Spark火了。在国外 Yahoo!、Twitter、Intel、Amazon、Cloudera 等公司率先应用并推广 Spark 技术,Spark能否成为Hadoop的替代者呢?为什么?它们有哪些相似点与区别?
大数据的浪潮风靡全球的时候,Spark火了。在国外 Yahoo!、Twitter、Intel、Amazon、Cloudera 等公司率先应用并推广 Spark 技术,在国内阿里巴巴、百度、淘宝、腾讯、网易、星环等公司敢为人先,并乐于分享。在随后的发展中,IBM、Hortonworks、微策略等公司纷纷将 Spark 融进现有解决方案,并加入 Spark 阵营。Spark 在IT业界的应用可谓星火燎原之势。
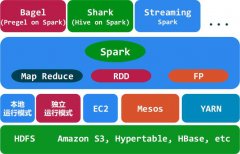
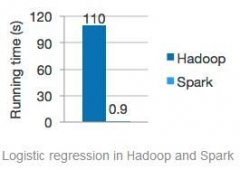
创新都是站在巨人的肩膀上产生的,在大数据领域Spark也不例外。在 Spark 出现前,要在一个平台内同时完成批处理、各种机器学习、流式计算、图计算、SQL 查询等数种大数据分析任务,就不得不与多套独立的系统打交道,这需要系统间进行代价较大的数据转储,但是这无疑会增加运维负担。Spark一开始就瞄准了性能,实现了在内存中计算。
1.Spark为啥这么火?Spark框架采用的编程语言是什么?是否容易上手?
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合,如pageRank、K-Means等算法就非常适合内存迭代计算。Spark整个生态体系正逐渐完善中,GraphX 、 SparkSQL、 SparkStreaming 、 MLlib,等到Spark有了自己的数据仓库后,那就完全能与Hadoop生态体系相媲美。
Spark框架采用函数式编程语言Scala,Scala语言的面向对象、函数式、高并发模型等特点,使得Spark拥有了更高的灵活性及性能。如果你学过java,可能会对scala中的一些新概念表示陌生,如隐式转换、模式匹配、伴生类等,但一旦入门,你会感觉scala语言的简洁与强大。
2. Spark能否成为Hadoop的替代者呢?为什么?它们有哪些相似点与区别?
两者的侧重点不同,使用场景不同,个人认为没有替代之说。Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的概念。RDD可以cache到内存中,那么每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。但是,我们也要看到spark的限制:内存。我认为Hadoop虽然费时,但是在OLAP等大规模数据的应用场景,还是受欢迎的。目前Hadoop涵盖了从数据收集、到分布式存储,再到分布式计算的各个领域,在各领域都有自己独特优势。
3. 作为一种内存的迭代计算框架,Spark适用哪些场景?
适用于迭代次数比较多的场景。迭代次数多的机器学习算法等。如pageRank、K-Means等。
4. 淘宝为什么会选择Spark计算框架呢?
这主要基于淘宝业务的应用场景,其涉及了大规模的数据处理与分析。其主要是应用Spark的GraphX图计算,以便进行用户图计算:基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。
5.Mesos 是一个能够让多个分布式应用和框架运行在同一集群上的集群管理平台。那么它是如何来调度和运行Spark的呢?
目前在Spark On Mesos环境中,用户可选择两种调度模式之一运行自己的应用程序
粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task(对应多少个“slot”)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。举个例子,比如你提交应用程序时,指定使用5个executor运行你的应用程序,每个executor占用5GB内存和5个CPU,每个executor内部设置了5个slot,则Mesos需要先为executor分配资源并启动它们,之后开始调度任务。另外,在程序运行过程中,mesos的master和slave并不知道executor内部各个task的运行情况,executor直接将任务状态通过内部的通信机制汇报给Driver,从一定程度上可以认为,每个应用程序利用mesos搭建了一个虚拟集群自己使用。
细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。与粗粒度模式一样,应用程序启动时,先会启动executor,但每个executor占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,mesos会为每个executor动态分配资源,每分配一些,便可以运行一个新任务,单个Task运行完之后可以马上释放对应的资源。每个Task会汇报状态给Mesos slave和Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于MapReduce调度模式,每个Task完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
6.Spark 为什么会选择弹性分布式数据集(RDD)作为它的数据存储核心?而不是分布式共享内存(Distributed Shared Memory)DSM?它们有哪些区别?
RDD是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现。RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。这对于迭代运算比较常见的机器学习算法, 交互式数据挖掘来说,效率提升比较大。
RDD只能从持久存储或通过Transformations操作产生,相比于分布式共享内存(DSM)可以更高效实现容错,对于丢失部分数据分区只需根据它的lineage就可重新计算出来,而不需要做特定的Checkpoint。
7.Spark on YARN与Spark有啥区别?
让Spark运行在一个通用的资源管理系统(如yarn)之上,最大的好处是降低运维成本和提高资源利用率(资源按需分配),部分容错性和资源管理交由统一的资源管理系统完成。而spark单独是无法有效提高资源利用率。
8.有人觉得,大数据时代,最精髓的IT技术是Hadoop ,Yarn,Spark,您是否体验过?看好哪个?
Yarn不就是Hadoop MapReduce新框架吗,这里为何要单独列出。个人认为当下Hadoop生态体系相当庞大,且技术日趋成熟,Spark还有待发展。如果有一天,Hadoop加进内存计算模型,到时,Spark又会是怎样的处境呢?
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。