Imec最近在比利时安特卫普举行的ITF World活动中分享了其1nm以下的硅晶体管路线图。
世界先进的半导体研究公司Imec最近在比利时安特卫普举行的ITF World活动中分享了其1nm以下的硅和晶体管路线图。该路线图让我们了解了到 2036 年的时间表,该公司将与台积电、英特尔、英伟达、AMD、三星和 ASML 等行业巨头合作,在其实验室中研究和开发下一个主要工艺节点和晶体管架构。该公司还概述了向CMOS 2.0的转变,这将涉及将芯片的功能单元(如L1和L2缓存)分解为比当今基于小芯片的方法更先进的3D设计。
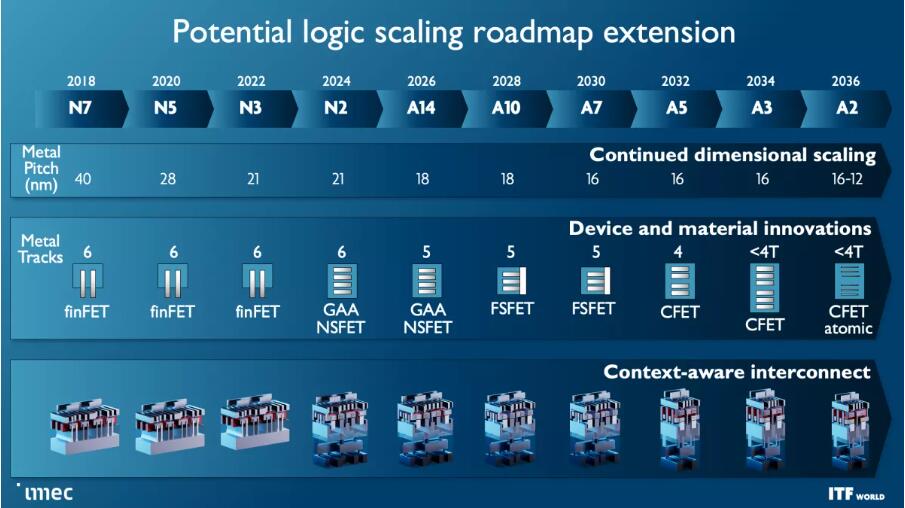
提醒一下,十埃等于1nm,因此Imec的路线图包括亚“1nm”工艺节点。该路线图概述了标准的FinFET晶体管将持续到3nm,但随后过渡到新的Gate All Around(GAA)纳米片设计,该设计将于2024年进入大批量生产。Imec分别在2nm和A7(0.7nm)处绘制了叉板设计路线,其次是A5和A2的CFET和原子通道等突破性设计。
随着时间的推移,迁移到这些较小的节点变得越来越昂贵,而用单个大芯片构建单片芯片的标准方法已经让位于小芯片。基于小芯片的设计将各种芯片功能分解成连接在一起的不同芯片,从而使芯片作为一个内聚单元运行 - 尽管需要权衡取舍。
Imec对CMOS 2.0范式的愿景包括将芯片分解成更小的部分,将缓存和存储器分成具有不同晶体管的单元,然后以3D排列堆叠在其他芯片功能之上。这种方法还将严重依赖后端供电网络(BPDN),该网络将所有功率路由到晶体管的背面。
让我们仔细看看imec路线图和新的CMOS 2.0方法。
图片 1(共 4 张)
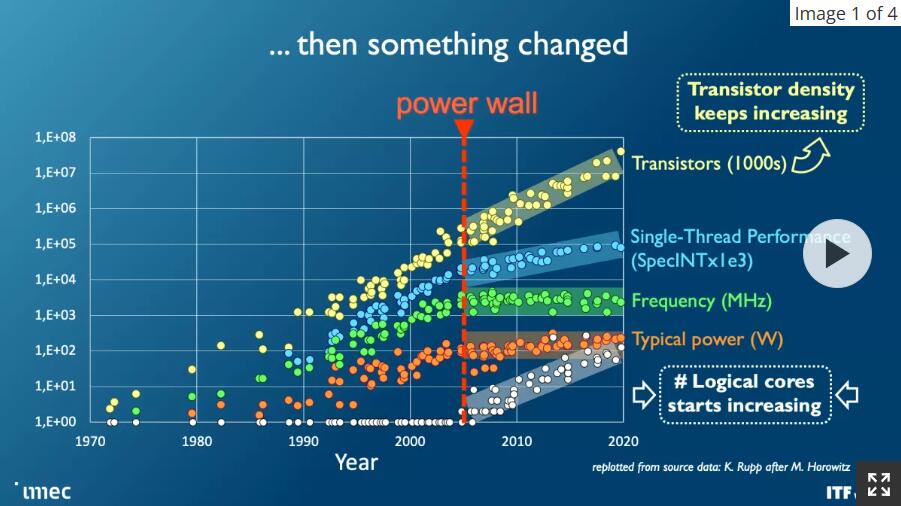
