ApacheSpark1.5版本发布了,这篇文章概述了Spark1.5中的几个主要开发主题与一些令人期待的新功能特性。Spark1.5的大部分重大改动位于底层,更好地提升Spark的性能、可用性以及操作稳定性。
本届Spark Summit Europe将于今年十月在阿姆斯特丹举行。查看完整议程与购票操作。
今天我们很高兴地宣布Apache Spark1.5版本发布。我们在本文中将概述Spark 1.5中的几个主要开发主题与一些令人期待的新功能特性。在接下来的几周内,我们的博客也将会更详细介绍Spark 1.5中的特定组件。当然你也可以在接下来要介绍的Apache版本说明中,简要了解Spark 1.5的新特性列表。
Spark 1.5的大部分重大改动位于底层,从而更好地提升Spark的性能、可用性以及操作稳定性。Tungsten项目是Spark 1.5中涉及的主要部分,其优化了若干低层次的架构,进而提升Spark的整体性能。同样,这个版本也增加了流组件的相关特性,例如我们增加了大家期待的backpressure机制。此次发布中还有一大主题便是数据科学:Spark 1.5中囊括了大量新的机器学习算法与工具,并且扩展了Spark中关于R语言的API。
在Spark 1.5中还有个有趣的花絮就是我们跳过了标记为10000的这个JIRA号(即超过10000次请求功能或者报告错误的提交)。希望这不会过多减缓我们的开发进度。
性能提升与Tungsten项目
今年早期我们宣布的Tungsten项目-该项目是自Spark诞生以来内核级别最大的改动,旨在提高其性能与健壮性。目前在Spark 1.5中已经完成Tungsten项目的第一个主要部分。这部分主要包括的是二值化处理(binary processing),运用自定义的二进制内存布局来规避JVM对象模型。二值化处理显著降低了数据密集型工作负载时垃圾回收的开销。它还包括一个新的代码生成(code generation)框架,在该框架内用户代码运行时会产生用于求值表达式的优化字节指令。Spark 1.5中还为常见任务(例如日期处理、字符串处理等)增加了大量的内置函数。
未来几周,我们还将持续进行Tungsten项目的开发。作为展示,下图罗列了配置相同情况下分别在Spark 1.4与Spark 1.5运行不同规模聚合查询时的耗时对比。

该版本也还包括其他性能方面的增强。对Apache Parquet文件格式方面的支持,通过默认开启谓词下推(predicate push)以及更快地元数据查询路径,进而加强了其输入/输出的性能。对于Spark中的join操作同样进行了修改,带来了一种新的broadcast outer join操作,该操作可以对外连接进行排序合并。
可用性和互操作性
Spark 1.5还侧重于实用性方面,例如提供了与多种环境互操作的特性。毕竟,当连接你的数据源或者使用你的cluster时,你只能使用Spark系统。。所以当你调试Spark程序时候,程序的易读性是十分必要的。
Spark 1.5在web UI中增加了关于SQL与DataFrame的可视化查询计划,从而可以动态更新相关指标,例如关于filer操作的分离度、连接与聚合操作时内存使用情况等。下面是一个关于Web UI中计划可视化的一个实例(点击图片查看详情)。
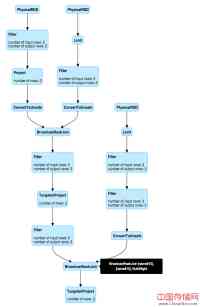
此外,我们已经投入大量的工作去提高Spark与其他生态系统项目的互操作性。例如,通过使用类加载隔离技术,Spark(SQL和DataFrame)的单个实例现在可以连接到Hive 0.12到Hive 1.2.1等多种版本的Hive 库表。除了能够连接到不同的库表之外,Spark现在还能读取其他系统生成的多种Parquet衍生文件,其中包括parquet-avro、parquet-thrift、parquet-protobuf、Impala、Hive。Spark是全球截至目前我们所知道的唯一一个能连接到各种版本Hive且能够支持多种Parquet格式的系统。
Spark Streaming相关操作工具
在此版本中关于Spark Streaming也添加了一系列新功能,其重点在于为需要长时间运行的流工作提供业务稳定性。正是因为流处理用户的热情反馈,我们才能更好地去新增以及完善这些功能。在Spark 1.5中增加了backpressure机制,所谓的backpressure机制即为当系统处于不稳定状态时、系统会通过节流方式来控制接受数据。例如,当出现输入源数据量呈爆炸性增长时或者在输出时遇到临时延迟的情况下,系统将动态地调整并确保该流程序保持稳定。此功能是由Databricks与Typesafe的工程师们共同开发而成的。
