就艺龙而言现在系统规模较小,每天产生160GB,360是500GB/天,百度离开太久了就不清楚了。这个数据量还是稍微比较大的,就是这个系统是人为造的DDoS系统,每个监控端采集项目,我们在艺龙比较少,这种比较少,每个服务器上监控项大概二百多个,默认的频率是5
1、 监控系统架构
经历了许多公司,监控系统大概都是从无到有,该经历的也都经历了。所谓监控系统,大概的架构如下:
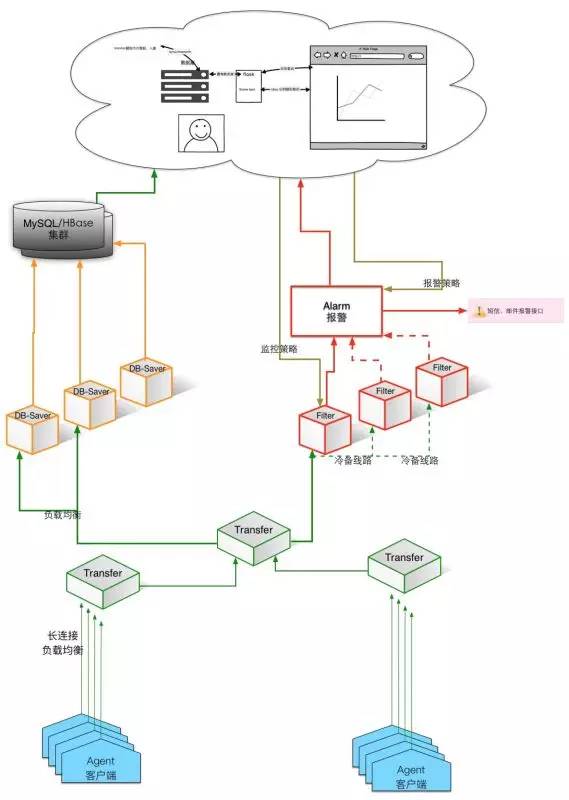
◆在服务器布置一个Agent,它负责采集数据;
◆由网上转发到一个分布式管道再转接,就像搭积木一样;
◆进行汇总;之后把监控数据分两个部分
●一是数据库存储,主要做监控数据展示和后续排查问题。
●二是制定很多的监控的报警项。
做一些简单的,像CPU超过90%就会报警;还有一些复杂的,像60秒之内超过两次。后来也会支持一些集群类的报警监控。这个模块也是很简单,它主要就是在若干的文件的公式,然后进行监控数据的判断,判断之后发现了异常,就会产生一些消息,然后上一个模块。我们只是进行判断,不进行报警。之后会有一个模块进行各种后端的报警,像现在一些公司 有微信报警、短信报警等等的,都在这部分支持。
◆存储部分
豆瓣、百度、360等等,后端琐碎的事比较多,但是也有用MySQL的。实际上这部分也很简单,可以认为是一个分布式的Linux,就是把一些数据往文件数据库里传,上面是一个WEB端。以上是大概架构。
2、 设计思路

◆每一个模块就干一件事,把这件事干得精细和优秀。
●之后会细化一下模块里的具体内容。
●要scalable,flexible,可以任意横向扩展,适应各种防火墙ACL。
●在360的时候机房比较多,各种防火墙的ACL非常多,360下还有很多子公司,会出现各种访问的现象。要适应各种系统,就会通过一些模块来适应。
◆注重代码复用。
一套系统除去网络框架,每个模块的代码都在100行,而且是C语言写的。我们最后把这个网络框架都做在了一个网络库,这个是多线程的。
3、 这个系统面临什么难点?

技术量。
就艺龙而言现在系统规模较小,每天产生160GB,360是500GB/天,百度离开太久了就不清楚了。这个数据量还是稍微比较大的,就是这个系统是人为造的DDoS系统,每个监控端采集项目,我们在艺龙比较少,这种比较少,每个服务器上监控项大概二百多个,默认的频率是5秒钟一次的采集点。可以说每秒钟大概有40多条数据的采集。
这个系统基本上不能做Cache,必须实时运算。因为服务器监控系统,我们做服务端应该都知道,延迟报警,还不如不报。报警一旦出了问题,就要尽可能快的把这个东西报出来。除非是一些不可控的因素,如短信网关,或者运营商短信发送延迟等。结论是,90%都要在15秒之内保证大家手机能收到。这对我们在各种环节下尽量减少各种各样的延迟什么的提出较高的要求,换言之,高可用。这种监测系统作为一种服务器的基础架构存在,可用性必须比线上高,因为它发挥最大作用的时候都是公司出了大问题的时候,这个时候必须要扛的住各种各样的网络情况,把真实的情况反馈过来。对于这种线上的可用性要求高于线上服务至少一个数量级。像CPU连续5次90%不报警,如果我们这个数据里有任何丢点,可能会导致报警报不出来。因而对于数据的完整性要求也是比较高的。就是在任何一个模块宕机或者网络隔离,这种情况下也不允许出现任何的丢失。
高吞吐。
因为这个系统是典型的写的比较多,读非常非常随机的过程。读取决于大家对数据项的查看,汇总,画图的需求。所以基本上一个月之内的数据需要随时的调出来。高吞吐也是我们面临的主要问题。
多平台。
百度用的是Linux,Windows用的比较少。百度的挑战在于机器比较多,像千分之一的情况在百度基本每天能出个一百台。之前我们同事做过一个分享,就是说一些经验。在服务器吞吐量特别大的时候,千分之一的情况也要考虑。360是FreeBSD。艺龙是Windows,大约占服务器的一半。
4、解决方案

