2020年前几个月,天气和气候超级计算新闻占据了主导地位,英国,欧洲中距离天气预报中心和美国国家海洋与大气管理局发布了重要公告。NSF支持的国家大气研究中心(NCAR)计算信息系统实验室的技术开发总监Richard Loft在Nvidia的GTC 2020的(虚拟)阶段进行了
2020年前几个月,天气和气候超级计算新闻占据了主导地位,英国,欧洲中距离天气预报中心和美国国家海洋与大气管理局发布了重要公告。NSF支持的国家大气研究中心(NCAR)计算信息系统实验室的技术开发总监Richard Loft在Nvidia的GTC 2020的(虚拟)阶段进行了演讲,着重强调了NCAR在将天气和气候超级计算转移到十亿亿分之一级方面的进展。
Loft讨论了NCAR的最新一代天气预报模型(MPAS)。MPAS是与洛斯阿拉莫斯国家实验室合作开发,是IBM及其子公司The Weather Company 去年推出的全球高分辨率预报系统(GRAF)的基础,该系统 自10月开始投入生产。Loft指出,该团队的资金有限,并且严重依赖学生的支持,他将GRAF称为到目前为止MPAS的“拥挤成就”。
Loft说:“ NCAR,IBM和气象公司之间的这种合作关系已经在世界上许多地区(尤其是发展中国家)生产了具有三公里分辨率的模型,而这些地区还没有这类模型之前的决议。” 他说,这些新功能将为那些服务不足的地区显着增强天气预报产品。
而且,至关重要的是:“据我所知,[GRAF]是目前世界上任何地方的第一个基于GPU的全球预测模型。”
MPAS的目标
在演讲中,Loft概述了NCAR在计算世界接近百亿时代时针对MPAS的目标-以及GPU和CPU之间的负载平衡如何影响这些目标,而GPU已成为许多主要超级计算机中越来越重要的部分。Loft说:“因此,当我们在三年前开始这项工作时,我们便从试图为该模型实现许多核心功能的角度开始研究它。”
首先是性能的可移植性。Loft说:“我们希望在GPU上获得最佳性能,但我们希望保持CPU的性能。” “我们不想为此牺牲,因为那是我们的面包和黄油。”
第二是弹性。他解释说:“我们需要制定一种策略来平衡混合节点上的所有代码,这样对于CPU和GPU的任何组合来说,它的接线就不会太硬。”
最后,研究人员希望移植最少的代码。劳夫特说,为此,他们“分流”了这一过程。他们将大多数物理和动力学代码移植到了GPU,但将辐射代码(这是通过大气传递太阳辐射的原因)留给了仅CPU的代码。劳夫特解释说,他们做出了这个选择,因为辐射代码超过30,000行。Loft说,辐射是“昂贵的”:“如果您每时每刻都调用它,模型将被磨死。” 幸运的是,辐射也以很慢的时间尺度发展,因此从纯粹的物理水平来看,与模型的其余部分异步运行是合理的。
研究人员还保留了包含地表模型(该模型负责解释土地与大气之间的水和能量转移)作为仅CPU的模型,因为该模型有20,000行以上的“分支代码”,并且运行时间并不长。 (不过,不幸的是,Loft说,它必须同步运行)。
