国产CPU产品龙芯随着新架构GS464E的披露,外界开始非常期待它倍增的性能,龙芯选择MIPS究竟出于何种考虑,为何今日的龙芯不是基于现在的当红小生一ARM架构?
谈到国产CPU产品龙芯,围绕它最大的争议就是性能。虽然龙芯的早期产品并没有让大家满意,但随着新架构GS464E的披露,以及采用该架构的新一代CPU“3B2000”的正式问世,外界开始非常期待它倍增的性能究竟和Intel的主流产品存在哪些优势和差距。
在前一次《信息科学杂志》给出的数据测试结果中,早期编译的GS464E已经接近Intel、AMD现在市场上的主流架构性能,与Intel Core i3-550和AMD FX-8320基本相当,与Intel Core i5-2300略有差距,同时明显强于Intel Atom、VIA Nano、ARM Cortex-A57等低功耗架构。
而近日,《微型计算机》杂志6月刊中进行了更深入地分析。那么,龙芯的性能究竟到了何种地步,其设计水准距离国际竞争对手还差多远,龙芯选择MIPS究竟出于何种考虑,为何今日的龙芯不是基于现在的当红小生一ARM架构?针对这些外界争论多时的问题,本文将用专业而详尽的分析予以解答。

一黑一白,今日孰是孰非?
坦白来说,龙芯近年来在舆论中受到围攻已经不是新闻,今年初一篇名为《国产龙芯究竟水平如何?》的文章在网上掀起轩然大波,直指号称面向高性能服务器开发的龙芯3B-1500处理器尚不如今日ARM Cortex-A57手机处理器。
耐人寻味的是,不到一个月过后,该文的作者再次撰写了一篇《详解,新一代“龙芯”能否挑战Core i7?》,笔锋一转为尚未正式公开露面的下一代龙芯大唱赞歌。
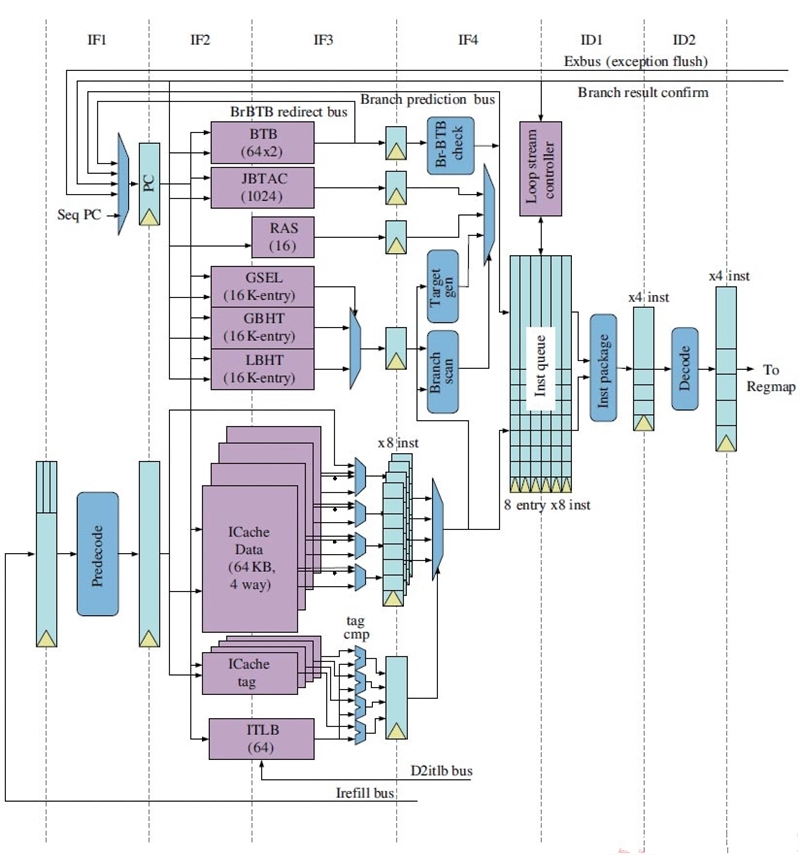
GS464E取指部件
在不诉诸阴谋论的前提下,笔者认为这样剧烈起伏的舆情其实都指向一个事实:对于龙芯的现状,其实外界并不了解,一般公众并不具备从龙芯组公开发表的艰深论文中推断其结构设计水平的能力,亦并不知晓编译器,相关软件系统与所用基准测试程序的偏好,因此对性能的对比也多有偏颇。
例如被抨击为不如Cortex-A57的龙芯3B-1500虽然流片于2012年,但其核心却是2006年左右完成的设计,当时其制定的竞争目标主要是Intel的奔腾3和早期奔腾4处理器,自然会落后于今日的手机CPU旗舰。
而被其描述为可以在IPC上与Ivy Bridge一战的新一代龙芯微结构GS464E,虽然相比上一代产品取得了突破性的进步,但在频率指标取得突破之前,又将凭借什么与Intel抗衡呢?
