12月10-12日,2015中国大数据技术大会盛大开幕,12日下午大数据分析及生态系统分论坛上,Hortonworks、IBM、京东、百度、eBay、银联智惠和南京大学的七位专家介绍了大数据分析及生态系统的进展。
2015年12月10-12日,由中国计算机学会(CCF)主办,CCF大数据专家委员会承办,中国科学院计算技术研究所、北京中科天玑科技有限公司与CSDN共同协办,以“数据安全、深度分析、行业应用”为主题的 2015中国大数据技术大会 (Big Data Technology Conference 2015,BDTC 2015)在北京新云南皇冠假日酒店盛大开幕。
2015中国大数据技术大会第三天的大数据分析及生态系统分论坛中,来自Hortonworks、IBM、京东、百度、eBay、银联智惠和南京大学的七位专家介绍了大数据分析及生态系统的进展。本次论坛由清华大学计算机系副教授张广艳主持。

清华大学计算机系副教授 张广艳
Hortonworks技术员于志宏:Recent developments in HBase
Hortonworks技术员于志宏演讲的题目是“Recent developments in HBase”。他从批量加载 HFile备份、端到端Offheap读路径优化、Slider上的HBase三部分详细讲解了HBase的最新进展。Replication中支持集群之间的数据同步,集群A可以把数据推送到集群B,集群B同样可以把它的一些新的写入再返回到集群A;同时支持循环复制;在表或者列级别上进行配置;它的实现是基于日志推送;在灾难恢复上,可以实现跨地域容灾的要求。
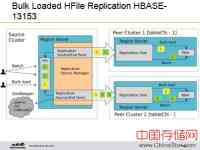
Replication状态存入ZooKeeper,缺省路径为:hbase/replication/peers。对于regionservers,对于每个Replication Overview会记录服务器的名字、端口,每一个Replication Overview可以向多个推送。对于Soure Cluster,有Batch、Bulk Load、Zookeeper,其中Bulk Load效率非常高。Region Server功能主要是协调。以前推送的只是写入的这些数据,比如说Peer Cluster1接受写入1,然后Peer2接受写入2,但是黄色背景就没有推送。HBase13153把以前的结构进行扩展,还有一些后续的工作要做。Cell在HBase应用已久,界面不容易改变。因此服务器端引入了ByteBuffers,它只在服务器端起作用,返回给用户的时候,返回给客户端的时候还是Cell。Cell在HBASE-13387升级扩展为为新的ByteBufferedCell 。

Hortonworks技术员 于志宏
于志宏提到当有任务时,YARN生成一个集群,对于多租户有两种方案。YARN在集群运行其代码,客户端可创建App Master(AM),AM向YARN Node Manager申请容器。对于Registration,应用必须发布自身的URLs、Host/port、Config 等信息;动态集群内,需要使用Discovery查找空闲端口。不同的客户端支持如果回调“数据”(thick clients)和可配置的网关(thin clients)。
对于监控,有Metrics和Alerts两种方式。前者以时间度量、瞬时度量;后者是基于JMX/端口扫描/容器状态或者Nagios的配置或其他警报机制。
接下来,他介绍了一些常见的故障处理,当应用组件出现问题时,组件实例需要重启;当AppMaster出现故障时,需要YARN重启AppMaster、Slider重构状态、更新注册表;当ResourceManager或者NodeManager出现故障时,应用不受影响。演讲最后,于志宏提到HBase Replication的同步时间受很多因素的影响,比如带宽等等。以前的Replication是直接把写入进行推送,新加一个可复制HDFS,对网络带宽要求比较高。
IBM数据和分析事业部大中华区大数据产品总监洪建勋:Spark数据和设计迎巨变
IBM数据和分析事业部大中华区大数据产品总监洪建勋分享的是“Spark数据和设计迎巨变”。目前大数据整个生态趋势是降低IT成本、数据存储成本,走向数据仓库扁平化、低成本化。客户最关心的是东西怎么去用,而非某项具体技术,由业务驱动技术的发展。他谈到,尽管Spark技术已经出现两三年之久,但是从目前实践的角度上来看,并不成熟,IBM愿同大家合作共同填补其中的坑。例如,IBM将机器学习库SystemML开源给了Spark社区。
在国外,客户联手IBM和Spark开始创新,收集海量数据进行分析应用。首先用于慢性病预防方面,INDEPENDENCE利用Spark技术从几百万的病人数据里面提取分析,进行发病的趋势预测。另外与普惠公司合作,利用Hadoop和Spark等技术,对发动机运行状况的分析和监测。这是机械控制和IT结合的领域,将数据分析倾向于制造业和工业。

