
如果你和别人谈论大数据,那么你们很快就会把话题转到那只黄色的大象身上——Hadoop(它的标志是一只黄色大象)。这个开源的软件平台是由Apache基金会发起的,它的价值在于能够简便且高效地处理超大型数据。
但是,究竟什么是 Hadoop呢?简单地说, Hadoop是一个能够对大量数据进行分布式处理的软件框架。首先,它将大量的数据集保存在分布式服务器集群中,之后它将在每个服务器集群里运行“分布式”数据分析应用。
那Hadoop又有什么特殊之处呢?首先,它很可靠,即使某一个或某一组服务器宕机,你的大数据应用程序仍能正常运转。其次,它十分高效,在处理过程中,不需要从整个网络来回调取大量数据。
对于Hadoop, Apache给出的官方描述是这样的:
Apache Hadoop 软件框架利用简便的编程模型来分布式处理超大数据。它的设计理念是从一个服务器扩展到成千上万的机器,每一个单独个体都提供本地运算和存储能力。与其他依靠硬件确保可靠性的同类软件平台不同,Hadoop在应用层自带bug检测和处理功能。因此,它仅仅通过一个计算机集群就可以提供实用性强的服务。
更神奇的是,Hadoop几乎是模块化的,这意味着你可以用任何其他的软件工具去替换它的每一个组成部分。因而,Hadoop 不光是可靠的、高效的,更具有灵活的组织结构。
Hadoop分布式文件系统(HDFS)
好吧,如果到现在为止你还都搞不懂什么是Hadoop(其实我觉得也有点抽象),那么,你只需要记住Hadoop最重要的两个组成部分就够了。一个是它的数据处理框架,另一个是它用于存储数据的分布式文件系统(distributed filesystem )。当然,Hadoop的内部组成相当复杂,不过,只要有了以上两个组成部分,它就能基本运行了。
这个分布式文件系统就是我们上面提到的那些分布的存储群集。说白了,它就是Hadoop 中“掌握”着实际数据的那一部分。虽然Hadoop 可以也使用其它文件系统进行数据存储,不过在缺省情况下,它还是会使用这个分布式文件系统(HDFS)来完成这个“任务”。
打个比方吧,HDFS就好像是一个大水桶,你的数据都可以放在它里面。直到你调用它们时,这些“可爱的小家伙们”都听话的待在这个安全的大水桶里。无论你是想在Hadoop 中进行分析,还是想从Hadoop 中调取数据、用别的工具进行处理,HDFS都能为你提供最流畅、最可靠的运行体验。
数据处理框架&MapReduce
(译者注:MapReduce是Google开发的C++编程工具,用于大规模数据集的并行运算)
数据处理框架,实际上是与数据协同运行的一个工具。在缺省情况下,它又被称MapReduce,是一个基于Java的系统。相比HDFS,你可能更熟悉MapReduce。造成种情况的原因,可能主要是一下两个原因:
1.它(MapReduce)是真正处理数据的工具
2.当人们用它数据处理时,感觉都都很爽
在所谓“正常”的关系型数据库中,数据的查找和分析,要借助于标准的“结构化查询语言”(SQL)。非关系型数据库也使用查询语言,可是不仅限于SQL。它可以借助于其它查询语言从数据存储中调取所需数据。因而,也有人把这种查询语言成为“非结构化查需语言”(NoSQL)。
事实上,Hadoop并不是一个数据库。虽然它可以帮助你存储数据,并任你随意调取,可它不涉及任何查询语言(既不用SQL 也不同其它语言)。由于它不仅仅是一个数据存储系统,因而Hadoop需要一个类似于MapReduce的系统,来帮它处理数据。
MapReduce要承担一系列的工作。实际上,每一个工作都是一个单独的Java应用,在进入数据库后,它可以根据需要调出不同的信息。用MapReduce代替传统的查询语言,可以令数据的查找更加精准、灵活。不过,在另一方面,这样做,也增加了数据处理的复杂性。
不过,也有一些工具可以简化这个过程。比如,Hadoop还包括一个名为Hive 的应用程序(也是由Apache领导开发的)。它可以将查询语言转化成一个个的MapReduce工作。过程看似是简化了,可这种批处理方式一次只能处理一个工作。这样一来,试用Hadoop更像是使用一个数据仓库,而不是一个数据分析工具。
分散在集群中
Hadoop的另外一个独特之处就在于,上述的所有功能都是分布式的系统,这和传统数据库里的中央式系统有很大差别。