历史原因 为何选择MIPS指令集?
目前已经推出的龙芯核心主要分为三大系列,型号为GS1XX,GS2XXX和GS3XX,其中GS132系列对标ARM CortexM0和CortexM3,GS232和GS264对标ARM9,ARM11与Cortex-A12,GS464E也就是本文即将介绍的最新版龙芯核心,将对标Intel Ivy Bridge。
先前被认为不如手机CPU的龙芯3A 1000与龙芯3B1500均使用上一代GS464和其向量增强型GS464V核心设计,性能差距较大。
上述所有龙芯系列产品都兼容MIPS指令集,注意这里的兼容并不是如同外界谣传的那样指代龙芯使用了来自MIPS的核心,而是仅仅让龙芯的产品能够运行MIPS所定义的指令集,例如000000在MIPS中代表加法操作码,在龙芯处理器上也代表加法操作码,仅此而已。
硬件方面,从龙芯的微结构到电路、版图设计均为独立自主进行。
很多人也有疑惑,为何龙芯没有选择当下如日中天,隐隐与Intel形成分庭抗礼之势的ARM指令集呢?
其实龙芯项目开始前期调研的时间点是2000年前后,当时ARM的确有被列入考虑范围之内,但是面对龙芯要求实现高性能的初始目标相比,ARM公司的定位则显得不合时宜,彼时的ARM能拿出的最强核心设计是ARM11,没有乱序执行,没有多发射,没有今天这样先进的缓存系统。
ARM旗下第一款支持双发射的Cortex-A8设计是2005年才对外公布的,在此基础上加入乱序执行的Cortex-A9则更是到2007年前后才宣告面世。这倒不完全是因为ARM在高性能设计上实力孱弱,而更多地是因为ARM将自己的产品定位为面向嵌入式计算的产品,极为紧张的面积和功耗预算使得许多高性能设计上常见的特征难以实现。随着技术的进步以及嵌入式计算能力需求的暴增,ARM才开始着手打造高性能CPU。
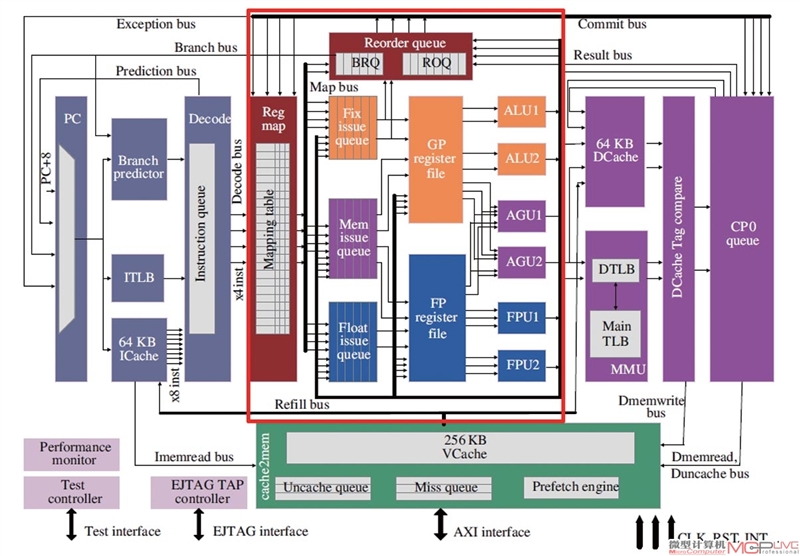
GS464E微结构框架图,红色方框部分为乱序执行引擎
上世纪90年代,MIPS和DEC Alpha等几大厂商都于1995年前后陆续实现了乱序四发射的设计,风头甚至压过当时的Intel、MIPS的R4000、R10000以及DEC Alpha 21164。
其中21264放眼今日仍然是有志于处理器微结构设计的后学晚辈们所必看的经典之作,深度流水线,分支预测,寄存器重命名,Load-Store推测,一应俱全。虽然在90年代后期MIPS和DEC Alpha逐渐式微,但虎落平阳余威犹在。在x86阵营经营多年的专利壁垒无法攻破的情况下,高性能CPU厮杀的战场上为当时蹒跚起步的中国CPU提供的选择着实不多。
以当年的情况看,ARM在多年内都无力进攻嵌入式以外的市场,这意味着ARM的指令集系统在嵌入式以外几乎等同于无根之水,没有人会愚蠢到量产基于ARM11的个人电脑和服务器。单纯凭借一个国产项目力图对抗wintel联盟的铁桶江山与蚍蜉撼树别无二致。
