IBM InfoSphere® BigInsights 是 IBM® 推出的用于储存和分析 大数据的软件平台。在2015 Q1中国大数据分析工具TOP30排行榜上也是排名第一的大数据分析工具。
IBM InfoSphere® BigInsights简介
IBM InfoSphere® BigInsights 是 IBM® 推出的用于储存和分析 大数据的软件平台。本文将介绍 BigInsights,解释该产品的设计目标、用途以及它如何与现有的软件互补。
在2015 Q1中国大数据分析工具TOP30排行榜上也是排名第一的大数据分析工具。
下载
免费下载:IBM® InfoSphere Streams V2 试用版
架构概述
InfoSphere BigInsights 1.2 是一个软件平台,旨在帮助公司从大量不同范围的数据中挖掘商机并进行分析,因为用传统方法来处理大量数据有些不切实际且难度很大,常常会忽略或丢弃一些数据,比如日志记录、点击流、社会媒体数据、新闻摘要、电子传感器输出,甚至是一些事务数据等。为了帮助公司以一种有效的方法从这些数据中获取有价值的东西,BigInsights 公司提供一些开源项目(包括 Apache™ Hadoop™)和一些 IBM 开发的技术。
图 1 解释说明了 IBM 推出的大数据平台,该平台包含用于处理流数据和持久性数据的软件。BigInsights 支持后者,而 InfoSphere Streams 支持前者。可以将两者部署在一起,以支持对各种形式的原始数据进行实时和批量分析,也可以单独部署它们,以满足特定的应用目的。本文主要关注 BigInsights。
图 1. IBM 针对 Big Data 的平台和远见
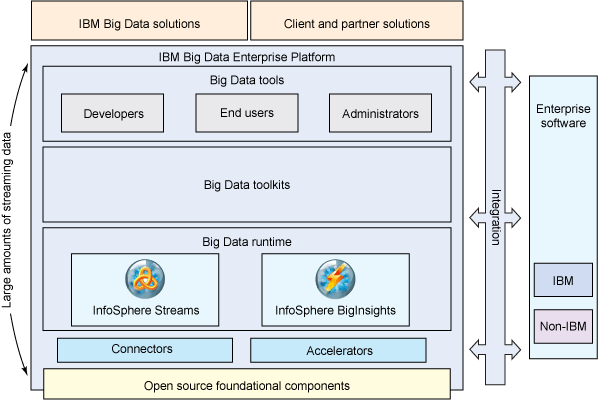
IBM 开发 BigInsights 旨在帮助公司处理和分析许多企业都关注的那些在数量、种类和速度上不断增加的数据。据行业分析师预测,未来一年的数字数据量会迅速增加。实际上,国际数据资讯 (IDC) 公司预测的 2020 年的数据量将比 2009 增加 44 倍,并且这些数据大多数都会以非结构化或半结构化的形式存在。于是,许多 IT 专业人员预见到了数据处理方面的新挑战;他们通常会使用 “Big Data” (或 “大数据”)来形容这个问题。
不过,许多公司已经意识到,通过分析大量原始数据,能够获取对其组织至关重要的一些模式和见解。大数据分析的应用范围涵盖许多领域,其中包括客户维护、客户服务、市场情报、商业规划和运营、科研、安全等。这类应用均需要分析应用程序、系统、传感器日志数据、各个电子场所内的客户或公共意见、丰富文本数据(包括文档、电子邮件和消息等)以及其他各种数据源。不幸的是,大数据分析还涉及收集、处理和管理上述这些数据,这些工作可能令人望而生畏!