此外,新版本中增加了集群的负载均衡与调度数据接收器的能力,并且能够在长期运行的作业中更好地控制重新启动接收器。在此版本中Spark Streaming还增加了几个Python API,其中包括了Amazon Kinesis、Apache Flume以及MQTT 协议。
数据科学API之扩展
在2015年,Spark研究的主要致力于加强大规模数据科学研究。其中主要包括这三大方面:DataFrame、机器学习流水线、R语言支持。这三个部分所新增的API均有效的运行在Spark环境中。在Spark 1.5中,我们已经极大地扩展了这三个方面的能力。
自DataFrame在Spark 1.3中被首次发布之后,我们收到最常见的用户请求之一便是希望DataFrame能支持快速调用更多的字符串和日期/时间函数。于此我们很高兴地宣布,Spark 1.5中引入了超过100个内置函数,这些函数能够使得用户在Spark上的操作更为便利。几乎所有的内置函数均实现了代码生成,因此在Tungsten项目中可以通过使用这些函数更方便地做改动。
在Spark 1.4版本中R语言的支持是作为alpha组件进行介绍的。如今在Spark 1.5中我们提高了R语言的可用性,通过与MLlib的集成进而完成对可扩展机器学习的支持。SparkR前端支持公式定义广义线性模型、伯努利/高斯分布、弹性网络正则化。
对于机器学习,Spark 1.5在运用了新管道模型和运算法则的情况下。为新API管道提供个更好的覆盖。新管道的特征包括包括 CountVectorizer功能变压器、DCT、MinMaxScaler、 NGram、PCA、RFormula、StopWordsRemover、VectorSlicer,运算法则包括多层感知机、加强后的决策树模型、k-means聚类、朴素贝叶斯,优化工具包括训练集-验证集分割、多类分类评估。此外还新增了包括频繁项挖掘算法PrefixSpan、关联规则生成、Kolmogorov-Smirnov检验等。
Spark Package生态系统的发展
Spark 1.5的发布很好地说明了Spark Package生态系统的发展。如今,Spark提供了超过100个package,我们只需通过简单的标记便可启动Spark程序。这些package囊括了机器学习算法、数据源集成、测试工具等。许多package随着Spark 1.5的发布也进行了更新,其中就有spark-csv、 spark-redshift 与 spark-avro这些数据源连接器。
Spark 1.5.0是超过230个开发者努力完成的成果。诚挚感谢每一位开发者的帮助!想要了解更多关于Spark 1.5的特性与即将发布的功能,敬请关注Databricks博客。
为了您阅读的方便,我们将在下文罗列关于Spark 1.5的全部发行说明。如果您想尝试这些新特性的话,那么您可以在我们Databricks网站中找到相关资源。请先注册一个账号进行免费试用
Apache Spark 1.5 发布说明
APIs:RDD、DataFrame和SQL
- 列名统一规范(详情请见下文行为改变章节)。
- SPARK-3947:新的用户自定义聚合函数(UDAF)接口。
- SPARK-8300:Dataframe对 broadcast joins的提示。
- SPARK-8668:expr函数增强,可实现将一个SQL表达式转化为DataFrame列。
- SPARK-9076:对NaN值处理的特性增强
- NaN函数:isnan、nanvl;
- Dropna/fillna对非空NaN值的操作;
- 当NaN=NaN时,返回true;
- NaN大于其他任何值;
- 聚合操作中,NaN值均置于一个组中。
- SPARK-8828:当输入值都为null时,求和函数返回null。
- 数据类型
- SPARK-8943:CalendarlntervalType类型用于描述时间间隔;
- SPARK-7937:支持对StructType类型排序;
- SPARK-8866:对TimestampType类型精度减小到1微秒(us)。
- SPARK-8159:增加了100多个函数,其中包括日期/时间处理、字符串处理、数学运算。
- SPARK-8947:改进了在计划分析阶段中出现的类型强制与错误报告(即大多数错误报告的产生应该在分析阶段,而不是执行阶段)。
