Apache HBase 0.96.0 发布,分布式数据库
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作...
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作...

安全、交通行业。这些行业目前也面临着大数据的考验,但是当前很多流行的NoSQL数据库对于他们来说并不适用,所以他们自主研发了一个NoSQL数据库管理系统。...

数据导入HBase最常用的三种方式,HBase有一个名为 bulk load的功能支持将海量数据高效地装载入HBase中。Bulk load是通过一个MapReduce Job来实现的,通过Job直接生成一个HBase的内部HFile格式文件来形成一个特殊的HBase数据表,然后直接将数据文件加载到运行的集群中。...

在HBase根目录下的.logs文件夹。.logs目录下面为每一个HRegionServer单独创建一个文件夹,每一个文件夹下有几个HLog文件(因为log rotation)。每一个HRegionServer的所有region都共享一个HLog文件。...

hbase峰会上,小米介绍了十几个业务接入到了HBase上,包括米聊消息的全存储、MiCloud上短信通话记录的同步、小米Push服务、以及一些离线的数据分析业务。...
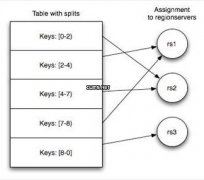
当Table随着记录数不断增加而变大后,会逐渐分裂成多份splits,成为regions,一个region由[startkey,endkey)表示,不同的region会被Master分配给相应的RegionServer进行管理。...

在 HBase: The Definitive Guide 中, Lars George 介绍了 HBase 的一个新特性 Counter Increment,至于 increment 的性能如何,我们只有做测试才能知道。YCSB 已经提供了 Read-Modify-Write 的测试接口,而 increment 接口需要自己完成2。...
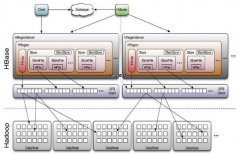
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作...
京东作为国内最大的综合网络零售商,随着业务数据量爆发式增长,传统的关系数据库在海量数据面前开始显得捉襟见肘,于是京东云平台在Hadoop生态集群经验积累的基础上,引入了HBase作为海量数据存储的基础设施。全部避免代码浸入性,所有开发都不会更改原有HBase的代码。...

Apache Hive是一个构建于Hadoop(分布式系统基础架构)顶层的数据仓库,Apache HBase是运行于HDFS顶层的NoSQL(=Not Only SQL,泛指非关系型的数据库)数据库系统。区别于Hive,HBase具备随即读写功能,是一种面向列的数据库。...
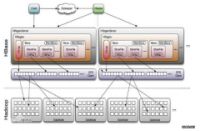
Hadoop已经在淘宝、百度、FaceBook、Yahoo这样的信息科技巨擘中得到广泛使用,它已经成为大数据解决方案领域最为成熟的平台方案。本次冼茂源将会分享一些HBase相关的技术内容。...