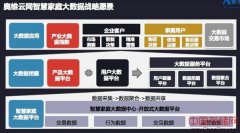
作为一家提供存储服务的机构,七牛需要强大的数据平台来支撑其运营数据,其主要业务包括:公司基础运营数据分析、运维需求信息提取,以及为开发和技术支持工作提供信息支持。
明晚(北京时间7月29日)20:30,继“
YARN or Mesos?Spark痛点探讨”、“
Mesos资源调度与管理的深入分享与交流”、及“
主流SQL on Hadoop框架选择”之后,CSDN Spark微信用户群邀请了王团结为大家分享Hadoop/Spark在七牛数据平台的实战。
嘉宾简介
王团结,七牛数据平台工程师,主要负责数据平台的设计研发工作。关注大数据处理,高性能系统服务,关注Hadoop、Flume、Kafka、Spark等离线、分布式计算技术。
分享简介
作为一家提供存储服务的机构,七牛需要强大的数据平台来支撑其运营数据,其主要业务包括:第一,公司业务的基础运营数据,比如流量和存储信息;第二,运维需求信息提取,用以量化线上服务的体量质量;第三,为开发和技术支持工作提供信息支持,主要是日志的存储检索归档。
对于一家一直在摸索技术的公司来说,不停的挖坑和趟坑是不可能避免的情况,七牛数据平台架构的衍变同样伴随着这一历程。在平台打造之初,抱着“如此体量业务都可以支撑,何况业务产生的区区数据”的想法,对于数据的收集、存储和计算,七牛都自造车轮。然而,随着业务量的剧增,各种问题随之而来,而基于公司配备的人力和物理(机器)资源,自主研发数据平台显然得不偿失,为此团队开始拥抱Flume、Kafka、Hadoop、Spark等开源技术,倾力打造数据平台。
参与方式
1. 微信群2已超过100人,请扫下方二维码,工作人员会邀请进入。(注:CSDN Spark用户微信群1已满500,正在清理并邀请2群用户进入)

2. 加入CSDN Spark技术交流QQ群,群号:213683328。
3. CSDN高端专家微信群,采取受邀加入方式,不惧高门槛的请加微信号“zhongyineng”或扫描下方二维码,PS:带上你的BIO。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。