为了能够对大量丰富的数据进行筛选,BigInsights 提供了内置分析技术和无分享硬件集群。它可以透明地分配存储在附加至集群中各种节点的磁盘上的文件数据,将应用程序的子任务分配给位于目标数据子集附近的处理器。这种方法可最大限制地减少了网络信息流通量并提高运行时性能。在容错方面,BigInsights 根据管理员指定的参数自动复制多个磁盘上的每一部分数据。该复制操作使 BigInsights 能够通过将工作重定向至别处,自动从磁盘或节点故障中恢复。
BigInsights 不能取代关系数据库管理系统 (DBMS) 或传统数据仓库。它在列表数据结构、在线分析处理 (OLAP) 或在线事务处理 (OLTP) 应用程序中的互动查询方面表现不佳。相反,它是一个可以增强您现有分析基础架构的平台,使您能够对大量的原始数据进行过滤,并将结果与存储在 DBMS 或数据仓库中的结构化数据组合。
基础版和企业版
此时,您可能会组成 BigInsights 平台的技术感到好奇。BigInsights 由许多 IBM 技术和开源技术组成,目前有两种版本:基础版和企业版。如 图 2 中所示,两种版本均包括 Apache Hadoop 和其他开源软件,稍后会对它们进行更详细的介绍。
图 2. InfoSphere BigInsights 1.2 的基础版和企业版
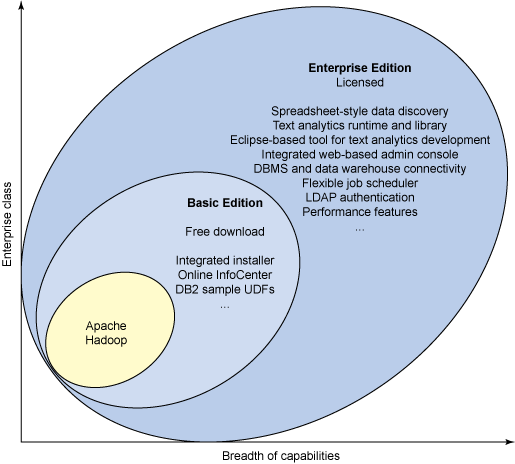
基础版可通过免费下载获得,它能管理多达 10 TB 的数据。因此,该版本适用于试点项目和探索性研究工作。企业版是付费产品,在可管理的数据量上没有任何限制。它包含了基础版的所有功能并提供了其他分析、管理和软件集成功能。因此,企业版适用于生产应用程序。
开源技术
想必您已经熟悉了某些开源技术,所以此处我们先从这些开源技术谈起。BigInsights 1.2 基础版和企业版包含的开源项目如下:
- Apache Hadoop 包括 Hadoop Distributed File System (HDFS)、MapReduce 框架和通用的实用工具,是一种适用于数据密集型应用的软件框架,可用于开发分布式计算环境
- Pig 是用于 Hadoop 的一种高级编程语言和运行时环境
- Jaql 是基于 JavaScript Object Notation (JSON) 的一种高级查询语言,也支持 SQL
- Hive 是一种数据仓库基础架构,设计用于支持批量查询和分析 Hadoop 管理的文件
- HBase 是一种以列为主的数据存储环境,设计用于支持 Hadoop 中的稀疏填充的大型表格
- Flume 是一种用来数据收集并将其加载到 Hadoop 中的工具
- Lucene 是一种文本搜索和索引技术
- Avro 是一种数据序列化技术
- ZooKeeper 是分布式应用程序的一种协作服务
- Oozie 是工作流/作业编排技术
这些项目在可以公开访问的网站上均有完整的资料。
IBM 技术
除了开源技术外,BigInsights 还提供了许多 IBM 为帮助您快速提高生产效率而开发的技术,比如文本分析引擎和支持开发工具、用于业务分析的数据探索工具、企业软件集成以及各种平台增强,这些技术可以简化管理,帮助提高运行时性能。让我们进一步了解一下这些技术。
基于文本的分析和建模
如前所述,BigInsights 旨在帮助公司分析各种范围的数据,其中包括结构松散或非结构化数据。各种类型的文本数据均归为此类别。实际上,账务文档、法律文书、市场营销、电子邮件、博客、新闻报告、新闻稿、社会媒体网站都包含公司可能想要处理和获取的基于文本的数据。
为此,BigInsights 企业版提供了一个文本处理引擎和注释库,使开发人员可以查询和识别文档和消息中关注的项,比如 BigInsights 可从基于文本的数据中提取的业务实体数据包括个人信息、电子邮箱地址、街道地址、电话号码、URL、合资企业、同盟等。
此外,程序员还可以使用基于 Eclipse 的插件来构建他们自己的 BigInsights 文本分析函数库。如 图 3 中所示,该插件包含一个表达式生成器,模式发现技术、测试环境以及一个结果资源管理器,可以用这些来促进快速成型,改进为特定应用程序要求而量身定做的复杂文本分析功能。
图 3. BigInsights 包含一个用于创建新文本分析功能(或注释)的插件
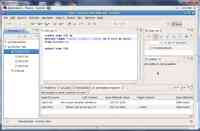
