Intel的Dual-XOR理论意义大于实际意义,但其改良的版本RAID-DP却已经被NetApp产品化。NetApp之所以喜欢这个类似Dual-XOR的RAID-DP算法,原因也很简单。
除了P+Q RAID6,还要好多种办法可以实现对两颗磁盘掉线的容错。
Intel提到一种Dual-XOR算法,这种方法就是取横向和斜向两个方向进行XOR运算,这样每个应用数据都在两个校验中留下痕迹,当两颗磁盘掉线时,就可以恢复数据。
但是Dual-XOR的恢复工作异常复杂艰苦,并不实用。很多技术人员研究这种算法的意义,完全是把它当作未经优化的原型思想。
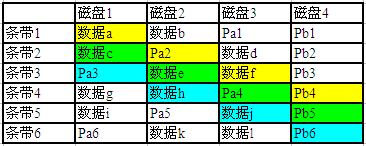
如图,Pa是横向的校验,跟RAID5完全一样:
Pa1 = 数据a XOR 数据b
Pa2 = 数据c XOR 数据d
…………
Pa6 = 数据k XOR 数据l
Pb是斜向校验,定义为:
Pb4 = 数据a XOR Pa2 XOR数据f
Pb5 = 数据c XOR 数据e XOR Pa4
Pb6 = Pa3 XOR数据h XOR 数据j
可以看出Dual-XOR的校验生成过程比P+Q要简单,但是根据“麻烦守恒定律”,正向工作简单的事情,一般反向工作都会复杂。
备份和恢复一般也遵循这个规律。
(别跟我提CDP,那东西是遵循的是广义麻烦守恒定律。每个I/O都打个时间标签,还都当宝贝存着不扔,这能是个不麻烦的事吗?Sorry,又扯远了。)
当两颗磁盘掉线的时候,Dual-XOR的算法只能支持逐个数据块的恢复,而且不同条带之间还要共同参与计算。
比如图中的磁盘1和2掉线,恢复数据e的时候,就要至少动用到数据f、Pb3、Pa4和Pb5。而数据c和Pa3的恢复还要依赖数据e的恢复。
总之恢复起来是件贼头痛的事情!
五、NetApp RAID-DP
虽然Intel的Dual-XOR理论意义大于实际意义,但其改良的版本RAID-DP却已经被NetApp产品化。NetApp之所以喜欢这个类似Dual-XOR的RAID-DP算法,原因也很简单。
NetApp原本用的就是RAID4,而不是RAID5,其算法的中心思想就是每次I/O只跟两颗磁盘打交道就OK,自然就不会在乎RAID-DP中很多动作都只跟两、三颗磁盘打交道。
(这个思想也许在很多RAID5的Fans看来有点奇怪,难道不是磁头越多性能就越好吗?但是人家NetApp这么多年的经验都集中在WAFL文件系统上,而WAFL文件系统又是专门针对这种思想优化的。所以NetApp对这个略有异类的思想不仅没有放弃,而且还越研究越起劲。)
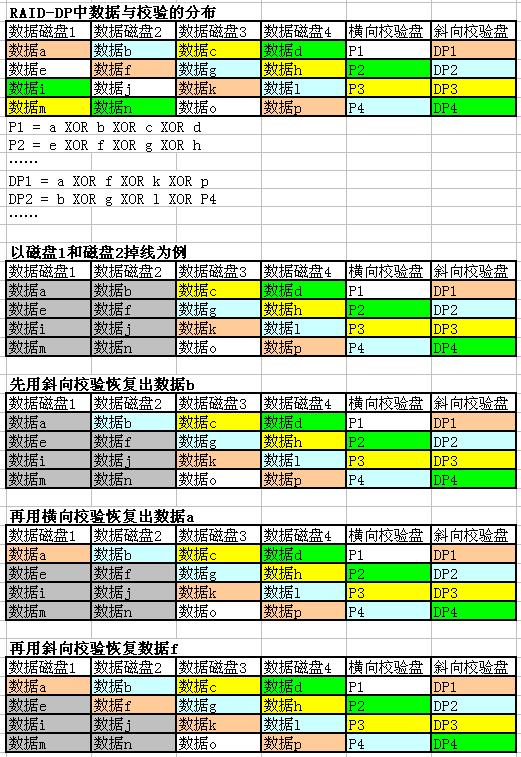
这个递归式数据恢复机制简直像在玩RPG游戏,但是对WAFL文件系统来说,却的确是最合适的选择之一。
六、五花八门的“准RAID6”
除了RAID-DP,还有X-Code编码、ZZS编码、Park编码……都可以看做是“准RAID6”。
X-Code编码
下面这个图是X-Code编码的解释。
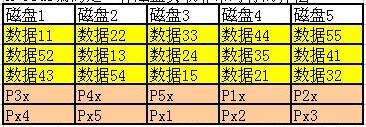
P3x = 数据33 XOR 数据35 XOR 数据32
Px4 = 数据44 XOR 数据24 XOR 数据54
