最先进的是最新的 Facebook阿尔图纳数据中心,它采用了由廉价交换机组成的网状连接交换架构来提升性能,Facebook 称之为下一代的数据中心—Data Center Fabric。
Facebook 的庞大帝国需要存储的数据时刻都在不断爆炸。比方说,现在它每天要分享 20 亿张照片,而且需求还在不断增加,唯有靠不断建设扩充存储和数据中心才能满足。
此前我们曾多次介绍过 Facebook 的数据中心,这里面最先进的是最新的阿尔图纳数据中心,它采用了由廉价交换机组成的网状连接交换架构来提升性能,Facebook 称之为下一代的数据中心—Data Center Fabric。
上述解决方案对于提升数据中心的网络性能、降低成本以及提高能效起到了非常关键的作用。但是对于存储需求的不断增加却没有办法,需要 Facebook 研究其他的应对措施。近日,Facebook揭秘了自己的 cold storage system 存储系统是如何解决这个问题的。
顾名思义,cold storage(冷存储)存放的就是不常使用的数据,比如说几年前的历史数据。对于历史数据,传统的解决方案是采用带库、光盘等廉价介质来存储的,但是这种介质的缺点在于存取和访问速度太慢。Google 不久前推出的云存储服务Google Cloud Storage Nearline较好地解决了这个问题。
设计原则
不过 Facebook 团队决定用全新的角度去审视问题,他们从头开始,以端到端的方式重新设计了软硬件。
1)节能降耗
在这套以存储为核心的 Cold Storage System 中,存储资源是按需启动的,同时摒弃了冗余发电机或备用电池等以提高能效。由于 cold storage 采用的是低端商品化硬盘,硬件方面的约束要求进行命令批处理要非常小心,并且需要牺牲时延以换取效能。其对物理盘的存取是以平均故障间隔时间为基础控制硬盘的忙闲度(占空比)的。
2)智能管理
由于前面为了省电降低成本舍弃了备用电,这就要求软件任何时候都能应对哪怕是最小的电力中断,避免出现数据丢失的情况。
此外,数据还要具备持久性并保证完整性。为了保证持久性,系统设计时每一层面都要考虑持久性,消除单点故障,以尽可能少的步骤恢复整个系统,Cold Storage 甚至连单独管理元数据的系统都是可有可无。也就是说,数据本身即可自我描述,不需要借助外部就能够辅助进行恢复。这么做的原因在于 cold storage 是其他系统数据丢失情况下的最后一道防线了。
3)面向未来
考虑到 Facebook 的数据设计时还需要考虑未来。很多系统在规模扩大或者利用率上升时往往就会性能下降或出问题,所以 Facebook 的这套系统一开始设计时就得考虑如何避免这一问题。

Facebook 在 Prineville 的 Cold Storage 设施
基于上述考虑,目前 Facebook 已经在 Prineville 及 Forest 两个中心建设了两套 cold storage 系统,里面存放着数百 PB(100 万)的数据。不过如此的高容量其能耗仅为传统存储解决方案的 1/4。而且跟一般系统不一样的是,这套系统的性能并不会随着规模扩大而下降,恰恰相反,系统越大性能反而越佳。最后一点值得关注的是,Facebook 的这套存储系统采用了十分经济高效的冗余备份方式,可以以低于 2 的系数实现数据的备份冗余。从以上几点来看,作为一套半在线半离线存储系统,cold storage 表现出来十分理想的特性。当然,要想发挥这套系统的效用,还需要 Facebook 开放计算体系如开放机架、网络、数据中心等其他组成部分的配合,一般人想学并不容易。
Cold Storage System 的基础是Open Vault Storage。这是一套专门针对 Open Rack(开放计算的机架标准)打造的简单高效的存储解决方案,它采用了模块化的 I/O 拓扑,2U 机框可容纳 30 块硬盘(每托盘 15 块硬盘,横放而不是竖放),几乎可以与任何服务器互操作。Cold Storage 就是在这样一套高密度的JBOD(Just a Bunch Of Disks ,磁盘簇)存储基础上修改而成的。

Cold Storage 机架
硬盘按需启动,电耗降到 1/4
降低耗电是系统一开始的设计目标之一。据介绍这套系统的耗电极低,降到了传统数据中心的 1/6。其手段之一是以空间换降耗。数据中心占地面积非常大,满容的情况下每数据大厅可支撑 1000PB 的存储容量。随着以后单盘容量的提升,其存储规模还可以进一步扩大。
同时由于 cold storage system 存放的不是活跃的生产数据,而是历史数据,所以 Facebook 把冗余电力系统(不间断电源、发电机、备用电池等)也撤销了,从而进一步提升了能效。
架内布置,每 2U 放 30 块硬盘,电源插框放中间位置
为了尽可能降低能耗,Cold Storage 允许服务器可以不带硬盘启动,然后由软件来控制忙闲度。不过这样就要求对 Open Vault 存储规范进行修改。其最大的改动是每次只允许每托盘有一块硬盘上电。为了避免软件 bug 错将所有硬盘上电导致数据中心保险烧坏,Facebook 甚至还专门修改了硬盘驱动器的固件。
此外,由于不必每次都要给所有硬盘供电,每个存储节点散热风扇的数量也从 6 个降到了 4 个,供电机框数从 3 个降到了 1 个,供电单元数从 7 个降到了 5 个,Open Rack 机架母线数特从 3 条降到了 1 条。这样的调优令机架的存储密度大大增加,每机架可容纳 2PB 的存储容量(4TB 硬盘),与传统存储服务器相比,其耗电只有后者的 1/4。