在图中,位于中间的窗口显示了用于创建 "SSN" 注释(用于识别美国社会保险号)的语法。该注释的定义是:三个单位数数字 + 一个连字符 + 两个单位数数字 + 一个连字符 + 四个单位数数字。虽然这个示例非常简单,但是它解释了如何定义注释器的基本概念。当然,程序员可以使用此工具来构建复杂的产品级注释器,包括基于先前注释器而构建的注释器。
再回过头来看一下图,您会看到,左侧的面板上指示有三个样例文档已经导入至项目,可供测试使用。底部的面板说明了使用这些文档作为输入的测试运行结果。这些结果显示了注释器识别的 "SSN" 实体、文档中出现的每个 SSN 所在的上下文(即所识别的社会保险号的左右文本),以及源文档的名称。注释器(或一组注释器)运行完成后,开发人员可以使用 Annotation Operator Graph (AOG) 的形式导出结果代码,供 BigInsights 应用程序使用。
电子表格式的数据发现和浏览
为了帮助商业分析员和非程序员处理 “大数据”,BigInsights 企业版提供了电子表格式的数据分析工具。BigSheets 是通过 Web 浏览器启动的,它支持商业分析员创建数据集合 以供浏览。要创建数据集合,分析员需要指定所需的数据源,其中可能包括 BigInsights 分布式文件系统、本地文件系统或者 Web 搜寻的输出。BigSheets 提供了对流行的数据格式(如 JSON 数据、逗号分隔的数值 (CSV)、制表符分隔值 (TSV)、字符分隔数据等)的内部支持。如果需要的话,程序员可以创建插件来处理其他数据格式和执行自定义功能。
当分析员执行(或运行)集合的定义后,BigSheets 会在后台生成 MapReduce 作业来检索和处理所需的数据。分析员也可以使用内置函数和宏命令对集合的数据进行检查和操作。这些工作均可通过传统的电子表格式界面完成,如 图 4 中所示,它描述了一个简单的用户定义公式,该公式使用集合的其他列衍生的值来填充新列。
图 4. BigInsights 企业版包含一个基于电子表格的分析工具
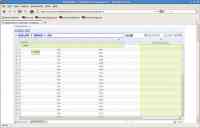
最后,如果需要的话,分析员可以使用 BigSheets 的制图功能来可视化全部或部分合集内容。此外,他们还可以用任何一种流行的格式导出集合,以供其他应用程序使用。HTML、CSV 和 JSON 均是受支持的导出格式。
集成式安装和管理工具
为帮助公司尽快开展工作,BigInsights 基础版和企业版均提供一个基于 Web 的工具,它可以安装和配置管理员所选用的所有受支持的 IBM 和非 IBM 软件。BigInsights 安装进度的详细信息是实时报告的,并且一个内置的 “健康检查” 机制会自动合适和报告安装是否成功。
与之相反,其他使用单独开源技术的公司需要反复下载、配置和测试他们要使用的每个软件项目。此外,他们还要对可能存在于这些目标项目中的所有软件的先决条件和不兼容性保持敏感。
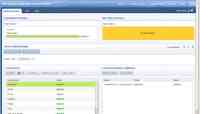
安装 BigInsights 后,企业管理人员就可以使用基于 Web 的管理控制台来随时监督 BigInsights 环境的状态。通过此控制台,您可以启用和停用节点,调查 MapReduce 作业的状态,查看日志记录,评估系统的整体健康情况,启用和停用可选组件,导航分布式文件系统,等等。图 5 说明了 Web 控制台主要面板的一部分。
图 5. BigInsights 企业版 Web 控制台的一部分
企业软件集成
许多组织都关心如何将另一个信息管理平台引入其现有 IT 基础架构中。通常,IT 架构师也会担心如何将新系统管理的信息与企业现有的其他重要数据集成在一起。
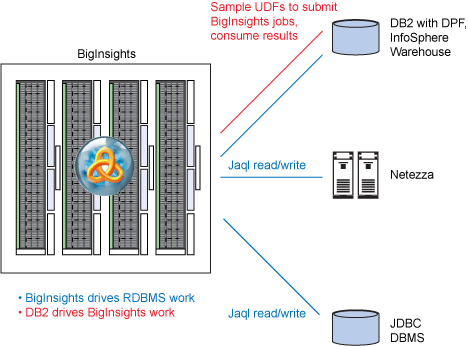
为了解决这些问题,BigInsights 企业版为 Jaql 开发人员提供了到 Netezza 和 DB2 的 JDBC 连接,以便可以利用平台的本地并行处理功能将数据传输到数据源或从数据源传输数据。此项支持对于那些想要将存储于关系 DBMS 中的参考数据与 BigInsights 管理的数据合并的 BigInsights 开发人员来说非常有用。为了能够访问其他的关系数据源,BigInsights 提供了一个通用的 JDBC 连接器。