正如你在上面的相册中看到的那样,随着节点的发展,该行业面临着看似无法克服的挑战,但对更多计算能力的需求,特别是对机器学习和人工智能的需求却呈指数级增长。这种需求并不容易满足;成本飙升,而高端芯片的功耗稳步增加——由于CMOS工作电压顽固地拒绝降至0.7伏以下,功率扩展仍然是一个挑战,并且继续需要扩展到更大的芯片带来了电源和冷却挑战,需要全新的解决方案来规避。
虽然晶体管数量在可预测的摩尔定律路径上继续翻倍,但每一代新一代芯片的其他基本问题也变得越来越成问题,例如互连带宽的限制严重滞后于现代CPU和GPU的计算能力,从而阻碍了性能并限制了这些额外晶体管的有效性。
imec晶体管和工艺节点路线图
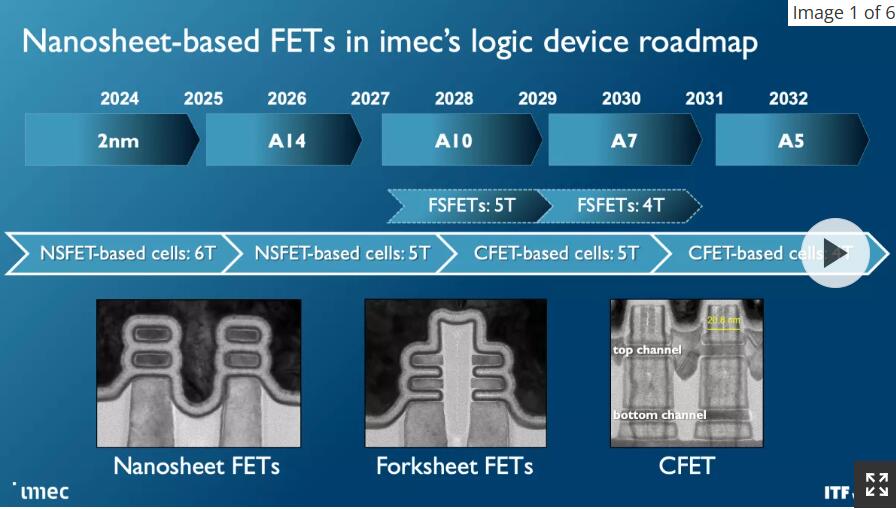
不过,更快、更密集的晶体管是第一要务,这些晶体管的第一波将伴随着 Gate All Around(GAA)/Nanosheet 器件,这些器件将于 2024 年首次推出 2nm 节点,取代为当今领先芯片提供动力的三栅极 FinFET。GAA晶体管具有晶体管密度和性能改进,例如更快的晶体管切换,同时使用与多个鳍片相同的驱动电流。由于通道完全被栅极包围,因此泄漏也显著降低,调整通道厚度可以优化功耗或性能。
我们已经看到一些芯片制造商接受了这种晶体管技术的不同变体。行业领导者台积电计划其带有GAA的N2节点在2025年到货,因此它将是最后一个采用新型晶体管的公司。英特尔采用“英特尔 20A”工艺节点的四片带状场效应晶体管具有四个堆叠的纳米片,每个纳米片完全被一个门包围,将于 2024 年首次亮相。三星是第一家为运输产品生产GAA的公司,但小批量SF3E管道清洁器节点不会大规模生产。相反,该公司将在2024年首次推出其用于大批量生产的高级节点。
提醒一下,十埃 (A) 等于一个 1nm。这意味着A14是1.4nm,A10是1nm,我们在1年的时间范围内使用A2030进入亚7nm时代。请记住,这些指标通常与芯片上的实际物理尺寸不匹配。
Imec预计叉板晶体管将从1nm(A10)开始,最后通过A7节点(0.7nm)。正如您在第二张幻灯片中看到的,此设计将NMOS和PMOS分开堆叠,但用介电屏障将它们分区,从而实现更高的性能和/或更好的密度。