而与Intel正面交战过并且曾经享有胜者头衔的MIPS和DEC Alpha所留下的软件生态环境自然要比ARM强大许多,国内先后上马的龙芯和申威两大拥有政府支持的CPU项目就是分别采用了MIPS与DEC Alpha指令集。
因此笔者认为,在坚持高性能设计并且想要获取市场支持的前提下,选择MIPS/DEC Alpha是一个正确的决策,以今日ARM的崛起来拷问当时的选择难免有马后炮的嫌疑,无人能够超越历史局限预估到十年之后的未来。
正像无人能够预见到2000年正踩在钢丝线上生死未卜的苹果公司能够在十年后登上浪潮之巅一样。但是历史终究已成历史,今日龙芯面临的困境也是众人皆知的,那么龙芯团队能不能实现自己当初的目标,他们拿出的新一代GS464E又是什么样的呢?
喜忧参半 新一代GS464E架构之前端取指
纵观全局,取指部件是新一代龙芯GS464E中改动最大的几个地方之一。大体框架上,一级指令缓存(取指部件图的下半部分)为了追求速度被设计为并行访问的结构,在IF2阶段和IF3阶段同时读取指令(IC Cache Data)和相关的地址标记(IC Cache tag),在IF4阶段判断是否命中,取出命中的指令。从取指部件部分的框架图来粗略判断,前端部分的效率仍是喜忧参半。
令人欣喜的地方有三个,在这三个方面龙芯GS464E的结构设计都达到甚至超越了国际水准。
第一,指令缓存的大小达到了64KB(四路组关联),超越了IBM Power7的32KB(四路组关联);
第二,取指宽度已经达到了每周期8条指令,考虑到龙芯以MIPS32作为基础指令集,以每条指令32位宽计算,一级指令缓存的取指宽度达到了每周期32字节,而Intel Haswell处理器的一级指令缓存仅能达到每周期16字节的吞吐率(但存储解码后指令的uop cache能达到32字节/周期的吞吐率);
第三,GS464E也加入了Intel从SandyBridge期间开始配备的循环检测器和循环指令缓冲区,这种结构设计允许CPU在不断取指令的同时,去识别哪些指令构成了一个循环,在发现循环再次出现的时候关掉指令缓存,仅从循环缓冲区中取用。笔者相信GS464E的循环缓冲区设计从Intel的SandyBridge中获取了一些灵感,巧妙地把它与负责解耦取指部分和解码部分的Instruction Queue做成了一个模块,与SandyBridge一样支持存储56条内层循环指令。
而令人担心的地方也有三个——
第一,当一级指令缓存发生缺失时,缺失的地址会送给缓存失效队列进行处理。引入缓存失效队列(学界通称为MSHR)来负责从下层存储器取出缺失的和即将使用的预取数据本是早已成为标准配置的做法,但龙芯的缓存失效队列却由一级指令缓存和一级数据缓存共享,并且这个失效队列仅有16项,意味着仅能存储16个失效请求。笔者预计龙芯此后的设计将会尝试将失效队列分离或是提高容量;
