在传统的两地三中心的方案里面,异地的备份是要做能切换的应用级备份,而支付宝作为第三方支付机构,对于灾备和业务连续性的重视和灾备目标等同于银行。

5月底的那波运维故障余波未了,端午期间阿里云的香港机房又出现了电力故障,很多金融圈的小伙伴纷纷关注和讨论数据中心的灾备方案。同时,《大话存储》的作者张冬写了一篇《浅谈容灾和双活数据中心》,从底层和硬件实现的角度深入解析了容灾和双活的原理和观点,张冬说的“浅谈”是谦虚,对底层原理的阐述再浅也不容易。我这篇浅谈真的是浅谈了,换个角度,从应用和业务的角度,谈谈我对灾备和多活架构演进的一些体会与观点,更多的是还是抛砖引玉。
一、过去:集中式架构下的数据复制
国内的灾备体系建设,起源和最受重视的都是金融行业。 2005 年 4 月:国信办发布了《重要信息系统灾难恢复指南》,是国内第一份针对灾难恢复的指南文件。 2008 年2 月:中国人民银行发布了《银行业信息系统灾难恢复管理规范》( JR/T0044-2008),是国内金融行业发布的第一份针对灾难恢复的金融国家标准。到 2011 年 12 月,银监会《商业银行业务连续性监管指引》【 2011 】( 104 号)的发布,标志着国家和行业监管部门对灾备的重视程度已经提升到了一个新的高度,从单纯 IT 领域的容灾备份上升到了保障业务持续运行的层面,业务连续性管理( BCM )成为了一个专业领域受到广泛重视。
技术架构层面, IBM 引入的“两地三中心”概念和架构成为了灾备的代名词,标准做法是北京上海建两个生产数据中心,再在其中一个城市建一个专门的灾备中心,满足生产和灾备相隔 1000 公里以上监管要求。过去金融行业普遍采取的是集中式架构,也就是今天常说的“ IOE ”架构,核心业务数据通过集中的数据库,最终写入到集中的存储中去。因此,“两地三中心”的灾备方案就通过数据库的数据复制或者存储的数据复制技术,在广域网上进行数据的复制,最核心的三个要素是:数据库、存储、网络。
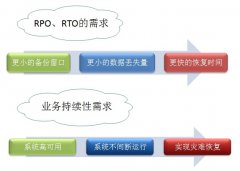
这种灾备体系体系架构的优点和缺点同样显著。优点是基于数据库和存储的复制技术的通用性很强,对于应用透明。缺点是这种备份还是数据级别的备份,在 RPO (Recovery Point Objective ,企业能容忍的最大数据丢失量)和 RTO ( Recovery Time Objective ,企业能容忍的恢复时间)这两个指标中间,更强调的是数据安全。因此,往往投入巨额资金建设的灾备中心,只能用于冷备,也叫单活,在需要的时候由人工手工切换生产和灾备中心。
这种集中式架构下的数据复制架构,形成很多年了,虽然说是过去,但到今天为止仍然是主流的做法。
二、现在:论数据复制的异地多活不可能定律
在过去两地三中心的架构下,大家的普遍痛苦是建一个灾备中心容易,维护一个灾备中心太难了。在单活模式下,为保持生产和灾备中心的设备比例,需要不断的追加灾备的硬件投入,对于备份数据的有效性、恢复的及时性也要不断的进行验证演练,同时,出于对灾备切换之后的数据丢失风险的考虑,不到万不得已,企业是不敢贸然切换。因此,传统的灾备体系就和核武器一样,是最后一道防线,不得不建,但建完之后,维护成本非常高,能用到的机会非常少,投入产出比很低。
在这样的情况下,数据中心多活很自然的成为大家的追求目标,如果能和服务器集群一样,多个数据中心能同时提供服务,灾备中心也同时承载生产中心的职能,自然是最好的灾备解决方案。多活方案看上很美,但早在 2008 年,我们在支付宝建第一个灾备中心时,就发现基于数据复制异地多活数据中心是不可能实现的。
1. 数据库的多活模式。 如果通过数据复制的方式,就意味着需要实现双向数据复制,并通过数据加锁的方式解决两边的写冲突,无论是数据库实现还是存储实现都会带来性能的急剧下降,对于联机交易系统是不可接受的。
2. 数据库单活、应用多活的模式。 数据库采用传统单活容灾模式,让应用通过网络访问远程的主数据库,实现应用层面的多活,这是一个看似合理的解决方案,也是当时支付宝灾备的建设目标。当时相隔 100 公里的机房的光纤网络延时是 2 毫秒,认为能满足应用对数据库的访问。但是真正实施时,才发现应用和数据库之间请求过于频繁,一个事务中间往往高达 10 多次交互,总体延时累加之后就发现性能无法支撑。这个结果,对于实时性要求很高的联机交易系统还是不能接受。
时隔几年之后,今天又有不少厂商在宣传基于产品实现的异地多活数据中心方案。虽说技术发展很快,但我们对此可以有个简单的判断:不管基于什么方案,数据复制都是依赖网络的,网络带宽可以不断的扩大,而光纤网络随着距离的增长带来的延时问题是物理学上的限制,除非找到比光速更快的介质,否则在依靠底层数据模式下不可能找到多活的解决方案。