互补FET(CFET)晶体管在1年首次与10nm节点(A2028)一起出现时将进一步缩小尺寸,从而实现更密集的标准单元库。最终,我们将看到具有原子通道的CFET版本,进一步提高性能和可扩展性。您可以在此处阅读更多相关信息的CFET晶体管将N和PMOS器件堆叠在一起,以实现更高的密度。CFET应该标志着纳米片器件规模的结束,以及可见路线图的结束。
然而,还需要其他重要技术来打破性能、功耗和密度缩放障碍,imec设想这将需要新的CMOS 2.0范式和系统技术协同优化(SCTO)。
STCO 和背面供电
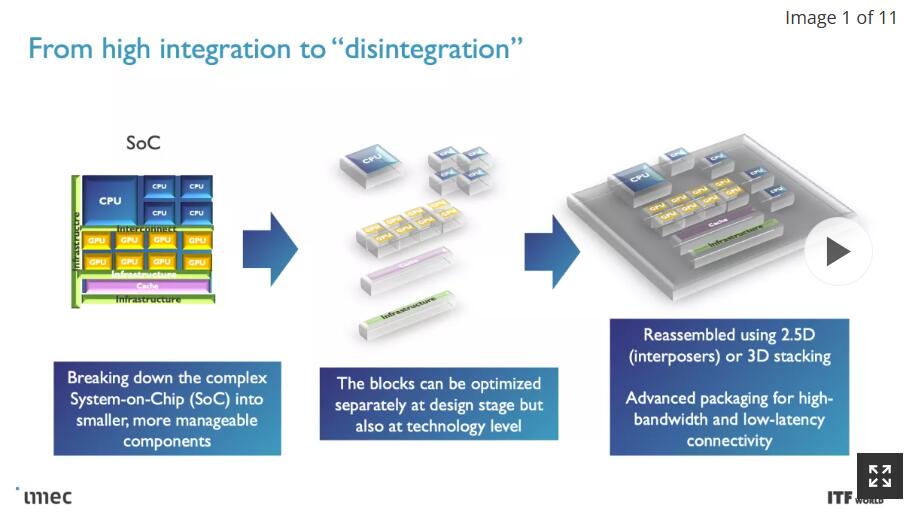
在最高级别,系统技术协同优化(STCO)需要重新思考设计过程,对系统和目标应用的需求进行建模,然后利用这些知识为创建芯片的设计决策提供信息。这种设计方法通常会导致“分解”通常作为单片处理器一部分的功能单元,如供电、I/O 和缓存,并将它们拆分为单独的单元,以通过使用不同类型的晶体管来优化每个单元所需的性能特征,从而降低成本。
完全分解标准芯片设计的目标之一是将缓存/内存拆分到它们自己独特的3D堆叠设计层(更多内容见下文),但这需要降低芯片堆栈顶部的复杂性。改造生产线后端(BEOL)工艺,重点是将晶体管连接在一起,并实现通信(信号)和电力输送,是这项工作的关键。
与当今将电源从芯片顶部向下输送到晶体管的设计不同,背面配电网络(BPDN)使用TSV将所有电源直接路由到晶体管的背面,从而将电力传输与保留在另一侧正常位置的数据传输互连分开。将电源电路和数据承载互连分开可改善电压下降特性,从而实现更快的晶体管切换,同时在芯片顶部实现更密集的信号路由。信号完整性也有所提高,因为简化的布线可实现更快的导线,同时降低电阻和电容。
将供电网络移动到芯片底部,可以更轻松地在芯片顶部进行晶圆到晶圆的键合,从而释放在存储器上堆叠逻辑的潜力。Imec甚至设想可能将其他功能移动到晶圆的背面,例如全局互连或时钟信号。