第二,从框架上看,GS464E的指令TLB部分距离国际水准仍有差距,Intel在Sandy Bridge微架构上就实现了144项四路组关联的一级指令TLB,AMD的Bulldozer也实现了72项全相连一级指令TLB和512项四路组关联TLB的搭配,而龙芯仅有64项全相连一级指令TLB(一级指令TLB的大小较难提升),且并未出现二级指令TLB的设计,指令TLB覆盖范围的弱势可能会加剧指令缓存缺失之后的性能损失;
第三,IBM Power7的一级指令缓存部分与龙芯颇为相似,但是加入了先行路选择技术,推测性地只开启指令缓存中将要被访问的一个部分而不是全部,从而削减功耗,在此之外又非常激进地将一级指令缓存切分为16个bank,尽量避免读写冲突。而龙芯的指令缓存部分并未提及路预测技术的加入,也仅仅切分为4个bank。综合优势与劣势来看,尚不能简单断言龙芯的取指令效率能够比肩国际主流水准。

可以看到Victim Cache在GS464E处理器架构上占据了不小的空间
再来看前端中另一个不容忽视的模块—分支预测器。GS464E的分支预测器经过大幅改造,不难看出是投入了血本、大幅度提高了各项规格。从表面参数上来看,它已经能够比肩Sandy Bridge的水准—锦标赛分支预测器,返回地址栈,间接跳转预测器,一应俱全。
锦标赛分支预测器有三大主要内建部件—专门根据局部历史预测分支走向的局部历史表(Local Branch History Table),专门根据全局历史分支走向的全局历史表(Global Branch History Table),以及专门负责决断前两者哪一个准确率更高的全局选择表(GSEL)。三者的存储空间都达到了16K项的大小,推测与Sandy Bridge齐平,也超过了IBM Power7。
专门负责预测函数调用返回地址的返回地址栈(Return Address Stack)能够存储16项,与AMD Jaguar和IBM Power7齐平。在基本参数已经追平国际水准的情况下,比拼分支预测准确率的因素就落在了其他细节设计上,例如返回栈是否支持在错误预测下的栈修复、锦标赛预测器是否加入了其他设计技巧降低历史表的访问冲突等等。
笔者谨慎乐观地认为,只要这些细节设计不出现明显失误,GS464E的分支预测能力将可以与Intel的设计一决雌雄。
仍有落后 新一代GS464E之乱序执行引擎
尽管同为乱序四发射的框架,但从表1来看,GS464E的乱序执行引擎部分的基本参数相比Intel的Sandy Bridge仍有显著落后。
首先,重定序队列(Re-Order Buffer,ROB)决定了乱序执行引擎能够从多大的指令范围内抽取指令级并行度、挑选不相干指令进行乱序执行。而整数物理寄存器数量决定了最多容纳多少次整数寄存器重命名,在这些参数上龙芯仍有较大差距需要追赶。
