内存计算引擎相对于传统数据处理引擎,最大的革新是基于LLVM编译器的动态代码生成技术,这篇文章将介绍现在的产品和技术是如何使用LLVM编译器来动态生成执行代码的,从而实现真正意义上的内存计算,及认识LLVM技术本身。
最近业界有很多技术和产品都被认为属于内存计算的范畴,并且大家都觉得内存计算是未来大数据方面的核心技术,特别是类似Spark和HANA这样的产品和技术涌现,使得内存计算已经在大数据技术方面成为主流。但身为一个在内存计算方面研究3年左右的笔者,感觉很多人对于内存计算的理解仅停留在把数据缓存在内存中,或者使用最新的SIMD指令集,但笔者在这三年的研发过程中的最大发现并不是这样,我个人觉得内存计算引擎相对于传统数据处理引擎,最大的革新是基于LLVM编译器的动态代码生成技术,所以本文将给大家介绍现在的产品和技术是如何使用LLVM编译器来动态生成执行代码的,从而实现真正意义上的内存计算,那么在深入这个技术之前,想给大家稍微介绍一下LLVM的技术本身。
LLVM-移动时代的幕后英雄
LLVM是Low Level Virtual Machine的简称,首先,大家不要被这个名字所误导,认为它是类似VMware和KVM这样的虚拟机项目,其实它是一个类似GCC的大型编译器框架。而LLVM这个名字本身随着这个项目不断发展,已经无法完全代表这个项目了,只是作为这种叫法一直延续下来。
作为编译器,LLVM本身和GCC一样,是一个开源的项目,协议是BSD,而不是Linux和GCC所用的GPL协议。它最早的时候是伊利诺伊大学厄巴纳香槟分校的一个研究项目,主要负责人是大牛Chris Lattner,并且项目本身也很荣幸地获得2012年ACM软件系统奖。
LLVM可以作为多种语言的后端,它可以提供可编程语言无关的优化和针对很多种CPU的代码生成功能,与GCC相比,它的整体架构更清晰,速度更快,此外,LLVM已经不仅仅是个编程框架,它目前还包含了很多子项目,比如最具盛名的用于C编译的Clang,除此之外,还有用于链接GCC前端解析器的Dragonegg等项目。
虽然LLVM对于很多程序员而言是一个陌生的名词,但是在整个移动时代起到了至关重要的作用,无论是Android还是iOS平台。
对于iOS平台而言,Chris Latter现在就职于Apple,而且Apple目前也是LLVM主要赞助者之一。在iOS之前,LLVM的诞生就给OSX本身的开发带来极大的帮助,因为当时Apple困于GCC无法提供给他们完善的支持,特别是和Object-C相关的编译部分,而当时LLVM项目的出现帮助他们解决燃眉之急,包括后面Grand Dispatch这样的核心功能都有LLVM的影子。到了iOS时代,LLVM已经是整个iOS平台最底层的核心,无论从iOS系统本身的编译,以及XCode的调试支持,还是最新的语言Swift也都是由LLVM之父Chris Latter本人设计的。
尽管Android平台是iOS平台的对手,但Android平台对LLVM依赖更盛,虽然4.4之前都是用自建的Dalvik VM,使用类似JIT(Just-in-time Compiler)这样即时编译的形式来执行,但是在性能和用户体验方面被大家所诟病,所以在Android的4.4版本推出了ART模式,ART是直接使用LLVM去做AOT(Ahead of Time)编译,也就是在安装的时候直接将程序编译为机器码,平时Android用户使用App的时候能像iOS用户一样直接执行本地代码,这样使Android的整体性能已经接近iOS的水准,虽然在安装的时候,可能需要多花点时间用于做预编译。所以LLVM可谓是移动时代的幕后英雄,那么它和传统的数据处理有什么关系呢?在深入介绍LLVM是如何改变传统数据处理引擎之前,让我们先了解一下传统数据处理引擎的短板。
传统数据处理引擎的短板
众所周知,最初传统数据处理引擎(比如Postgres,Oracle等)的主要瓶颈在于I/O,因为当时底层硬盘的速度实在乏善可陈,多年没有进步,但是随着近几年多节点并行,SSD,大内存等I/O资源的发展,更重要的是列存技术的普及和进化,使得I/O问题已经不再是一个极大的瓶颈,但随之而来的就是在网络和CPU方面的瓶颈反而显现出来,由于网络瓶颈不是本文关注的重点,所以主要聊聊数据处理引擎CPU方面的瓶颈。

图1 繁琐的数据处理引擎代码
虽然新一代基于内存的计算引擎,使得I/O性能比传统基于硬盘有10倍左右的性能提升,但与之同时,CPU的瓶颈会更明显,基于我们之前测试结果,以传统Postgres的引擎为例,操作数据都被缓存到内存的Page Cache上面,它做最简单的Count(*)统计都只能勉强达到每秒钟400万行左右,而真实所需要的操作其实是很少的,按照2010年的X86 CPU而言,其实处理这些计算是非常简单的,但实际性能还是很低,为什么呢?在这里,先和大家聊聊现在X86 CPU性能特征,随着技术本身的发展,X86 CPU本身的处理能力非常强大,但是一切换Context就会出现性能方面的小滑坡。如果等待处理的命令和数据没有被预缓存在Cache上面,而是需要访问的内存的话,会有一个更大的性能滑坡。既然大家都了解CPU本身的瓶颈,下面来聊聊传统数据库处理引引擎的短板有哪些?主要有以下四点:
其一是条件逻辑冗余,数据处理引擎代码非常繁琐,因为SQL语句本身非常复杂,所以数据引擎为了支持那些复杂的SQL语句,使得数据处理引擎需要复杂的条件逻辑来处理,就像图1那样,甚至一个Switch循环里面会有成百上千的case这样的选择逻辑,虽然Switch循环本身会被编译器进行一定程度的优化,但是最终机器码中的分支指令会一定程度上阻止指令的管道化(instruction pipelining)和并行执行(instruction-level parallelism)。
其二是虚函数的调用,和第一个问题的原因类似,因为数据处理引擎要支持极为复杂的SQL语句,还有十几种的数据类型,比如,程序在处理add这个逻辑的时候,此时数据处理引擎需要根据来源数据是INT还是BIGINT来选择不同的函数来处理,所以在实际处理时,肯定只能用虚函数来转给具体的执行函数,这个对CPU的影响肯定是非常明显的,因为很多时候虚函数调用本身的运行成本,比这个函数本身执行成本更高。更因为如此,内联函数这个最常见的性能优化方式也无法被使用。
其三是需要不断地从内存中调用数据,而无法一次性将数据从内存加载至Cache上,比如,常见的For循环,虽然知道下一个数据就在下一个偏移地址,但还是要从内存上面读取,这样读取开销很大而且阻止整个CPU管道化的操作。
其四是因为不同x86 CPU年代不同,所以支持不同扩展指令集,而这些新的指令集对很多操作都能提升100%以上的性能,比如,有些比较新的CPU支持SSE 4.2,而有些却不支持,为了保证数据引擎能跨不同的硬件平台,所以数据引擎很少支持一些扩展的指令集,这导致浪费了本来可以提升的性能没有得到支持。
虽然这些瓶颈很难克服,但Google研发的Tenzing技术里面提出基于LLVM编译框架实现动态生成代码Codegen这个技术,并且通过这个技术基于MapReduce分布式框架下面的类SQL系统的性能也能接近商业收费并行数据库的水准。Codegen这种方式,就是在SQL执行前才编译具体的执行代码,之前的数据引擎本身是一个大而复杂的框架,任何计算包括1+1,都要进入这个庞大的框架里面做判断来选择合适的函数来执行1+1,所以最终的成本就像前面列的那样,是非常高的。那么使用Codegen的好处如下:
其一是简化了条件分支,因为在生成代码的时候,程序已经获知运行时的信息,通过展开for循环(因为我们已经知道循环次数)和解析数据类型,所以可以像图2那样if/switch这些分支指令这样的语句就能优化掉,这是非常简单有效的。

图2 if/switch分支指令语句
其二是内存加载,我们可以使用代码生成来替代数据加载,这样极大减少内存的读取,增加CPU Cache的利用率,这对CPU性能而言非常有帮助。
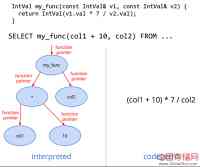
图3 用代码生成取代虚函数的调用
其三是内联虚函数的调用,因此当对象实例的类型在运行时可知,我们可以如图3所示使用代码生成来取代虚函数的调用,并做内联化,这样表达式可以无需函数调用而直接求值。此外,内联后的函数使编译器做进一步的优化,例如子表达式消除等。
其四是能利用最新的指令集,在Codegen的时候,由于Codegen本身是在即将执行的那个节点执行,所以它很方便就能感知到其底层CPU到底支持那个版本最新的指令集,比如是SSE 4.2还是SSE4.1,所以Codegen完全会根据具体的指令集支持来编译具体的执行代码,使其能尽可能地利用最新的指令集。

图4 基于TPCH-Q1的基准测试
基于图4的测试结果(跑TPCH-Q1,数据量2.7GB,单节点,Codegen时间150ms),通过这样的Codegen方式的确能有效地提升数据处理引擎利用CPU的效率,整体性能提升达到3倍以上,并且Cache Miss率和之前比重大提升。当然Codegen技术就像其他技术一样,它也有自己的成本和不足,那就是在Codegen本身的代码生成操作也是需要一定的时间,包括For循环展开和多层次pass优化,虽然LLVM本身的处理性能强,但是这样操作还是很耗时,一般都要100-200ms左右,但原本一个10秒钟的查询却因次提升到了6秒,我相信大家都能理解。
基于LLVM的动态代码生成技术
业界已经有越来越多的内存计算产品采用基于LLVM的动态代码生成技术,已经有成为内存计算标配的趋势,除了上面提到在Google内部大范围使用的Tenzing外,还有Cloudera Impala和SAP HANA也在使用Codegen技术,另外内存领域当红的Spark,也计划在接下来的版本中实现Codegen。
