这些DIMM表现为标准DRAM。
所有这三种解决方案目前都可用(自动机)或非常接近可用(TOMI和UPMEM),这三种解决方案似乎都是加速数据中心特定问题的绝佳方式,同时显着降低了总体成本。
这些公司的时机是好的:在DRAM短缺期间(就像我们在2018年那样),主流DRAM制造商不愿意将其生产能力的一小部分用于风险产品,因为他们已经能够销售比他们更多的标准DRAM可以生产。在今天的供过于求的情况下,这些公司更愿意尝试新的东西以充分利用闲置产能。与此同时,超大规模数据中心拥有丰富的现金,并且非常有兴趣测试替代传统计算机架构的新概念。这就是人工智能近来如此突出的原因。
那些想要了解更多有关PIM技术的人可能想要访问UPMEM的“用例”页面,其中包含三篇白皮书,Venray“战略论文”页面,其中包含79个作品的热门链接,或自然智能“研究”页面,它与研究工作的31个链接是用他们的芯片进行的。想要了解将使这些芯片成功或失败的商业和经济因素的读者应联系Objective Analysis,了解我们如何帮助您就这项不断发展的技术做出正确的商业决策。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。