除此之外,龙芯在发射队列上还是选择了设计难度较小、容易提高容量、但是也容易导致资源配置不均衡的分离式发射队列设计。AMD和MIPS历史上都曾使用过这种设计,在这种设计里面所有允许乱序执行的指令都是分类型分开存储的,比如整数指令存储在自己的独立发射队列中,浮点指令存储在另一个独立发射队列中,碰到整数密集型的程序把整数队列占满了之后,浮点发射队列可能是全空的。
与之相对的设计是集中式发射队列,集中式的发射队列设计复杂,极难大幅提高容量,但是所有的指令都存储在同一个地方,避免了空置的情况,这是与分布式发射队列不同的权衡。
在这种设计上,Intel已经浸淫多年,Intel的第一代乱序多发射微结构P6就是采用集中式发射队列,从Pentium4的Netburst开始改成了分布式发射队列,从Core开始又改回了集中式发射队列,并一直坚持至今,堪称是集中式发射队列设计的忠实拥簇。
在Core时代,Intel的集中式发射队列容量仅为32条指令,而AMD的K8所配备的分布式发射队列的总容量达到了60条指令,几乎多了一倍,但强大的Intel硬生生地将自己的发射队列容量逐年提高,终于在Haswell上实现了72条目的集中式发射队列和8发射端口的设计。在不存在并发条件限制的情况下,单单这一个集中式发射队列每周期就可以分派8条允许乱序执行的指令到各个执行单元,可谓是集中式发射队列的登峰造极之作。
龙芯在论文中并未透露自己的分派宽度,但从发射队列和执行单元的配置来看,笔者估计可能在4~6条指令之间。

当然,在具体的细节上,龙芯GS464E这一边的设计也有值得称道的部分。所有频繁触及的执行单元都能够单周期完成操作,并通过激进的数据前递设计在数据依赖的情况下支持背靠背发射,访存流水线支持访存指令的推测性发射和指令回放(一种较为困难的访存优化技巧,可以缩短访存延迟)。
更值得称赞的是,物理寄存器堆(PRF)和基于指针的发射队列处理逻辑也被早早地引入,这是一条曾经被Intel放弃的路线,后来为了引入AVX指令集又不得不选择相同做法,龙芯非常聪明地避开了Intel曾经走过的弯路。
但是这些细节改进并不足以帮助GS464E在乱序执行能力上叫板Core i7,龙芯需要再花费多长时间才能达到Haswell的乱序执行引擎的设计水平,就要看龙芯的物理和电路层设计水准能不能够撑得住规模更大的发射队列、更加复杂的数据前递网络以及支持更多并发读写口的物理寄存器堆,这些关键结构是支撑乱序执行引擎的设计重点所在。
容量充足 新一代GS464E之缓存系统
GS464E的一级数据缓存部分与指令缓存同为64KB,四路组关联,但是改成了串行访问设计,亦即先访问地址标记阵列(Tag Array),确定命中后再访问数据阵列(Data Array)。这种设计的意图是牺牲几个周期的访存延迟带来更低的访存功耗,但在GS464E可以维持4周期的一级数据缓存装载至使用(load-to-use)延迟的情况下,这个代价是可以接受的。