- SPARK-1855:支持基于内存和本地磁盘的检查点(checkpointing)机制。
后端执行:DataFrame和SQL
- 在基本上所有的DataFrame/SQL函数中默认启用代码生成。
- 在DataFrame/SQ中改进了聚合操作。
- 内存中高速缓存的哈希表布局。
- 当内存耗尽时,回退到基于外部排序聚合。
- 聚合情况下默认启用代码生成。
- 在DataFrame/SQL中改进了连接(join)操作
- Shuffle操作中优先采用(外部)排序合并连接而不是哈希连接,即连接的数据大小是以磁盘为边界而不是内存;
- 为left/right outer join操作提供(外部)排序合并连接的支持;
- 支持broadcast outer join操作。
- 在DataFrame/SQL中改进了排序(sort)操作
- 为排序提供缓存友好内存布局;
- 当数据超出内存大小时,回退到外部排序;
- 支持快速比较的代码生成比较器。
- 本地内存管理及表示
- 使用紧凑的二进制内存数据表示,节省内存空间,进而降低内存的使用情况;
- 管理内存不依赖于JVM GC(垃圾回收),避免GC所带来的性能损失,进而形成更为健壮的内存管理。
- SPARK-8638:优化窗口函数的性能以及内存使用。
- 度量工具、报告、可视化
- SPARK-8856:为Dataframe/SQL提供计划可视化;
- SPARK-8735:在web UI中显示运行时内存使用情况;
- SPARK-4598:在web UI中为有大量任务的作业提供分页显示。
集成:数据源、Hive、Hadoop、Mesos和集群管理
- Mesos
- SPARK-6284:支持框架身份验证与Mesos角色;
- SPARK-6287:在Mesos粗粒度模式中支持动态资源分配;
- SPARK-6707:用户可指定约束Mesos Slave的属性。
- YARN
SPARK-4352:在YARN模式中根据preferred locations(首选位置)进行动态资源分配。
- Standalone模式
SPARK-4751:支持动态资源分配。
- SPARK-6906:加强了Hive与库表(metastore)的支持
- SPARK-8131:加强了Hive数据库的支持;
- 更新支持到Hive 1.2版本;
- 支持连接到Hive 0.13、0.14、1.0/0.14.1、 1.1、、1.2的库表;
- 支持库表分区修剪默认配置为关闭,可通过设置spark.sql.hive.metastorePartitionPruning的值来进行配置;
- 支持Hive库表可兼容格式的数据持久化。
- SPARK-9381:支持JSON数据源的数据分区操作。
- SPARK-5463:Parquet的加强
- Parquet版本升级到了1.7;
- 更快的metadata discovery与schema merging;
- 默认开启谓词下推;
- SPARK-6774:支持读取由其他库或者系统生成的非标准化且合法的parquet文件;
- SPARK-4176:支持写入精度超过18有效位的十进制值。
- ORC文件优化,相关bug的修复。
- SPARK-8890:更快更健壮的动态分区插入操作。
- SPARK-9486:DataSourceRegister接口为外部数据源时指定短名称。
R语言
- SPARK-6797:支持在YARN集群中运行R语言。
- SPARK-6805:支持R语言模型公式对广义线性模型、伯努利/高斯分布、弹性网络正则化的扩展。
- SPARK-8742:优化了R语言错误消息提示。
- SPARK-9315:为DataFrame的函数提供了一些R风格的别名。
- SPARK-8521:新的特征转换器,其中包括CountVectorizer、Discrete Cosine transformation、MinMaxScaler、NGram、PCA、RFormula、StopWordsRemover、VectorSlicer。
- 新的统计方法Pipeline API:SPARK-8600 朴素贝叶斯、SPARK-7879 k-means聚类、SPARK-8671 isotonic回归。
- 新的算法:SPARK-9471多层感知机、SPARK-6487频繁项挖掘算法PrefixSpan、SPARK-8559 关联规则生成、SPARK-8598Kolmogorov-Smirnov检验等。