三、现在:互联网思维下的灾备创新和技术突破
基于以上的认识,支付宝在第一个多活数据中心的方案尝试失败后,很快以互联网思维寻找新的解决方案。我们发现,在传统的两地三中心的方案里面,异地的备份是要做能切换的应用级备份,而支付宝作为第三方支付机构,对于灾备和业务连续性的重视和灾备目标等同于银行,但当时的监管要求没有银行那么明确。因此,首先从业务的目标出发,对传统的灾备思维进行了革新,找到了创新的灾备解决方案:同城多活加异地数据灾备。
该方案主要依赖于以下几个因素:
1. 同城多数据中心。 在光纤延时的问题上,既然异地的网络延时无法解决,就绕过该问题。依托于阿里在杭州的企业骨干网,将同城多个机房通过裸光纤连在一起,发展同城多中心。在裸光纤距离不超过 40 公里的情况下,可以视为在一个局域网中间,延时可接受。
2. 数据库分库分表。 随着“去 IOE ”的进行,支付宝的数据库变成了分布式的 X86 服务器和 Mysql ,数据保护模式也由集中存储变成“三副本”,每个数据库的三个副本服务器分布在同城的三个数据中心, 1 主 2 从,由应用进行数据的复制和一致性的保证。
3. 应用层面实现的同城多活。 数据库实现分布式之后,同城的应用可以跨机房写数据库,应用层面的多活就实现了。而在强化了应用层面的容错和故障处置手段之后,在主数据库故障时,应用可快速把主数据库切换到其他机房的从数据库。在这种机制下,不单可以实现数据库的多活,而且进一步实现了数据中心层面的同城多活,理论上任何一个数据中心中断都不会导致业务中断,切换过程也非常简单。
4. 异地远程数据备份。 在相隔 1000 公里的远程机房,由应用程序进行数据的备份。通常只需要把关键的账务数据变动增量同步过去,由于不用备份应用系统,实现起来较为简单。
支付宝构建的这一代灾备体系,乍一看似乎不符合传统的金融行业的规范,但确实达到了监管的要求,实践效果非常好。其最大的改变是在保证金融行业的不丢数据(RPO 趋近于 0 )的前提下,对 RTO 数据恢复时间做了分类,在最常见的单节点或者单机房的故障场景下, RTO 时间也趋近于 0 ,这是远远超过传统的灾备方案效果。而最极端的同城多机房故障,这种概率的可能性极低,真要发生也变成一个需要社会应对的问题,在这个情况下,只要远程数据备份在, RTO 时间长一点也是完全可以接受的事情。这种务实的灾备思路看似简单和取巧,实际上对技术的要求很高,如果没有这套分布式架构和应用的配套改造,仍然是无法实现的。
四、未来:超融合的异地多活
基于应用的同城多活实施成功后,阿里从 2013 年就开始尝试在异地多活方面的突破。要异地多活,就不可避免的遇到跨中心数据交互和网络延时的问题,其解决思路也很简单,在同城多活的基础上进行“单元化”、“服务治理”和“异地数据交互优化”。“单元化”保障每个单元之中的基础设施、应用系统、数据库都齐备,大部分业务处理都可以在本单元之中完成;“服务治理”梳理业务之间的耦合关系,尽量减少和降低跨单元之间的数据交互,“异地数据交互优化”则是降低异地数据交互的频率、提高异地之间数据交互的效率,使业务系统可以适应异地的网络延时。具体的一些技术背景可以参考阿里巴巴技术保障部毕玄大师前段时间发表的文章。
随着集中式架构向分布式架构的转换,以及云计算的实施,未来海量系统的运维模式之下,对于灾备和业务连续性的要求会越来越高,多活数据中心一定是未来发展的方向。今天在这个领域,各大 IT 厂商以及 BAT 为代表的互联网企业都在重点发展,但是趋于两个极端。传统厂商局限于硬件和底层层面,把底层做的越来越复杂,互联网公司则采取软件定义数据中心的模式,完全抛弃了硬件的高可靠,把自身的业务层做的越来越复杂。最近的几个运维故障,也表明了当前多活还处于一个探索期,方法论和实施经验还需要磨合。
未来企业数据中心一定是需要简单最可靠的多活解决方案。个人浅见,未来一个可能的解决方案是超融合架构下的多活数据中心,总体的复杂度不会降低,但可以多方分工各自负责最擅长的领域,即 IT 厂商提供对于多活的底层技术支撑,互联网公司提供在应用开发框架层面的最佳实践和指引,各企业结合各自的业务目标做整合与开发。另外一个可能的趋势是,随着云计算实施的深入,未来的生产和灾备中心都将在基于云来建立,大部分企业都不再需要单独建立数据中心。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。