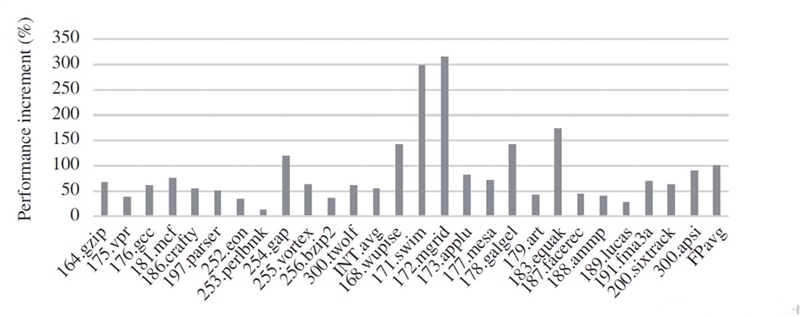
从更为可靠的SPEC CPU 2000测试来看,相对于上代龙芯3A,GS464E的处理器性能在一些子项测试中的提升幅度可达到最高300%以上。
比较有趣的是一级数据缓存之下的部分,每个GS464E核心在一级缓存下还有一道独立缓存系统,龙芯组将它称之为Victim Cache。
一般来说Victim Cache是附在一级缓存边的一个小Cache,仅能存储极少容量,主要为了接住被一级缓存踢出的数据,并在急需时快速传回它们。而龙芯的Victim Cache却有256KB,从术语约定上来说这就已经不是Victim Cache,而是正统的私有二级缓存。称呼它为Victim Cache的原因应该是因为这一道缓存与一级缓存之间是互斥式设计,亦即出现在一级缓存中的指令和数据在二级缓存一定没有备份。
作为参考,AMD也使用了相同的互斥式设计。而Intel和IBM则坚持包含式设计,亦即一级缓存中出现的内容在二级缓存中一定存在,这两种设计方式主要会影响到缓存命中率以及多核情况下的缓存一致性维护,各有优劣。
包含式设计的优点是简化了多核心计算下的同步问题,因为一级缓存中的数据保证在下层中存在,所以查询数据同步状态时只需要询问下层存储器即可,但缺点也非常明显,就是浪费了缓存空间,因为多层缓存都保存了多份同样的数据副本。而互斥式设计避免了空间浪费,但是每次处理多核心同步时都要检索整个多级缓存体系,让多核心的一致性问题变得更加复杂。
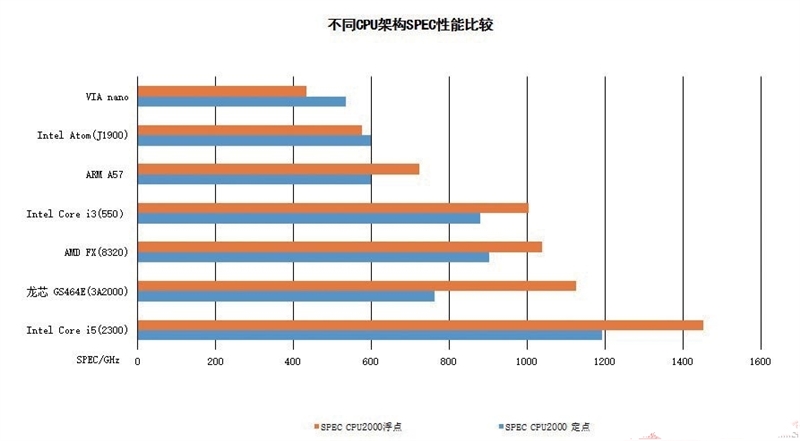
而从最新公开的测试数据来看,在同位1GHz频率下的环境里,GS464E架构的性能已经在浮点性能上超过AMD FX -8320,接近采用Sandy Bridge核心的Core i5 2300。
龙芯的二级缓存采用16路组相连设计,使用与一级数据缓存相同的串行访问模式,龙芯的论文中称这道缓存系统采用LRU替换算法,笔者认为这可能属于笔误,或者论文撰写者与缓存模块实际设计者双方出现了沟通不畅。
因为16路组关联如果要采用LRU替换算法就需要维持一个16!的状态数=20922789888000的状态机,这显然是无法实现的。历史上也从来没有超过四路组关联设计的缓存搭配了LRU替换策略,GS464E这里采用的应当是一个经过简化的伪LRU算法。
需要指出的是,采用伪LRU算法这并不是一个性能缺陷,好的伪LRU算法的替换准确率与LRU相差无几,在真LRU无法实现的情况下,所有超过四路组相连的缓存设计都是采用了伪LRU替换,Intel、AMD、IBM概莫能外。