此外,BigInsights 基础版和企业版均提供了一个样例 DB2 用户自定义函数 (UDF) ,充许 DB2 程序员在 BigInsights 中启用 Jaql 查询,将输出与 DB2 数据联合,并将结果显示给 DB2 用户和应用程序。这些 UDF 可以在 DB2 9.7 Server for Linux, Unix, and Windows 中注册。
图 6 阐述了 BigInsights 1.2 提供的 DBMS 与数据仓库的连接性。
图 6. BigInsights 1.2 提供的 DBMS 与数据仓库的连接性
平台增强和性能特性
BigInsights 采用了一些开源技术来提供可靠的运行时性能和高级可扩展性,而企业版也采用了 IBM 特定软件来进一步增强管理和提高性能。
例如,BigInsights 提供了一个可选的作业调度机制,以便更好地调整长期运行和短期运行的作业之间的资源分配。管理员可以通过属性设置为小型作业分配最大资源,以确保这些作业能快速完成。该作业调度选项还提供了 Hadoop 的先进先出 (FIFO) 和 “公平” 调度方法。
此外,BigInsights 还通过支持对其 Web 控制台进行 LDAP 身份验证来提高安全性。LDAP 和反向代理支持可帮助管理人员使用适当的权限限制用户的访问。
性能增强功能还包括通过使用基于 IBM LZO 压缩技术高效处理基于文本的压缩数据。BigInsights 还为 Jaql 作业提供了自动适配运行时技术,可帮助提升目标应用程序的运行时性能。当启用 IBM 的自动适配 MapReduce 技术(通过属性设置或一个 Jaql 选项)时,Map 任务会通过 ZooKeeper 进行通信,以了解作业的全局状态。当这样做起作用时,Map 任务会动态承担额外工作,从而提高整个作业的运行时性能。
BigInsights 如何适用于企业数据架构
处理大数据成了许多公司的企业数据策略中不可缺少的一部分。实际上,许多组织都在寻找开发一种像 BigInsights 这样的软件平台,在引进公司后即可帮助他们管理大数据。将原始数据存储在 BigInsights 中之后,公司便可操作、分析和汇总数据,从而获得新的见解,并为下游系统提供数据。这样,就可以进一步处理原始数据和修改后的格式。
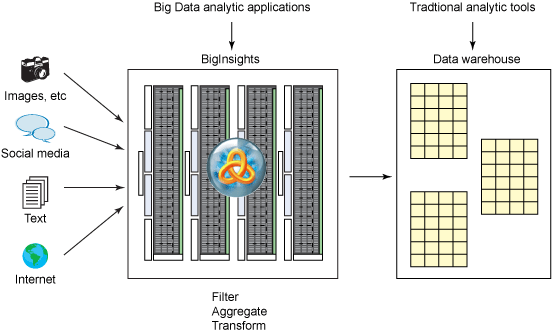
一种潜在的部署方法,是将 BigInsights 作为数据仓库的源。BigInsights 可以对大量的非结构化或半结构化数据进行筛选,捕获可增强数据仓库中现有企业数据的相关信息。图 7 举例说明了这样的一个场景,在该场景中,充许公司在不为现有系统增加过度负担的情况下扩展其分析范围。而在数据仓库中,传统业务智能和查询/报告编写工具可以处理存储在 BigInsights 中的原始数据的提取、汇总和转换部分。
图 7. 使用 BigInsights 筛选和汇总数据仓库的大数据
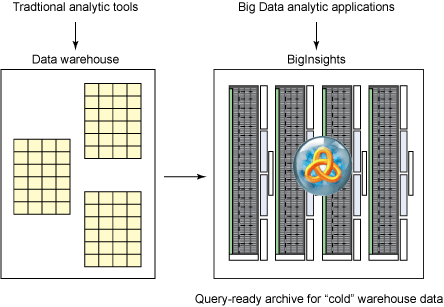
另一种潜在的部署方法是,将 BigInsights 作为数据仓库的查询就绪存档。使用此方法,图 8 中被频繁访问的数据就可以在仓库中进行维护,而 “很少访问” 或过时信息可卸载至 BigInsights。该方法允许公司管理与其现有数据管理平台同样大小的数据,而同时又可满足其现有应用程序需求。通过将不常查询的数据卸载至 BigInsights,可以保留应用程序在偶尔需要或突然需要使用数据的情况下对数据的访问。
图 8. 将 BigInsights 作为数据仓库的查询就绪存档
结束语
帮助公司管理和分析大数据并从中受益,这是 IBM 的一个重点关注区域。在本文中,向您介绍了 InfoSphere BigInsights,这是 IBM 推出的一款用于存储和分析此类数据的软件平台。基于开源技术和 IBM 开发的技术,BigInsights 提供了两个版本:免费的基础版(适用于探索性研究)和企业版(适用于生产应用程序)。
虽然大数据分析目前仍然处于初期阶段,但现在就开始将它应用于您的业务中为时并不算早。分析员和早期使用者通常都认为利用大数据分析是一个重要信息管理计划。
原文:http://www.ibm.com/developerworks/cn/data/library/techarticle/dm-1110biginsightsintro/
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。