IBM数据和分析事业部大中华区大数据产品总监 洪建勋
洪建勋表示,真正要做一个大数据的话实际上不只是单一的技术,还包含前端数据采集、预处理、数据仓库等等。以及其中的实时处理、实时分析、后期的数据挖掘,甚至是中间的联动环节、可视化处理,都需要用大数据来进行实现。IBM的大数据简易分析框架由前端数据采集、预处理、数据挖掘、可视化分析组成。IBM SQL基于Hadoop技术,用户可通过不同的方式访问数据。IBM相关的云方案:在IBM提供的云环境下面,用户可以得到IBM不同软件的相关服务,其中Spark的也可以用云的方式来做。
演讲最后,他谈到大数据的生态不仅仅是一个Hadoop或者Spark,开发者应重新利用旧的技术,不停地进行技术嫁接,发挥其更大的作用,这里他举了数据挖掘的例子加以证明。洪建勋表示IBM做大数据不仅仅是从技术层面出发,更多的是出于用户的角度。企业应该考虑怎么样把IT转换到真正发挥业务价值,这是非常重要的一点。离开业务价值谈大数据那还不是真正的大数据。
京东集团云平台数据首席架构师杜宇甫:构建大数据生态环境
京东集团云平台数据首席架构师杜宇甫分享的题目是“构建大数据生态环境”。本次分享只要是从宏观上面构建一个大数据生态。今天各个企业都很注重大数据,对于大数据积攒到今天,其实不是一蹴而就的,而是有一个漫长的累积过程。数据从最开始到最后,自古以来就数据产生的,由小数据到大数据的积攒,到目前为止经历五次大的信息革命。

京东集团云平台数据首席架构师 杜宇甫
数据分析环节包括数据采集、存储、建模、分析、应用。在数据采集阶段业内使用的产品和技术:Flume(NG)、Sqoop、Scribe、Camus。Flume可以日志文件搬运到计算机集群;数据存储:可运行于通用硬件之上盘分布式存储系统HDFS,其具有高吞吐量的超大文件处理能力且模型简单一致。兼容MapReduce和Spark内存分布式存储系统Tachyon:能提供插件式的底层文件系统和具有浏览文件系统的Web界面,并且具有高容错性;数据建模分析中常用的Spark MLlib、Mahout机器学习和Spark GraphX、Neo4j图计算方式;根据数据分析的使用场景,可以分为三种:批量处理数据库的过程Batch、针对各种临时的、自定义的需求采取的Ad-hoc解决方案、应用于实时性要求比较高的场景Streaming方案。
杜宇甫提到生态是指生物群落及其地理环境相互作用的自然系统,由无机环境生物的生产者、消费者以及分解者4部分组成。由生物群落和与之相互作用的自然环境以及其中的能量流过程构成的系统。生态的意义在于合作伙伴之间联合作战,实现共赢。

京东数据云系统依托京东公有云稳定强大的IAAS底层服务系统,将公有云云存储、云数据库等基础设施做为数据存储层。云数据库、云存储可做为数据源;云数据库、云存储可做为数据数据分析结果输出目的地。京东数据集群(Big Data Service,BDS)使用Hadoop开源框架,支持自动配置集群并动态调整;支持离线数据处理和流式数据处理;目前主要应用于数据分析、挖掘、商业智能等领域。京东生态云是用户可用的云服务:在上层提供分析工具;在云端提供云存储、云分析、云海,提供开发者使用的数据集群以及实时分析。管理员可通过京东数据云管理数据网关。最后,他强调任何数据要有自己的市场,否则没有任何价值。
百度大数据部高级研发工程师衣国垒:通过ElasticSearch进行大数据分析
百度大数据部高级研发工程师衣国垒演讲主题是“通过ElasticSearch进行大数据分析”。分布式的架构ElasticSearch最初构建在Lucene搜索引擎上,采用分布式索引和多副本高可靠的分布式的架构。近年来由全文检索系统转变为数据分析平台。ElasticSearch最基本的结构Index类似于Database,是数据的物理管理方式。其中一个Index被划分为多个Shard,每个Shard可以有多个副本,副本通过REST API来访问;目前ElasticSearch存储的数据格式实际上是Json文档接,包括非结构化普通文本和半结构化日志、邮件文档。利用ID Hash来将数据划分到各个Shard上,在导入时支持对文本进行分词处理;查询方面,ElasticSearch中采用用Json来描述查询语句,同时支持MPP的方式查询所有相关的Shard。

