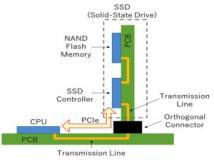
大数据已经不是什么新话题了,在实际的开发和架构过程中,如何为大数据处理做优化和调整,是一个重要的话题,最近,咨询师Fabiane Nardon和Fernando Babadopulos在“Java Magzine”电子期刊中发文分享了自
大数据已经不是什么新话题了,在实际的开发和架构过程中,如何为大数据处理做优化和调整,是一个重要的话题,最近,咨询师Fabiane Nardon和Fernando Babadopulos在“Java Magzine”电子期刊中发文分享了自己的经验。
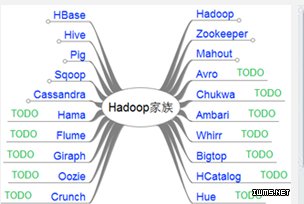
作者在文中首先强调了大数据革命的重要性:
大数据革命正在进行,是时候去参与其中了。企业每天产生的数据量不断增加,可以被重新利用来发现新信息的公共数据集也被广泛使用。再加上花费很小、按需处理的云计算组合,你处在一个具有无限可能的新世界。不难想象,通过利用大数据技术在云计算中的力量,很多颠覆性的应用程序将会涌现出来。许多新兴公司现在提出了新的令人兴奋的应用,而这些想法在几年前无法得到足够的财务支持。作为Java开发者,我们完全有能力参与到这场革命中去,因为许多最为流行的大数据工具都是基于Java的。然而,要构建真正可扩展并且强大的应用程序,同时要保持托管费用在掌控之中,我们不得不重新考虑架构,同时尽量不迷失在无数可用的工具当中。
文章介绍了Apache Hadoop,一个允许对大数据集进行分布式处理的框架,可能是这些工具中最为人熟知的一个了。除了提供强大的MapReduce实现和可靠的分布式文件系统——Hadoop分布式文件系统(HDFS)——之外,也有一个大数据工具的生态系统构建在Hadoop之上,包括以下内容:
Apache HBase的是针对大表的分布式数据库。
Apache Hive是一个数据仓库中的基础设施,它允许在HDFS中存储的数据中进行临时的类似SQL的查询。
Apache Pig是一个用于创建MapReduce程序的高层平台。
Apache Mahout是一个机器学习和数据挖掘库。
Apache Crunch和Cascading都是用于创建MapReduce管道的框架。
虽然这些工具是强大的,但它们也增加了许多开销,除非你的数据集非常大,否则是无法抵消这些成本的。比如,可以在一个非常小的数据集上尝试运行文章中提供的代码示例,比如一个只有一行的文件。你将会看到,处理时间将会比你所预期的时间长很多。如何确定你是否真的有一个大数据的问题?文章指出,虽然没有固定的数据,但有几个指标可以用来帮你决定你的数据是否足够大:
你所有的数据不适合在一台机器上运行,这就意味着你需要一个服务器集群来在可接受的时间范围内处理你的数据。
你在处理的大多数是TB级别的而不是GB级别的数据。
你正在处理的数据量正在持续增长并且可能每年增加一倍。
如果你的数据是不是真的很大,就保持事情的简单吧。通过传统的Java应用程序,甚至用更简单的工具,例如grep或Awk来处理你的数据,你可能会节省时间和金钱。
作者特别强调,如果你决定用Hadoop来分析你的数据集,那么随着数据的增加,你会希望避免性能瓶颈。你可以将很多配置调整应用到Hadoop集群上去,并且如果你的应用程序处理数据的速度没有达到你需要的那么快时,你可以一直添加更多的节点。但是,请记住,没有什么会比你自己的代码更高效对你的大数据应用程序产生更大的影响了。
当实现一个大的数据处理应用程序时,你的代码通常会在每个处理周期内被执行数百万或数十亿次。举个例子,考虑一下你得处理一个10GB的日志文件,并且每行有500字节那么长。分析每行文件的代码将运行2000万次。如果你可以让你的代码处理每行的时候快10微秒,这将使处理文件的过程快3.3分钟。因为你可能每天要处理很多10GB的文件,随着时间的增多,那些分钟将在资源和时间上表现出显著的实惠。
这里的经验是,每微秒都很重要。为你的问题选择最快的Java数据结构,在可能的情况下使用缓存,避免不必要的对象实例化,使用高效的字符串操作方法,并且用你的Java编程技能产出你所能编出的最高效的代码。
除了生产高效的代码之外,了解Hadoop的工作原理对于你避免一些常见的错误是很重要的。
在云中部署大数据应用程序有许多优点。文章指出,随着数据量的增大,你可以根据需要购买更多的机器,并且可以为峰值做好准备。然而,如果要在不产生高昂的扩展费用的前提下使用云服务,你得在脑中考虑好云平台的特殊性后再构建应用程序。首先,更加高效的代码意味着更少的处理时间,也就是较少的托管费用。每次你添加一个新节点到你的集群中的时候,你就是在增加更多花费,因此确保你的代码尽可能的有效是个很好的做法。
当在云中部署大数据应用程序时,考虑使用无共享架构是很重要的。无共享架构基本上是只由网络相互连接的单个计算机,他们不共享任何磁盘或者内存。这就是为什么这种架构的扩展性非常好,因为不会由磁盘访问的竞争或者是另一个进程的出现引发瓶颈。每台机器都需要顾及所有工作,机器直接是相互独立且自给自足的。
Hadoop的容错功能打开了探索的可能,甚至更便宜的云机器也能提供。如Amazon spot的实例(当价格比你的竞价更高的时候你可能会失去这个机器)。当你使用这种机器来运行TaskTracker时,例如,你任何时候都可以承受机器的失去,因为Hadoop只要检测到你失去了一个或多个正在作业的结点时,它将会在另一个节点上重新运行这个作业。
事实上,在很多大数据应用程序中,甚至可以接受失去一小部分数据。如果你在做统计处理,很常见的事情是,一个没有被处理的小数据集可能不会影响到最终结果,当你创建你的架构时,你可以将此作为你的优势。
你可以使用一个在云端中支持Hadoop的服务来托管你的应用程序。亚马逊EMR是这种服务的一个很好的例子。使用Hadoop的托管服务将减轻安装和维护自己Hadoop集群的负担。不过,如果需要更多的灵活性,你也可以在云端安装自己的Hadoop解决方案。
文章指出,在云中使用Hadoop的另一个好处是,你可以监视作业的行为,并且即使在工作运行的情况下,你也可以根据需要自动添加或删除节点。Hadoop的容错特性可以确保一切都将继续工作。这里的窍门就是预先配置主节点使其允许一系列从IP地址。这是通过Hadoop安装目录里的conf/slaves文件来完成的。有了这个配置,你可以从预先配置的一个IP地址中启用一个新的从结点,它就会自动加入集群。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。