为了关注分布式计算,该阅读哪些资讯文章呢?这些问题都能够被话题模型所解答。这篇文章将要讨论Spark1.4和1.5使用强大的隐含狄利克雷分布(LatentDirichletAllocation,LDA)算法对话题模型的性能提升。
这篇文章由Databricks的Feynman Liang和Joseph Bradley,以及Intel的Yuhao Yang撰写。
在使用LDA之前,请先 下载Spark 1.5或是 申请试用版的Databricks。
人们正在推特上讨论什么呢?为了关注分布式计算,我该阅读哪些资讯文章呢?这些问题都能够被话题模型所解答,它是分析文档集所涵盖话题类别的一种技术。本文将要讨论Spark 1.4和1.5使用强大的隐含狄利克雷分布 (Latent Dirichlet Allocation,LDA)算法对话题模型的性能提升。
Spark 1.4和1.5引入了一种增量式计算LDA的在线算法,在已训练的LDA模型上支持更多的查询方式,以及支持似然率(likelihood)和复杂度(perplexity)的性能评估。我们给出了一个例子,用超过450万条维基百科词条的文档集训练一个话题模型。
话题模型和LDA
话题模型分析一个大规模的文档集,并且自动推测其所讨论的话题。举个例子,我们用Spark的LDA算法训练450万条维基百科词条,可以得到下表中的这些话题。

表一:用维基百科文档集训练得到的LDA话题示例
此外,LDA告诉我们每篇文档分别属于哪些话题;文档X有30%的概率属于话题1(“政治”)以及70%的概率属于话题5(“航线”)。隐含狄利克雷分布(LDA)是实践中最成功的话题模型之一。阅读我们 之前的文章了解更多关于LDA的介绍。
一种新的在线变分学习算法
在线变分预测是一种训练LDA模型的技术,它以小批次增量式地处理数据。由于每次处理一小批数据,我们可以轻易地将其扩展应用到大数据集上。MLlib按照 Hoffman论文里最初提出的算法实现了一种在线变分学习算法。
性能对比
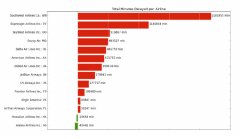
上表所示的话题是用新开发的在线变分学习算法训练得到。如果我们对比时间开销,可以发现新算法相比原来的EM算法效率有显著提升:

图1:在线学习算法比之前的EM算法速度更快
实验细节
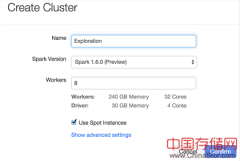
我们首先对数据预处理,滤去常见的英语停用词,并且将词表限制在10000个常用单词之内。然后用在线LDA优化器迭代100次训练得到100个LDA话题模型。我们的实验在 Databricks上进行,训练用到了16个节点的AWS r3.2x大集群,数据存放在S3。具体代码详见 github。
改进的预测、评估和查询
预测新文档的话题
除了描述训练文档集的话题之外,Spark 1.5支持让用户预测新测试文档所属的话题,使得已训练的LDA模型更有用。
用似然率和复杂度评估模型
在训练完一个LDA模型之后,我们通常关心模型在数据集上的表现如何。我们增加了两种方式来评估效果: 似然率和 复杂度。
支持更多的查询方式
新的版本添加了一些新的查询方式,用户可以用在已训练的LDA模型上。例如,现在我们不仅能获得每篇文档的top k个话题(“这篇文档讨论了什么话题?”),也能得到每个话题下排名靠前的文档(“若要学习X话题,我该阅读哪些文档?”)。
运行LDA的小技巧
- 确保迭代次数足够多。前期的迭代返回一些无用的(极其相似的)话题,但是继续迭代多次后结果明显改善。我们注意到这对EM算法尤其有效。
- 对于数据中特殊停用词的处理方法,通常的做法是运行一遍LDA,观察各个话题,挑出各个话题中的停用词,把他们滤除,再运行一遍LDA。
- 确定话题的个数是一门艺术。有些算法可以自动选择话题个数,但是领域知识对得到好的结果至关重要。
- 特征变换类的Pipeline API对于LDA的文字预处理工作极其有用;重点查看Tokenizer,StopwordsRemover和CountVectorizer接口。
下一步是什么?
Spark贡献者正在积极地优化我们的LDA实现方式。正在进行的工作有: 吉布斯采样(一种更慢但是有时更准确的算法), 流式LDA算法和 分层狄利克雷处理(自动选择话题个数)。
感谢
LDA的开发得益于众多Spark贡献者的通力合作。
Feynman Liang、Yuhao Yang、Joseph KBradley等人完成了最近这次优化, 其它众多朋友对早期版本亦有贡献。
原文链接: Large Scale Topic Modeling: Improvements to LDA on Spark(译者/赵屹华 审校/朱正贵 责编/仲浩)
译者简介:赵屹华,搜狗算法工程师,关注大数据和机器学习。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。