在这个Victim Cache之下,还有最后一道被称为SCache的片上共享三级缓存,这一级缓存仍旧是16路组相连,每个SCache模块是1MB大小,四个核心的SCache模块拼接起来就是4MB。一般而言末级缓存系统都是切分多个Bank之后通过挂接到Crossbar上,各个独立核心通过Crossbar访问共享的末级缓存。龙芯将SCache直接挂接到GS464E核心外,可能说明龙芯已经采用了一些NoC(Network on Chip)的设计思路,在为未来扩展多核、众核做准备。
值得称道的是,龙芯的二级、三级两级缓存都维持了较大的容量和组关联度,但是访问延迟较长,二级缓存的访问延迟超过20个周期,比Intel处理器的二级缓存相比慢了几乎一倍,三级缓存需要超过50个时钟周期的时间,与Intel处理器基本持平。
同频性能接近Sandy Bridge实测数据分析
龙芯目前公布的实测数据主要是在RTL仿真以及硬件加速仿真验证平台上取得的,设定频率为1GHz,如果实际芯片能够运行在1GHz上,并且接口时序设定正确,它们和实际芯片运行性能是没有什么差别的。
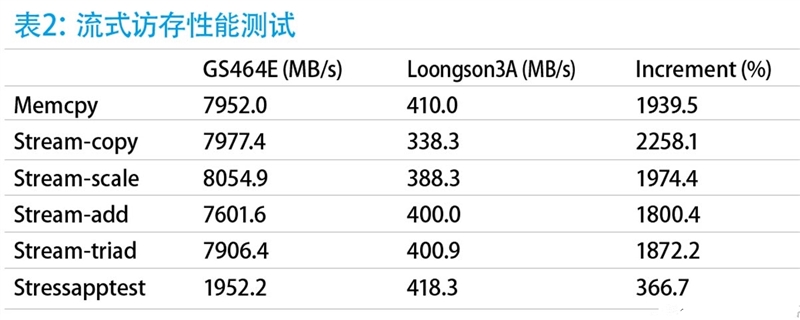
从表2可以看到,龙芯GS464E号称访存性能即内存性能提高了10~20倍。据悉前代龙芯过于注重核心微结构,内存控制器设计则过于轻视,甚至连突发传输模式的支持都没有做好,因此内存性能非常低下。而这一次流式访存性能暴涨则也是因为修正了内存控制器的bug,同时加上了激进的多级预取机制的结果。以Memcpy和Stream-Copy两个测试子项来看,龙芯的内存控制器在操作双通道DDR3-1000时,在局部性较好的流式访问上距离Ivy Bridge + 单通道DDR3 1333的平台还有20%左右的差距。
同时龙芯公布了Whetstone,Coremark,Dhrystone等几个小型benchmark的测试结果,如表3所示。一般来说这几个测试结果的可信度不如Spec,PARSEC等大型测试程序。但是这种小型测试能够轻松地在龙芯RTL测试平台上运行,该测试平台可以给定静态时序分析结果,并通过RTL代码仿真一颗芯片,而无需流片,使用更加方便。
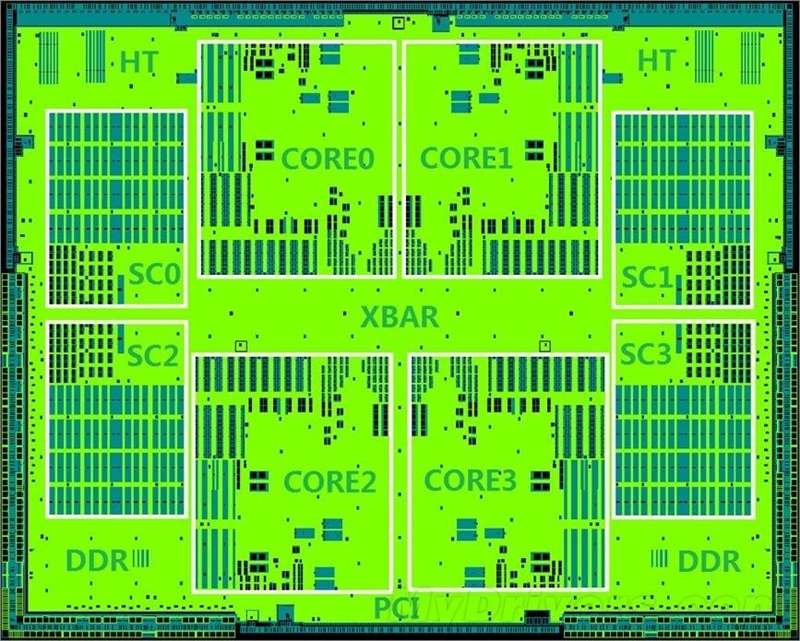
龙芯3A2000/3B2000的设计版图
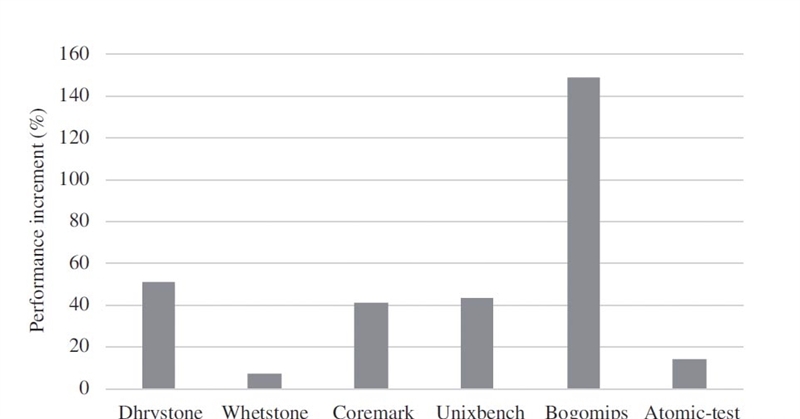
在其他程序测试中,GS464E处理器架构在分支指令较多的Dhrystone,以及少量访存操作的Coremark等测试中有40%以上的性能提升。
所幸龙芯还公布了Spec CPU 2000的测试结果,如表4所示目前GS464E在1GHz频率下的整数性能得分为762,相对上一代涨幅104%左右,浮点性能达到1125分,提升幅度更加惊人,达到278%。其整体性能已经非常接近同为1GHz频率,采用Sandy Bridge核心的Core i5 2300。