针对数据量,HBase,自定义协议减少Overhead。数据量这个问题不大,用的技术在于说,监控数据的传输,根据一些私有的协议,也是一些历史原因,当时用Json很多。也尝试过用别的,但是对监控系统有时候,比如出丢点,像追的时候Json可以,用别的就追不上了。
高实时。对等多线程异步非阻塞、实时计算、长连接。我们这个系统不能用一些很高延迟的东西,比如说卡罗普你想都不用想了,还有像现在比较火的流式系统,所以也没有采用。
高可用。我们这个系统不能有单点,而且有一个要求,你是同一个机房,不能降级。就是如果这个机房停电了,这个机房不监控也罢,但是你得知道它停电了。但是剩下的机房必须保证监控没有受到任何影响,而且还要保证15秒这个事。这是我发明的词,“惰性智能选路”这个其实也很简单,什么叫惰性呢?像网络挂了,连不上了,我们Agent可以连到别的上,这个很简单,就是我们想办法让Agent让它知道有这个的存在,我们不用DS传统方式。我们启动的时候,或者哪儿出了问题,我们拿到另外一个连,这个策略非常简单,但是这个东西作为一个接口,以前的Agent,由于网络断了会试下一个,就是最终会迁移到离它最近的,网络状况最好的,就是很默契的达到智能,而不用考虑它跟谁连接。同样的,下游往上游发的时候也是用的相应策略。还有高可用,我们要保证这个数据不能丢。就是有一点必须要保证,就是这个监控数据由于第一手拿到的都是本机的一些Agent,这个Agent必须保证数据到了让报警的那个模块拿到。我们这个就是Agent拿到这个数据之后,翻译的这个模块只会进行转发,上面的收到确认之后传过去,最后再给。保证这个数据一定到了上游。由于这种东西的强保证,所以说也会导致性能上的困境,就是说我们要保证数据不丢,又要保证高性能,这后面我们再说这个是怎么做的。
高吞吐。cache,还是cache。没有什么好说的,觉得一般cache能解决的高并发都不是难点。
多平台。当时我们做这个的时候golang还没出来,所以都是用的C++。时间计数器一出问题什么都出了问题,时钟不好了,定时器到计算性能全都完蛋,Windows是一个非常坑的平台,后来幸亏有了golang,避免了Agent只能找非常厉害的人写的局限。
5、 如何优化性能?

◆zlib流式压缩
这个写起来没那么好弄,但是听起来挺简单的。
◆pipeline滑动窗口
●之前说从Agent采集到数据,经过层层模块转发,这样就会导致请求和回应的延迟会非常大,在大延迟的情况下怎么保证高吞吐量,于是发数据的时候,比如在翻译模块都是进行批量转发,那边回一个Ok。工程师说,在应用层又造了一个TTP,这个东西比较无聊。
◆协议改造,Protobuf
◆数据合并
◆function-filter优化,当时优化也走了很多弯路:
●profiler,现在CPU行为不是教科书里说的那些东西,现在CPU的架构体系不是常人能理解的了。我们的想法是各种都去尝试,最终选择好用的。
●分布式改造,这个容易降低速度,最终没有再尝试。
6、走过弯路的感想

所谓简洁即可靠,我们曾经做这种东西的时候,就是关于数据转发和怎么弄曾经做了一些版本,也走了一些弯路,慢慢发现搞的越复杂坑越多,特别是在限制要求特别高的情况下,最后返璞归真,不断优化,出来的就是每个模块极其简单,感觉就是分布式管道,都可以在linux系统里找到影子。做到简洁,因为有的模块,我们写代码都知道,从产品来看,就是从这儿到那儿。写代码如果在设计上复杂化,很多东西都绕,加班加点也不一定能搞明白。因此现在艺龙考虑的就是从简洁出发,不要搞复杂的东西。
结语:十万级服务器监控系统开发架构尚可继续完善,愿来日更上一层楼。
关于作者:
王鹏程艺龙技术架构总监曾于实习期间加入豆瓣,后在Baidu从事自动化运维开发,参与了Baidu运维自动化从无到有的过程。后加入360,负责过360运维自动化平台的架构设计及框架开发,从零开始负责构建了360天机、360流量卫士等移动端产品。擅长服务端、Android底层、分布式系统开发。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。