英特尔已经宣布了自己的BPDN技术版本,称为PowerVIA,将于2024年以20A节点首次亮相。英特尔将在即将举行的VLSI活动中透露有关该技术的更多详细信息。同时,台积电还宣布将BPDN引入其N2P节点,该节点将于2026年大批量生产,因此该技术将在相当长的一段时间内落后于英特尔。有传言称三星将在其2nm节点上采用这项技术。
CMOS 2.0:通往真正3D芯片的道路
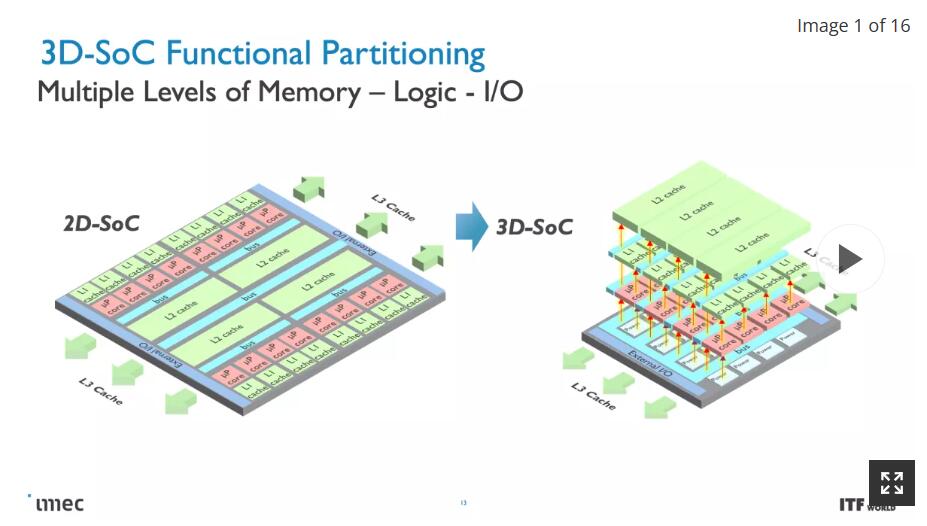
CMOS 2.0是imec对未来芯片设计愿景的结晶,包括全3D芯片设计。我们已经看到AMD的第二代3D V-Cache将L3内存堆叠在处理器顶部以提高内存容量,但imec设想整个缓存层次结构包含在自己的层中,L1,L2和L3缓存垂直堆叠在构成处理内核的晶体管上方的自己的芯片上。
每个级别的缓存都将使用最适合该任务的晶体管创建,这意味着SRAM的旧节点,随着SRAM扩展开始大幅放缓,这一点变得越来越重要。SRAM的缩减导致缓存消耗更高比例的芯片,从而导致每MB成本增加,并抑制芯片制造商使用更大缓存的积极性。因此,与迁移到密度较低的节点进行 3D 堆叠缓存相关的成本降低也可能导致缓存比我们过去看到的要大得多。如果实施得当,3D 堆叠还有助于缓解与较大缓存相关的延迟问题。
这些CMOS 2.0技术将利用3D堆叠技术,如晶圆到晶圆混合键合,形成直接的芯片到芯片3D互连,您可以在此处阅读更多信息。
正如您在上面的相册中看到的,Imec还有一个3D-SOC路线图,概述了互连的持续缩小,这些互连将把3D设计联系在一起,从而在未来实现更快,更密集的互连。这些进步将在未来几年通过使用新型互连和处理方法来实现。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。


































