这篇文章里介绍了Nginx502BadGateway错误产生的原因与解决办法,希望对于初学Nginx服务器相关的朋友有帮助,更多Nginx安装、配置、报错处理等资源请本站内搜索。。
Nginx 502错误的原因比较多,是因为在代理模式下后端服务器出现问题引起的。这些错误一般都不是nginx本身的问题,一定要从后端找原因!但nginx把这些出错都揽在自己身上了,着实让nginx的推广者备受置疑,毕竟从字眼上理解,bad gateway?不就是bad nginx吗?让不了解的人看到,会直接把责任推在nginx身上,希望nginx下一个版本会把出错提示写稍微友好一些,至少不会是现在简单的一句 502 Bad Gateway,另外还不忘附上自己的大名。
Nginx 502的触发条件
502错误最通常的出现情况就是后端主机当机。在upstream配置里有这么一项配置:proxy_next_upstream,这个配置指定了 nginx在从一个后端主机取数据遇到何种错误时会转到下一个后端主机,里头写上的就是会出现502的所有情况拉,默认是error timeout。error就是当机、断线之类的,timeout就是读取堵塞超时,比较容易理解。我一般是全写上的:
proxy_next_upstream error timeout invalid_header http_500 http_503;
不过现在可能我要去掉http_500这一项了,http_500指定后端返回500错误时会转一个主机,后端的jsp出错的话,本来会打印一堆 stacktrace的错误信息,现在被502取代了。但公司的程序员可不这么认为,他们认定是nginx出现了错误,我实在没空跟他们解释502的原理 了……
503错误就可以保留,因为后端通常是apache resin,如果apache死机就是error,但resin死机,仅仅是503,所以还是有必要保留的。
解决办法
遇到502问题,可以优先考虑按照以下两个步骤去解决。
1、查看当前的PHP FastCGI进程数是否够用:
netstat -anpo | grep "php-cgi" | wc -l
如果实际使用的“FastCGI进程数”接近预设的“FastCGI进程数”,那么,说明“FastCGI进程数”不够用,需要增大。
2、部分PHP程序的执行时间超过了Nginx的等待时间,可以适当增加nginx.conf配置文件中FastCGI的timeout时间,例如:
......
http
{
......
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
......
}
......
php.ini中memory_limit设低了会出错,修改了php.ini的memory_limit为64M,重启nginx,发现好了,原来是PHP的内存不足了。
如果这样修改了还解决不了问题,可以参考下面这些方案:
一、max-children和max-requests
一台服务器上运行着nginx php(fpm) xcache,访问量日均 300W pv左右
最近经常会出现这样的情况: php页面打开很慢,cpu使用率突然降至很低,系统负载突然升至很高,查看网卡的流量,也会发现突然降到了很低。这种情况只持续数秒钟就恢复了
检查php-fpm的日志文件发现了一些线索
Sep 30 08:32:23.289973 [NOTICE] fpm_unix_init_main(), line 271: getrlimit(nofile): max:51200, cur:51200
Sep 30 08:32:23.290212 [NOTICE] fpm_sockets_init_main(), line 371: using inherited socket fd=10, “127.0.0.1:9000″
Sep 30 08:32:23.290342 [NOTICE] fpm_event_init_main(), line 109: libevent: using epoll
Sep 30 08:32:23.296426 [NOTICE] fpm_init(), line 47: fpm is running, pid 30587
在这几句的前面,是1000多行的关闭children和开启children的日志
原来,php-fpm有一个参数 max_requests,该参数指明了,每个children最多处理多少个请求后便会被关闭,默认的设置是500。因为php是把请求轮询给每个 children,在大流量下,每个childre到达max_requests所用的时间都差不多,这样就造成所有的children基本上在同一时间 被关闭。
在这期间,nginx无法将php文件转交给php-fpm处理,所以cpu会降至很低(不用处理php,更不用执行sql),而负载会升至很高(关闭和开启children、nginx等待php-fpm),网卡流量也降至很低(nginx无法生成数据传输给客户端)
解决问题很简单,增加children的数量,并且将 max_requests 设置未 0 或者一个比较大的值:
打开 /usr/local/php/etc/php-fpm.conf
调大以下两个参数(根据服务器实际情况,过大也不行)
<value name=”max_children”>5120</value>
<value name=”max_requests”>600</value>
然后重启php-fpm。
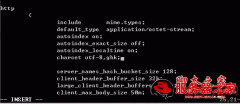
二、增加缓冲区容量大小
将nginx的error log打开,发现“pstream sent too big header while reading response header from upstream”这样的错误提示。查阅了一下资料,大意是nginx缓冲区有一个bug造成的,我们网站的页面消耗占用缓冲区可能过大。参考老外写的修 改办法增加了缓冲区容量大小设置,502问题彻底解决。后来系统管理员又对参数做了调整只保留了2个设置参数:client head buffer,fastcgi buffer size。
三、request_terminate_timeout
如果主要是在一些post或者数据库操作的时候出现502这种情况,而不是在静态页面操作中常见,那么可以查看一下php-fpm.conf设置中的一项:
request_terminate_timeout
这个值是max_execution_time,就是fast-cgi的执行脚本时间。
0s
0s为关闭,就是无限执行下去。(当时装的时候没仔细看就改了一个数字)
发现,问题解决了,执行很长时间也不会出错了。
优化fastcgi中,还可以改改这个值5s 看看效果。
php-cgi进程数不够用、php执行时间长、或者是php-cgi进程死掉,都会出现502错误。
四
在php.ini里,eaccelerator配置项一定要放在Zend Optimizer配置之前,否则也可能引起502 Bad Gateway
五
磁盘空间不足,如mysql日志占用大量空间清理一下磁盘上的文件,有部分剩余空间,重启即可恢复。
六
查看php-cgi进程是否在运行
七、也可以尝试将unix套接字改成tcp/ip的,修改/usr/local/php/etc/php-fpm.cnf 里设置<value name=“listen_address”>/tmp/nginx.socket</value> 改成<value name=“listen_address”>127.0.0.1:9000</value> ,同时/usr/local/nginx/conf/nginx.conf 及其/usr/local/nginx/conf/vhost/ 下面的虚拟主机配置里的fastcgi_pass unix:/tmp/php-cgi.sock; 替换为fastcgi_pass 127.0.0.1:9000; 之后重启试试。
八、如果虚拟主机的日志文件过大也可能会造成502问题。
建议定期清空一下虚拟主机的日志文件。
九、有些程序或者程序的主题有死循环或其他非常占用资源的代码也可能会引起502,可以尝试暂时注释掉可能的主机的配置文件,重启看看是否还会502。
十、如果以上方法都试过,但还有时会出现502错,可以尝试添加502自动重启脚本
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。