在一个需要多台机器支撑的数据库中, “工作”往往是被分派好了的:所有的数据都存储在一个或多个机器里,而数据处理软件都由另一个或一群服务器掌控。
而在Hadoop的群组中,HDFS和 MapReduce系统存在于群组中的每一台机器中。这样做有两个好处:一、即使群组中的一台服务器宕机,整个系统仍然可以正常运行;二、它将数据存储和数据处理系统放在一起,可以提高数据检索的速度。
总之,正像我所说的那样,Hadoop绝对是可靠的、高效的。
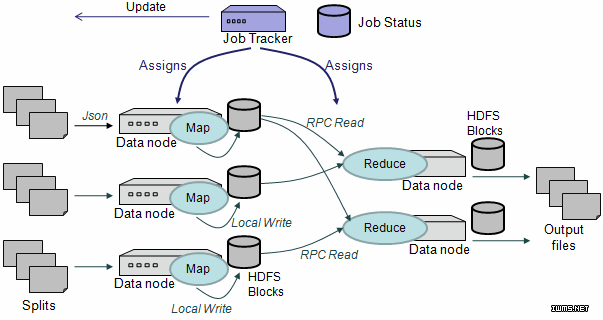
当 MapReduce收到一个信息查询指令,它就会立即启动两个“工具”来进行处理。一个是“工作追踪器”(JobTracker),位于Hadoop的主节点上;另一个是“任务追踪器”(TaskTrackers ),位于Hadoop的每一个网络节点上。
整个处理过程都是线性的:首先,通过运行Map函数,“工作追踪器”将运算工作分拆成有明确定义的模块,并将其传送到“任务追踪器”中(“任务追踪器”位于存有所需数据的群组机器里)。其次,通过运行Reduced函数,同之前定义相对应的精确数据以及从群组中的其它机器找到的所需数据,被传回到Hadoop群组的中央节点。
HDFS的分布方式和上面讲的方式十分相像。单一的主节点在群租服务器中追踪数据的位置。主节点也被称为数据节点,数据就存储在数据节点中的数据块上。HDFS对数据块进行复制,一般以128MB为一个复制单位,之后将这些复制数据分散到群组里的每一个节点中。
这种分布式“风格”使Hadoop 具有了另一大优势:由于它的数据和处理系统都被放在群组中的同一个服务器中,这样一来,当你的群组每增加一台机器时,你整个的系统硬件空间和运算能力就都提升了一个等级。

配备你的Hadoop
正如前面我提到的,甚至用户都没必要纠结于HDFS或是MapReduce。因为,Hadoop还提供了“弹性计算云解决方案”。这个方案主要是指亚马逊为其提供的简易云存储服务,以及DataStax公司的开源产品Brisk(基于Apache Cassandra的CassandraFS系统),它代替了HDFS,承担了Hadoop分布式文件系统工作。
为了避免MapReduce的“线性“处理方式的局限性,Hadoop还有一个名为Cascading的应用,它可以给开发者提供一个简便的工具,并且增加工作的灵活性。
客观地说,目前的Hadoop还不能算是一个完美的、极其简单的大数据处理工具。正如我提到的,由于MapReduce在处理数据上的局限性,很多开发者还是习惯于把它仅仅当成一个既简单又快捷的存储工具。这样一来,Hadoop处理数据的优势就无法体现。
不过,Hadoop又确实是最好的、用途最广泛的大数据处理平台。尤其是当你没有时间和金钱去使用关系型数据库存储庞大的数据时。因而,Hadoop总是在大数据的“屋子”里放上一头大象,随时等着进行数据处理。
Nutch集成slor的索引方法介绍? ?* 建立索引? ?* @param solrUrl solr的web地址? ?* @param crawlDb 爬取DB的存放路径:\crawl\crawldb
我们想了个办法:把海量数据分成小块,让一台机器处理一小块数据,所有的机器同时工作。最后把结 果汇总起来。这就是“并行计算”。hadoop中的MapReduce就是专门用来做分布式计算的并行处理框架。hadoop就是用来解决大数据的存储和计算的。
以Hadoop Tutorial为主体带大家走一遍如何使用Hadoop分析数据!MapReduce框架由一个Jobracker(通常简称JT)和数个TaskTracker(TT)组成(在cdh4中如果使用了Jobtracker HA特性,则会有2个Jobtracer,其中只有一个为active,另一个作为standby处于inactive状态)。JobTr
重谈下MapReduce框架中用户经常使用的一些接口或类的详细内容。了解这些会极大帮助你实现、配置和优化MR任务。当然javadoc中对每个class或接口都进行了更全面的陈述,这里只是一个指引教程。
hadoop常见问题解决:WARN mapred.LocalJobRunner: job_local910166057_0001o
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