- 改进现有算法
- LDA:在线LDA算法性能、非对称文本聚类、复杂度、对数似然估计、文档中热门主题的筛选、保存/加载等;
- 决策树和集成:分类概率、随机森林的特征重要性、分类阈值、梯度提升树的检查点机制等;
- Pregel-API:GraphX中更有效的Pregel API实现方法;
- GMM:分布式矩阵求逆计算。
- 关于线性回归与逻辑思蒂回归(logistic regression)的模型总结。
- Python API:分布式矩阵、关于流的 k-means算法与线性模型、LDA、power iteration clustering等。
- 优化工具:训练集-验证集分割、多类分类评估。
- 文档:完善已发布版本中公开的API方法文档。
Spark Streaming
- SPARK-7398:提供Backpressure机制,即为当输入源数据流呈现爆炸性增长时,Spark Streaming会自动且动态地控制输入流。这需要流管道能够动态地适应摄入率与计算负载的变化。与此同时在接收器中也直接采用Kafka方法。
- 关于流数据源的相关Python API
- SPARK-8389: Kafka Python API;
- SPARK-8564: Kinesis Python API;
- SPARK-8378: Flume Python API;
- SPARK-5155: MQTT Python API。
- SPARK-3258:关于流处理中机器学习算法Python API、其中包括K-Means聚类、线性回归、逻辑思蒂回归。
- SPARK-9215:提升了Kinesis数据流的可靠性。当driver报错时,不需要通过启用重写之前的日志的方式来恢复接收数据。
- Direct Kafka API:正式引进。
- SPARK-8701:元数据输入界面-Kafka偏移量与输入文件均能在批处理细节界面上可见。
- SPARK-8882:接收器能跨集群且更好地实现负载均衡与调度。
- SPARK-4072:web UI上显示流数据储存情况。
不支持项、删除项、配置、行为改变
Spark Core
- DAGScheduler 的本地任务执行模式已被移出。
- driver和excutor的内存默认从512m提高到1g。
- JVM中MaxPermSize的默认设置从128m增加为256m。
- spark-shell默认日志记录级别从INFO改为WARN。
- 基于NIO的ConnectionManager已被弃用,并且将在1.6版本中正式删除。
Spark SQL & DataFrames
- 采用人工管理内存(Tungsten)的优化执行现已设为默认启用。关于代码生成的表达式求值也设置为默认启用。这些功能都可以通过设置 spark.sql.tungsten.enabled的值为false来表示禁用。
- Parquet合并模式在默认情况下不再启用。我们可以通过设置spark.sql.parquet.mergeSchema的值为true进而重新启用。
- 关于字符串列在Python的解决方法,现已支持使用点(.)限定列或者访问嵌套的值。例如df[‘table.column.nestedField’]。因此,这也意味着如果列名包含任何点的话,你必须使用对其反引号,(例如:table.`column.with.dots`.nested)。
- 在内存中的列储存分区修剪是默认的。它可以通过设置spark.sql.inMemoryColumnarStorage.partitionPruning的值为false来禁用。
- 精度无限小的数列将不再被支持,取而代之的是Spark SQL限定最大精度为38有效位。
- 时间戳的处理精度设为1us,而不是100ns。
- 当所有输入值为空时,求和函数返回null。
- 在SQL dialect,浮点数解析为十进制。HiveQL解析保持不变。
- 对SQL/DataFrame函数的命名规范为小写字母(例如使用sum,而不使用SUM)。
- 在speculation处于激活状态时使用直接输出执行器已经确定是不安全的,因此这种输出执行器在speculation被启用时是不会被parquet所使用的,这是不依赖于配置的。