若以Spec CPU 2000的初步测试结果作粗略估计,龙芯的IPC还是比较乐观的,但从另一面看龙芯还不能提前开香槟庆祝。从最新披露的消息来看,基于GS464E架构的龙芯处理器主要有3A2000、3B2000两种。其中龙芯3A2000为单路四核桌面版本,龙芯3B2000则是支持双路八核、四路十六核的服务器版本。
由于是新架构的第一版产品,制造工艺仍旧是40nm,主频只有1GHz左右。考虑到频率只有当今Intel、AMD处理器的1/3,因此新一代龙芯处理器总体的绝对性能大约仅为Haswell的20%~30%左右。何时能采用更先进的28nm工艺生产,能否在新架构上大幅提升工作频率?还是一个大大的问号,龙芯仍有比较长的路要走。

结语:成功不可能一蹴而就
据笔者了解到的消息,龙芯目前已经打入了军方和航天市场,这两个市场都对安全性极为重视,性能要求则相对比较宽松,龙芯的抗辐照版本问世后也装上了北斗卫星。中国那段由国家领导人亲自出马谈判进口抗辐照芯片的过去可以宣告埋入历史尘埃了,但龙芯要在民用市场上对抗Intel和AMD还是很难,毕竟绝对性能上差距过大,在短期内恐怕仍无可能。
龙芯项目启动迄今已过十五年,有过明察秋毫拒绝使用超长指令字结构的睿智,但也同样有过不知深浅“一步到位”的狂热;有过在媒体上放话打败Intel的自负,也有过公开承认性能差距过大的诚恳,这些都已经是龙芯成长历程中被凝固的笔墨。
时过境迁,笔者认为,对待今日龙芯的进步,我们需要抛开过往,保持足够冷静和理智,如计算所的前任所长李国杰院士2004年就在《科技日报》上撰文指出的那样:
“我国CPU/SoC设计任重道远”,“今后若干年内,龙芯CPU的性能只能做到国外最高水平CPU性能的一半左右”,要时刻清醒地认识到在这个国外已经发展超过五十年(以乱序执行发明的时间计算)。有十万至数十万顶尖水平从业者支撑的行业里面,龙芯以区区数百人的规模和几十分之一到几百分之一的投入做到几分之一的性能已经足堪自豪,至于追平和赶超,还是需要耐心。
不久前中国计算机协会举办的走进龙芯活动中,龙芯项目负责人胡伟武坦诚“乞丐与龙王比宝,越比越落后”,希望“重视整机性能,在每一个局部都不如别人的情况下实现整机性能的反超”,龙芯目前已经将自己走向“支柱型CPU产业”的规划划到了2020~2030年,这将会是一场旷日持久的大战。

如果成功了,中国CPU产业将多出一位内能自给自足,外能力拼英美的巨头,即便失败,以龙芯项目这些年的投入,以及作为第一个国产乱序多发射高性能CPU的先驱所贡献的经验和培养的人才来说,亦是能够有所慰籍的。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。