他认为ElasticSearch的兴起与近年来的生态密不可分。目前ElasticSearch通过插件机制对底下各种数据源打通,推送到ElasticSearch中的数据目前已经能够和Hadoop生态环境进行打通,做批量数据分析。同时它自身也可以做数据分析,像在线的查询请求也可以通过ElasticSearch自身得到满足,而不必依赖于离线高延时的处理系统。
ElasticSearch具有多维分析、实时性、易用性、Flexible Schema等优势,支持Json格式的数据,支持嵌套、集合、父子关系多种模式。并且ES的单节点100GB/小时的加载能力满足大部分需求。

百度大数据部高级研发工程师 衣国垒
百度在两年前使用ElasticSearch,目前覆盖百度内部40多个业务线;单集群每天导入30TB+数据,总共每天60TB+;单集群最大100台机器,200个ElasticSearch节点;共使用近400台机器,启动700+ElasticSearch节点。在ElasticSearch实践中:监控业务中采用动态字段,按照一律接受或者一律拒绝的规则来接受、处理。同时使用冷热数据分离进行数据数据写入和数据迁移;OLTP业务集成中ElasticSearch可与RDBMS互补、融合使用;跨机房部署方案中部署一个跨机房的集群,使用zone aware的方式部署,同时强制一个Shard的各个Replica分布在多个机房里。在MapTask机制、开放云等方式,ElasticSearch也发挥了很大的作用。
eBay 软件工程师、Apache Kylin PMC 成员仲俭:Apache Kylin的大数据可视化实践

eBay 软件工程师、Apache Kylin PMC 成员 仲俭
eBay 软件工程师、Apache Kylin PMC 成员仲俭做了题为“Apache Kylin的大数据可视化实践”的演讲。Kylin是Hadoop平台中OLAP,由eBay贡献出来,于2014年10月正式开源;2014年11月加入Apache孵化器;2015年11月正式毕业成为Apache顶级项目。仲俭首先介绍了Kylin在京东的应用案例:在OLAP分析分析方面,能做到单个Cube最大维度16个、最大数据条数100亿、最大存储空间400G、 95%的查询响应时间在15秒以内;原始明细数据查询方面,能做到单个Cube最大维度8个、最大数据条数4亿、最大存储空间800G。30个Cube占用总空间4T左右、查询QPS在50左右、所有查询平均响应时间200ms、 查询QPS在200左右平均响应时间可以保持在1s以内。
仲俭随后介绍了Apache Kylin REST API,包括Hive Metadata、Cube、Job和Query。其中Hive Metadata又包括Get Hive Table、Get Hive Table (Extend Info)、Get Hive Tables、Load Hive Table。Kylin自带有非常丰富的可视化的接口。本身UI里面就有查询界面,用户可利用SQL查询结果,列出表格包括对应趋势图、饼图。利用Tableau,其它业务业务人员可以将自己的平台与Kylin集成。Kylin同样支持PowerBI、Excel等。

Kylin关键在于其提前计算,将颜色、大小等维度提出后由Hadoop进行处理。Apache Kylin 与 Zeppelin进行了整合和二次开发。开发人员可在Zeppelin架构下自行开发后端,仅需利用Kylin Interpreter;同时Zeppelin上对应的语句,可在其他平台上同样运行。当业务用户多维分析的时候有不同组合,数据模型相对比较固定,不管是年月日还是季度周的,Kylin 内部很多东西已经提前算好了,如果该组合不存在,Kylin可以进行实时计算加以实现。920多亿数据情况下,90%的查询在1.5秒以内。预计算不可避免的问题是模型固定,业务人员在分析某些数据的时候并不需要非常动态的做这些东西的,Kylin内部完全可以支撑动态数据模型,支持原数据在几个维度或与新的数据组合。
银联智惠联合创始人兼CTO龙凯:银联智惠消费大数据解决方案