在两台功能强大的超级计算机上进行完美修补

为了优化其新移植的模型,NCAR选择了一对超级计算机。首先是NCAR自己的Cheyenne系统,该系统包含4,032个节点(每个节点带有Intel Xeon Broadwell处理器),总计313 TB的内存,由Mellanox EDR InfiniBand连接。第二个是橡树岭国家实验室的Summit,它容纳4,608个节点(每个节点带有两个IBM Power9 CPU和六个Nvidia Volta GPU),超过10 PB的内存,并与EDR InfiniBand捆绑在一起。
夏安和萨米特分别以4.8和148.6 PB的千万字节跌落位居世界最强大的公开排名超级计算机Top500排行榜的第44位和第1位。选择了这两个系统的原因:夏安因其仅采用CPU的同类设计而被选中,而Summit则提供了对GPU繁重的异构系统未来设计的了解。Summit还与GRAF的基于IBM Power9的超级计算机相似,后者具有84个节点,每个节点具有四个Nvidia V100 GPU。
超级计算机被用来帮助NCAR找到资源分配的“戈迪洛克区”。在为辐射或动态或辐射分配CPU内核和/或GPU时,时间上的不匹配可能会导致严重的时间和金钱损失。例如,分配给CPU的辐射太少,而支持集成的GPU(模型的其余部分)将不得不在等待CPU赶上时暂停其工作。

为了进行测试,研究人员利用了夏安的76个CPU节点和峰会的76个混合节点,以十公里的分辨率运行MPAS,从而为每个系统上的每个节点投入了81,920个分析点。他们测试了CPU和GPU分配的平衡,对称多线程的变化以及将辐射重新集成到模型中的时间间隔的变化。
在夏安,研究人员发现该系统是集成受限的,在通用模型任务上的性能相对较差–因此,他们将每个CPU上的大多数内核分配给了通用模型,而很少分配给辐射(比例为2:1)。同时,在Summit上,他们发现由于GPU为处理能力做出了巨大贡献,因此系统受到了辐射的限制。最终,研究人员发现,在集成模型专用的18个CPU内核(和GPU)与辐射专用的24个CPU内核之间取得了最佳性能。
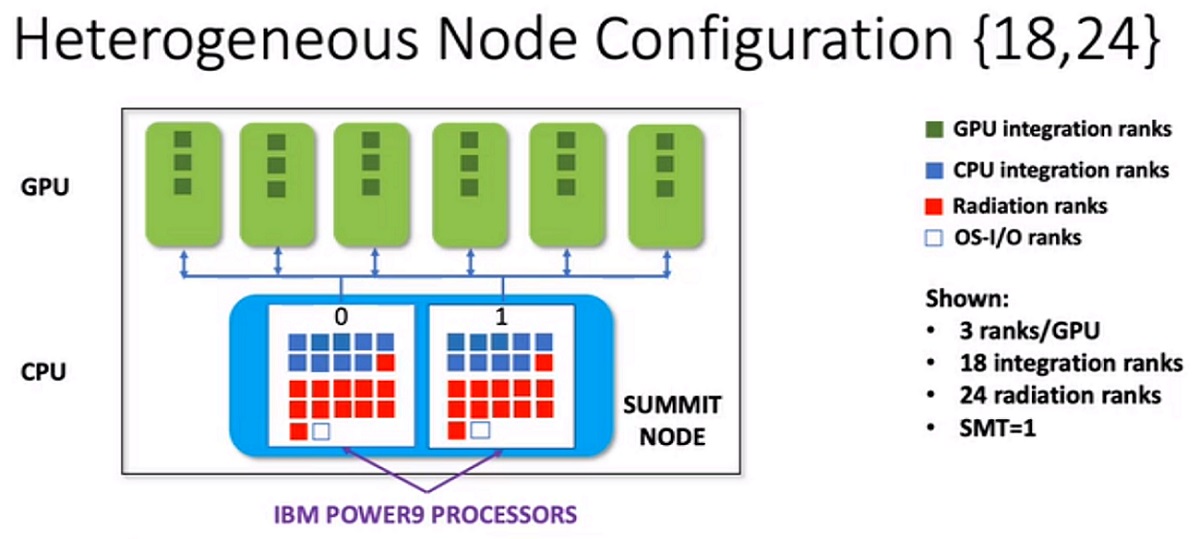
Summit的MPAS配置。图片由NCAR提供。
接下来,NCAR团队将致力于进一步优化消息传递,并将陆面模型移植到GPU,以释放更多的内核进行辐射处理。(Loft表示,他们正在考虑将辐射代码移植到GPU,但这只是“最后的选择”。)
尽管Loft承认在可伸缩性和吞吐量方面尚需完成工作,但他表示该模型正在逐步优化。Loft说:“这项工作仍在进行中,但是我们已经拥有了完整的模型。” “这是一个很好的开始。”
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。

