2U 机箱,5*3 块硬盘,绿色的是 SAS 扩展板
用经济的方式保证数据安全
传统上为了保证数据的安全,一般会采用多副本技术来避免硬件故障,但这么做需要拷贝几份数据,造成了资源的浪费,能不能在存放的数据不多于两份的情况下避免数据丢失呢?
尤其是 Cold Storage 采用的都是些廉价硬盘,而且又没有备用电池,故障中断等情况都是难免的。
怎么解决呢?Facebook 采用了Reed Solomon Coding 纠删码技术。纠删码是存储领域常用的数据冗余技术,其基本原理是将原始数据切分为 n 块,然后根据这几块生成 m 个校验块。利用算法,从从 n 个原始数据块和 m 个校验块中任取 n 块就能解码出原始数据,也就是说进行这样的处理后,哪怕有 m 块数据同时丢失数据仍能恢复。通过将这些数据分到不同的故障域(如硬盘),Cold Storage 就可以以较小的成本实现数据的保护。显然,校验块越多,可容忍的数据块出错数也就越多。当然,其代价是额外需要的硬盘也越多。
那多少才合适呢?这需要对硬盘的失败特征进行调查和建模才能确定数据分块数和校验块数。Facebook 目前的配置是 10:4(每 10 块硬盘配 4 块校验盘)。也就是说,用 1.4GB 的空间实现对 1GB 数据的备份,这种情况下可忍受 4 块硬盘同时坏掉。但是这种配比也会随着硬件特性以及对安全性的要求而变化的,因此 Facebook 开发了数据重新编码服务,这样就可以根据情况变化(存储媒体的可靠性)来重新灵活组织数据。
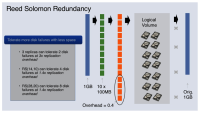
RS 纠删码技术,把 1GB 数据切分为 10 块分别放在 10 块硬盘,另用 4 块硬盘放校验,可容忍 4 块硬盘同时坏掉
与以往模式相比,这种备份方式效率显然高得多,而且数据的持久性也大为增长。不过纠删码只能应付数据丢失,但是对于篡改却无能为力。为此,Facebook 通过创建、维护及检查校验和来验证数据的完整性。而且这些校验和就挨着数据存放,一旦发现错误就马上从别处复制一份过来。
俗话说大脑越用越灵,不用则衰,存储也是这样。完全闲置或者不动的数据容易损坏,这就是所谓的 “位衰减”。为此,Facebook 在后台开启了一个 “反熵” 进程,专门用来定期扫描所有硬盘上的数据,从中检测数据畸变并报告。这个频率是每 30 天一次全扫描。一旦发现错误,另一个进程就会接管,然后读取足够多的数据去重建丢失的数据,并将其写入到新的硬盘上。由于整个过程将检测、失败分析与重构及保护分离开来,重构的耗时从小时级降到了分钟级。
Facebook 还对数据存取进行了彻底改造。由于大多数现代文件系统在设计上的缺陷,这些文件系统基本上无法胜任短时间内进行大量频繁的加载与卸载操作。而且而且由于文件系统处在非常底层的位置,导致错误调试非常困难。Facebook 的做法是跳过文件系统,将所有硬盘移植为 “裸盘”。这样的好处是可以掌控整个数据流,从而进一步保证数据的持久性。
规模越大性能越好
传统系统往往规模越大性能就开始下降。Facebook 希望避免这一点,甚至定下了越大越好的目标。其做法是每次增加容量时软件都要对现有数据进行再平衡—即将原有数据分配到新的硬件上,并释放之前用过的空间。这个过程并非实时进行,十分适合于在用系统的逐步移植,即既不影响系统的使用,又能逐步将数据迁移到新硬件上。如果把 Cold Storage 看作一块大硬盘的话,你可以把这种再平衡的做法视为智能硬盘整理程序。
未来计划
通过将冷数据(历史数据)与热数据(生产数据)分离、用冷存储系统处理冷数据的做法,Facebook 得以实现降低能耗及节省其他资源节省的同时服务好数据请求。不过尽管目前 Facebook 的两套 cold storage 系统已经有数百 PB 的数据,但是这还只是整个数据量的 1%,而且 Facebook 的数据每天还在不断增加。因此,社交巨头还需要继续扩大自己系统的规模,同时还将探索闪存、蓝光盘等各种存储媒介的利用,以及研究跨数据中心分布式存储文件数据的方法以改进持久性。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。

