其他的校验是啥意思,不需要一一列出来了吧~
X-Code从理论上看,的确是个负载均衡、计算简单(只有XOR,没有类似GF一样的变换)、磁盘对称度很高的算法。但是实际应用还是有问题。
上图的例子是5颗磁盘的X-Code编码方式,例子中的5个条带是一个整体,一起处理。如果写入的数据不多,没有写满前3个条带,就需要在写入的同时,把未更新的数据读出来,凑齐3x5个数据,再一起计算校验码。
如果是6颗磁盘,那就要6个条带作为一个整体。
7颗磁盘一个RAID组,就需要7个条带一个整体。
8颗磁盘一个RAID组,就需要8个条带一个整体。
9颗磁盘一个RAID组,就需要9个条带一个整体。
10颗磁盘一个RAID组,就需要10个条带一个整体……
(打住!在这发帖子又没稿费,不用拼命凑字!)
总之这个算法的“重复单元”有点大。在实际应用中,这么大的“重复单元”使X-Code的应用面临两个问题:计算量大和空间浪费。(可能还有其他问题,比如名字太难听,总让人联想到黄色的东东。)
ZZS编码
ZZS也叫俄罗斯编码,bingo!猜对了,真聪明。这就是三个俄罗斯人在1983年提出的一种编码方式,ZZS就是三个人名字首字母缩写,跟S.H.E.演唱组的命名规则一样。
与X-Code相比,ZZS的“重复单元”就小很多——7颗磁盘的时候,3个条带是一个整体。
人家ZZS论文里给出的是数学公式:n颗磁盘的时候,(n-1)/2个条带是一个整体。
从这个公式你应该能发现ZZS编码的一个要求……(我知道,只支持单数颗磁盘。)
嘿嘿!你错了!实际上,ZZS算法只支持磁盘的个数为素数:……5、7、11、13、17……
不过人家ZZS组合(暂时就这么称呼吧)也指出,ZZS算法支持其中一颗磁盘上面全写0。这样就可以在应用中支持4、6、10、12、16……(素数-1)颗盘了。
什么?还没明白?在计算的时候,内存里虚拟一个全0的影子盘不就行啦!

Park编码
Park是名IBM的员工,在Yorktown上班。他的业余爱好是……(Sorry,又差点跑题)
相比俄国人训练有素的数学功底,美国人既没有兴趣,也没有耐心再从算法上去优化“双重校验”的技术。但是美国人讲求实际的思想还是挺值得称道。
这不,人家Park就说了,“研究了这么多算法,最终目的不就是坏两颗盘数据仍可恢复吗。到头来算法搞得那么复杂,还不如我的看家本领——穷举法——更实在。”
Park同志是这样说的,也是这样做的(凝重的音乐声响起~)
他编了一个程序,让计算机帮他搜索给定磁盘数量的校验分布模式。
结果你猜怎么着,人家还真有收获。从3颗磁盘到38颗磁盘,除了8颗磁盘和9颗磁盘的情况,其他情况Park都找到了满足要求的校验分布模式。
什么?你问满足的是什么要求?两颗磁盘掉线数据可恢复啊。汗!
后来,一个名叫徐力浩(音)的中国人补上了8颗盘和9颗盘的校验分布表。(咱们中国人到底还是比米国人聪明那么一点点,哈~)
现在Park编码已经对从3颗到38磁盘的所有情况,都能给出双重校验分布方法。但是各种分布方法之间根本没有联系,所以只能在给定磁盘数量的时候,去查Park编码表。
Park编码的样子都是以3个条带为一个“重复单元”,其中1个条带专门用来存校验,另外2个存数据。

声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。