Name Node/Second Name Node 规格(共两台服务器):
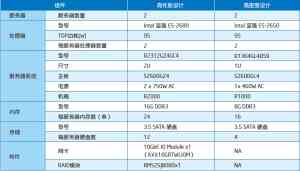
DataNode/TaskTracker 规格:
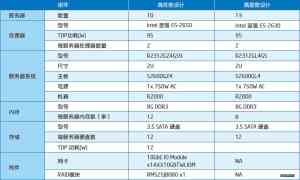
机柜规格:

Hadoop 性能初步测试
基于上述所建立的Hadoop集群,使用标准测试组件进行方案验证,并使用Hadoop性能标杆套件HiBench进行性能测试。
nnbench
测试目的:对NameNode的硬件及配置进行负载测试。
参数设置:
maps = 12
reduces = 6
测试命令
在hadoop安装目录(一般为/usr/lib/hadoop/)下输入:
[root@hadoop3 hadoop]# hadoop jar hadoop-test-1.0.3-Intel.jar nnbench -operation create_write -maps 12 -reduces 6 -blockSize 1 -bytesToWrite 0 numberOfFiles 1000 -r eplicationFactorPerFile 3 -readFileAfterOpen true
测试通过准则:
在命令执行过程中没有报错。
Sort
测试目的:测试整个MapReduce系统的性能。
参数设置:
测试命令:
第一步在一个目录中生成随机数据:
hadoop jar hadoop-examples-1.0.3-Intel.jar randomwriter random-data
第二步调用排序程序:
hadoop jar hadoop-examples-1.0.3-Intel.jar sort random-data sorted-data
第三步检查第二步输出的结果已被正常排序:
hadoop jar hadoop-test-1.0.3-Intel.jar testmapredsort -sortInput random-data -sortOutput sorted-data
测试通过准则:
在第三步执行完后输出:
SUCCESS! Validated the MapReduce framework's 'sort' successfully.
TestDFSIO
测试目的:测试HDFS的I/O性能。系统使用MapReduce同时读写文件。
参数设置:
nrFiles: 10
fileSize: 1000
测试命令:
hadoop jar hadoop-test-1.0.3-Intel.jar TestDFSIO -write -nrFiles 10 -fileSiz e 1000
测试结束后会输出以下结果:
----- TestDFSIO----- : write
Da te & time: Thu Ma y 09 03:01:56 CST 2013
Number o f files: 10
Total MBytes processed: 10000
Thr oughput mb/sec: 92.87206872533086
Average IO rate mb/sec: 98.6314926147461
IO rate std deviation: 23.668972646690577
Test exec time sec: 47.991
XSKY开发了基于对象存储XEOS的专用Hadoop HDFS高性能客户端XSKY HDFS Client。
原先支持Hadoop的四大商业机构纷纷宣布支持Spark,包含知名Hadoop解决方案供应商Cloudera和知名的Hadoop供应商MapR。
证券交易数据属于典型的结构化数据,采用Sql on Hadoop[1]技术,既可用廉价PC服务器获得良好的容量线性扩展能力,又可提供便于统计分析的SQL接口方便数据应用开发。
本文总结Hadoop十个认识误区,帮助大家更好地理解和学习Hadoop。由于Hadoop本身是由并行运算架构(MapReduce)与分布式文件系统(HDFS)所组成,所以我们也看到很多研究机构或教育单位,开始尝试把部分原本执行在HPC 或Grid上面的任务
数据产生后,意味着数据的采集工作已经完成,那么数据的输入与有效输出问题怎么破解?
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