- JSON数据源不会自动加载其他应用程序创建的新文件(即文件不会通过SPARK SQL操作插入到数据集)。对于一个JSON持久表(即表的元数据储存在Hive Metastore上)而言,用户可以使用REFRESH TABLE的SQL指令或者HiveContext中refreshTable方法将这些新文件置于表中。DataFrame代表一个JSON数据集,用户需要重新创建DataFrame,这样新的DataFrame才能置于新文件中。
Spark Streaming
- 新实验中的backpressure机制特征可以通过配置spark.streaming.backpressure.enabled 的值为true来启用。
- 不必为Kinesis流提供Write Ahead Log。更新的Kinesis接收器会动态跟踪每批接收到的Kinesis序列号,当从故障中恢复时,通过使用这些序列号重新读取必要信息。
- 接收器从失败中重启的次数不受到 Spark任务尝试最高限的限制。系统将总是尝试重启接收器,除非StreamingContext停止工作。
- 改善负载均衡。
- 在使用queueStream出现异常时,允许queueStream进行检查点操作。目前,仍然存在一些不足,所以我们将在Spark 1.5.1中进行修改。
MLlib
在spark.mllib包中,并没有重大改动,但有些行为上的变动:
- SPARK-9005: RegressionMetrics.explainedVariance 返回平均回归和的平方。
- SPARK-8600: NaiveBayesModel.labels可以进行排序。
- SPARK-3382:梯度下降法有一个默认的收敛公差为1e-3、因此迭代会比版本1.4更快结束。
在目前处于实验阶段的spark.ml包中,有一个API的修改和一个行为的修改:
- SPARK-9268: 因为存在一个Scala编译错误,所以移除Params.setDefault中java的varargs支持。
- SPARK-10097: Evaluator.isLargerBetter用来指示排序度量。RMSE矩阵不再在1.4中出现。
存在问题
在版本1.5.0中还存在如下问题,我们将在1.5.1中进行修复。
SQL/DataFrame
- SPARK-10301:用不同schema读取parquet文件嵌套结构时会返回错误提示。
- SPARK-10466:当进行sort-based shuffle时数据溢出会产生AssertionError。
- SPARK-10441:时间戳数据类型无法被写为JSON格式。
- SPARK-10495:日期值保存为JSON格式时是以(1970-01-01 00:00:00 UTC )形式的字符串进行储存的,而不是”yyyy-mm-dd”格式。
- SPARK-10403:Tungsten模式不与 tungsten-sort shuffle manager(默认为off状态)同时工作。
- SPARK-10422:字典编码成的字符串类型内存缓存已经损坏。
- SPARK-10434:Spark 1.5中写入带有空数据元素的Parquet文件无法被早期版本的Spark所识别。
Streaming
- SPARK-10224:当StreamingContext正常停止时很小可能出现数据丢失。
鸣谢
我们非常感谢以下公司为测试候选版本所做的工作,他们分别是:
Tencent、 Mesosphere、 Typesafe、 Palantir、 Cloudera、 Hortonworks、 Huawei、
Shopify、 Netflix、 Intel、 Yahoo、 Kixer、 UC Berkeley 与Databricks。
最后还要感谢以下这些人员的贡献,没有他们的努力,也就没有这次新版本的发布,他们分别是:
Aaron Davidson、 Adam Roberts、 Ai He、 Akshat Aranya、 Alex Shkurenko、 Alex Slusarenko 、Alexander Ulanov、 Zoltan Zvara等以及一些不知名的贡献者(欢迎您们将你们在git中的姓名邮件给我们,我们将会让更多人知道你们为新版本所做的努力)。
你可以在这个网址下载该版本:http://spark.apache.org/downloads.html
相关阅读:Apache Spark 1.5新特性介绍
原文链接:Announcing Spark 1.5(译者/丘志鹏 审校/王苇棋、朱正贵、李子健 责编/周建丁)
译者简介:邱志鹏,关注大数据、机器学习。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。