银联智惠联合创始人兼CTO 龙凯
银联智惠联合创始人兼CTO龙凯给带来的分享是“银联智惠消费大数据解决方案”。银联智惠数据挖掘技术框架:银联大数据平台、数据预处理层、模型算法层、产品应用层。其中数据预处理层中采用了海量数据清洗技术、数据加密及脱敏技术、海量技术分层技术、数据整合技术。
银联智惠数据挖掘技术。一是基于逻辑回归的消费轨迹预测模型:利用先验知识与后验规则结合的方法,构建决策树模型,通过在海量刷卡数据中反复迭代计算,最终实现对上亿持卡人用户画像。二是基于聚类算法的商圈模型:基于消费者刷卡行为轨迹,利用统计方法,构建商户距离矩阵;利用聚类算法,将附近商户聚合成为商圈,从而支持城市热门商圈分析、基于商圈的精准营销等应用。

数据安全、数据隐私、数据产权是大数据产业链三大基础。商业智能是指通过对数据的收集、管理、分析以及转化,使数据成为可用的信息,从而获得必要的洞察力和决策力,更好地辅助决策和指导行动。用户画像是一种勾画目标用户特征、了解用户诉求,以及指导产品设计及营销的有效工具,用户画像在各领域得到了广泛的应用。他详解了用户标签实现过程:
- 用户刷卡消费后将会产生一系列消费信息;
- 利用银联智惠用户模拟器系列模型对用户历史消费特征进行计算;
- 利用模型计算结果为用户打上一系列消费特征标签;
- 通过数十个维度的特征指标,对用户群体进行消费特征分析,帮助商户勾勒出详细的用户群特征。
智慧金融中,通过大数据分析客户目标特点,实现信贷周期一体化解决方案。结合审批过程中由繁至简的流程,为不同应用场景需求的客户,提供金字塔形的数据挖掘成果。
智慧安全云通过收集各类内外数据,利用Hadoop等基础设施查询、统计、分析,以云基础平台为依托,构建集中资源池,实现不同用户的虚拟资源隔离,提供稳定、高效、丰富的服务。
南京大学计算机系PASA大数据实验室教授黄宜华:Octopus(大章鱼):基于R语言的跨平台大数据机器学习与数据分析系统

黄宜华认为大数据+机器学习是驱动全球互联网企业的核心。大数据机器学习是一个同时涉及到机器学习和大数据处理两个主要方面的交叉性研究课题。面向大数据复杂分析挖掘,现有的串行化机器学习与数据挖掘算法都需要重写,进行并行化设计以及不同的大数据并行处理平台上,各种大数据机器学习与数据挖掘算法需要进行基于特定平台的并行化算法设计等问题的存在,迫切需要研究提供一种统一化并易于使用的大数据机器学习系统支撑平台。
可通过系统抽象来降低大数据机器学习系统设计的复杂性,比如上层算法研究人员无需学习底层大数据处理系统平台使用。目前基于主流大数据平台的并行化机器学习算法/算法库
基于Hadoop MapReduce和Spark、以及基于传统的MPI并行计算框架等。这里他举了百度ELF与百度机器学习云平台BML和腾讯Peacock与Mariana深度学习平台等实例加以说明。

Octopus是面向大数据的跨平台统一MLDM编程模型、框架和系统平台,针对不同平台开发了不同的大规模矩阵运算库。对于专业性程序员来说,提供一个跨平台统一的大叔聚集起学习和数据分析编程方法和平台,实现“Write once,run anywhere”的特性,以避免针对不同的大数据平台重写所有大数据起学习和数据分析算法。
大规模矩阵计算是机器学习与数据挖掘以及其他诸多计算问题的建模表示方法。该系统完成了大规模矩阵运算并行化计算方法和算法,实现了完整的大规模分布式矩阵运算库,且具有良好的可扩展性。其中OctMatrix:一个基于R的大规模分布矩阵计算库,提供高层和平台独立的分布矩阵计算操作和编程接口,允许从R语言程序中直接调用。
目前大章鱼系统已经与Spark、Hadoop MapReduce、MPI以及最新的Flink系统无缝集成,并实现这些底层大数据平台对上层程序员的完全透明性。该系统易于使用、基于矩阵模型的高层编程接口;具有Write Once、Run Anywhere的跨平台特性;可提供基于矩阵模型的机器学习和数据挖掘算法库;与标准R语言环境无缝集成。

南京大学计算机系PASA大数据实验室教授 黄宜华
黄宜华最后提到,Octopus仍在扩展:第一个扩展,除了R语言也支持其他语言;第二个扩展,目前也在考虑支持表模型,综合在该系统上,简单分析和复杂分析都揉和在一个平台上,然后进行综合的分析。
更多精彩内容,请关注直播专题 2015中国大数据技术大会(BDTC),新浪微博@CSDN云计算,订阅CSDN大数据微信号。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。

































