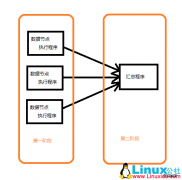
1 概述Zookeeper分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。 ZooKeeper本身可以以Standalo
简介Hadoop中的NameNode好比是人的心脏,非常重要,绝对不可以停止工作。在hadoop1时代,只有一个NameNode。如果该NameNode数据丢失或者不能工作,那么整个集群就不能恢复了。这是hadoop1中的单点问题,也是hadoop1不可靠
hadoop学习过程中,我们会遇到各种各样的问题,常见的有hadoop无法启动,集群不能正常工作,不停跳出报错信息等等,这里总结了常见的几个问题及除了方法,希望对大家有用。

启动Hadoopstart-all.sh关闭HADOOPstop-all.sh查看文件列表查看hdfs中/user/admin/aaron目录下的文件。hadoop fs -ls /user/admin/aaron列出hdfs中/u
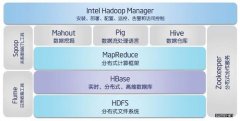
本文将分析Hadoop MapReduce(包括MRv1和MRv2)的两种常见的容错场景,第一种是,作业的某个任务阻塞了,长时间占用资源不释放,如何处理?另外一种是,作 业的Map Task全部运行完成后,在Reduce Task运行过程中,某个Map Tas
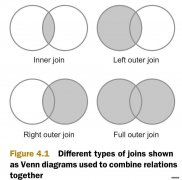
MapReduce的连接操作可以用于以下场景:用户的人口统计信息的聚合操作(例如:青少年和中年人的习惯差异)。当用户超过一定时间没有使用网站后,发邮件提醒他们。(这个一定时间的阈值是用户自己预定义的)分析用户的浏览习惯。让系统可以基于这个分析提示用

最近抛弃非ssh连接的Hadoop集群部署方式了,还是回到了用ssh key 验证的方式上了。这里面就有些麻烦,每台机器都要上传公钥。恰恰我又是个很懒的人,所以写几个小脚本完成,只要在一台机器上面就可以做公钥的分发了。首先是生成ssh key脚本:ss
2014年3月13日,CSDN在线培训第一期“用SQL-on-Hadoop构建互联网数据仓库与商务智能系统”圆满结束,本次培训讲师是来自美团网的梁堰波,在培训中梁堰波分享了目前在互联网领域数据仓库和商务智能系统构建的业务需求和解决方案,
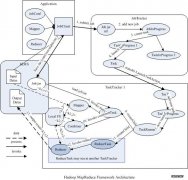
在Apache Hadoop的起步阶段,主要支持类似搜索引擎的功能。如今,Hadoop已经被数十个行业采用,它们依靠大数据计算来提升业务处理性能。政府、制造业、医疗保健、零售业和其他部门越来越多的从经济发展和Hadoop计算能力中受益,然而受到传统企业解决方案
项目中在私有云中使用CDH (Cloudera Distribution Including Apache Hadoop)搭建Hadoop集群进行大数据计算。作为微软的忠实粉丝,将CDH部署到Windows Azure的虚拟机中是我的必然选择。由于CDH中包含
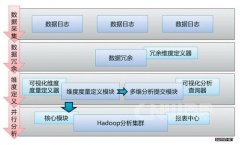
一、硬件环境Hadoop搭建系统环境:一台Linux ubuntu-13.04-desktop-i386系统,既做Namenode,又做Datanode。(ubuntu系统搭建在硬件虚拟机上)Hadoop安装目标版本:Hadoop1.2.1jdk安
Hadoop的概念随着大数据时代浪潮的到来,已经变得不那么陌生,在实际应用中,如何为Hadoop集群选择合适的硬件成为很多人开始使用Hadoop的一个关键问题。在过去,大数据处理主要是采用标准化的刀片式服务器和存储区域网络(SAN)来满足网格和处理密集型工
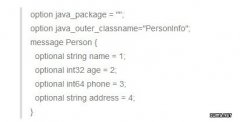
Hadoop Streaming是Hadoop提供的多语言编程工具,用户可以使用自己擅长的编程语言(比如python、php或C#等)编写Mapper和Reducer处理文本数据。Hadoop Streaming自带了一些配置参数可友好地支持多字段文本数据的处
在 Hadoop 中有一个抽象文件系统的概念,它有多个不同的子类实现,由 DistributedFileSystem 类代表的 HDFS 便是其中之一。在 Hadoop 的 1.x 版本中,HDFS 存在 NameNode 单点故障,并且它是为大文件的流式数据
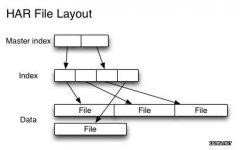
小文件指的是那些size比HDFS的block size(默认64M)小的多的文件。如果在HDFS中存储小文件,那么在HDFS中肯定会含有许许多多这样的小文件(不然就不会用hadoop了)。而HDFS的问题在于无法很有效的处理大量小文件。任何一个文件,目录