Cloudera Impala的实现方式
虽然Cloudera Impala在业界毁誉参半,貌似现在在Cloudera内部也准备放弃Impala,改方向往Spark发展,但是Impala在性能方面还是很受到大家的认可,主要原因就是其使用基于LLVM的动态代码生成技术。为什么采用Codegen?除了性能好之外,另一个因素就是Impala的首席设计师本身就是Google Tenzing的设计师。
那么让我们看看Cloudera Impala的具体实现方式。由于在运行时候将执行逻辑代码动态生成机器代码,成本会很高,所以Impala在编译的时候,会先将具体的一些执行函数先编译成LLVM的IR(Intermediate Representation)这个中间形态,从而生成一个大的IR文件,里面包括所有相关函数的IR代码块,之后在具体SQL命令执行开始之前,数据节点DataNode会先根据具体的SQL语句,从根节点开始递归初始化执行树(AST),之后开始LLVM会根据执行树来调用那个IR文件里面对应函数的IR代码块来生成本地可执行代码,接着会继续对生成好的代码进行优化来进一步提升性能。
SAP HANA的设计思路
其实至少十年前就有一波内存计算的风潮,那时企业级产品中,具代表性的主要有用于OLTP事务加速的Timeten和Altibase,而2010年开始推广的那些内存计算技术产品中,最有代表性的莫过于SAP的HANA。
SAP HANA在处理逻辑上,全面采用向量计算(Vector Processing)的理念,尽可能地使用最新的SSE4.1和SSE4.2等指令集,还有就是在多核NUMA场景下降低运行消耗,使其多线程性能提升比尽可能地接近1。另外,在数据结构方面,为了尽可能地利用CPU缓存(Cache),并尽可能减少访问内存,所以推出了缓存敏感的CSB(Cache Sensitive B+)树来代替传统的B树。
为了进步提升,并且完善整体架构和提升性能,HANA也使用了LLVM支持动态编译,无论是SQL查询还是MDX(Multi-Dimensional Expressions,多维表达式)查询等,在HANA内部都会都被转译一个公共的表示层,名为L语言,并且在执行之前,会使用LLVM编译为二进制代码并直接执行,这样做的好处是避免传统数据库引擎里面繁琐逻辑,从而提升性能,并且这样L语言的形式,对于HANA今后添加更多的功能非常有帮助,所以HANA在很短的时间内支持很多SQL分析语句之后,还支持各种数据挖掘的算法,还提供很多定制化脚本,让用户根据自己的业务需求来扩展HANA的功能。
Apache Spark的设计思路
大家都知道,现在Apache Spark可以说是最近最火的开源大数据项目,就连EMC旗下专门做大数据Pivotal公司也开始准备抛弃其自研十几年GreenPlum技术,转而投入到Spark技术研发当中。并且从整个业界来看,Spark火的程度也只有IaaS界的OpenStack能相提并论。那么我们接着就直接切入它的核心机制吧。
Spark已经将代码生成用于SQL和DataFrames里的表达式求值(expression evaluation),同时他们正准备努力让代码生成可以应用到所有的内置表达式上,并且在这个基础上支持更多新指令集。还有他们不仅通过Codegen内部组件来提升CPU效率,还期望将代码生成推到更广泛的地方,比如,数据的序列化,也就是Shuffle数据再分布的过程中,将数据从内存二进制格式转换到wire-protocol这样流格式的过程,因为Shuffle通常会因数据系列化而出现性能瓶颈,而通过代码生成,可以显著地提升序列化吞吐量,从而反过来作用到shuffle网络吞吐量的提升。

图5 shuffle性能分析
图5对比了单线程对800万复杂行做shuffle的性能,分别使用的是之前Kryo方式和最新代码生成,在速度上后者是前者的2倍以上。
最后,笔者觉得这个技术所带来在内存计算部分的效应只能说是整个蝴蝶效应最开始的那部分,今后对整个云计算会带来更多的变革。你能想象中间件和数据库合二为一吗?你能想象所有的业务代码和基础设施代码都动态生成吗?你能想象当整个百万台云计算集群被合并为一个大电脑的时候,数据和命令都合二为一吗?而这些就是我认为LLVM给我们带来的巨大变革,而我们中国人在这场浪潮中应该起着领导的角色。
 作者:吴朱华
作者:吴朱华
简介:上海云人信息科技有限公司联合创始人兼CEO,国内资深的云计算和大数据专家,之前曾在IBM中国研究院参与过多款云计算产品的开发工作。2010年底,他和另两位创始人组建了一支十多人的团队,在上海杨浦云基地办公。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。