



MapReduce在大数据问题的处理上采用了与传统数据处理方式架构上几乎完全不同的解决方案,它通过将需要处理的任务并行运行在集群中的多个商用计算机节点上的方式完成。MapReduce在实现大数据处理上有着多个基础理论思想的支撑,虽然这些基础理论甚至实现方法都未必是MapReduce所创,但它们却由MapReduce采用独特的方式加以利用而重新大放光彩。
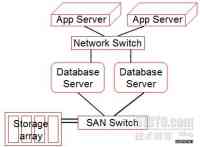
传统数据处理模型
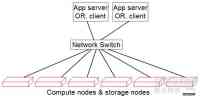
MapReduce数据处理模型
(1) 向外扩展(Scale out)而非向上扩展(Scale up):大数据的处理更适合采用大量低端商业服务器(scale out)而非少量高端服务器(scale up)。后者正是向上扩展的系统性能提升方式,它通常采用有着SMP架构的主机,然而有着大量的CPU插槽(成百上千个)及大量的共享内存(可以多达数百GB)的高端服务器非常昂贵,但其性能的增长却非线性上升的,因此性价比很一般。而大量的低端商业服务器价格低廉、易于更换和伸缩等特性有效避免了向上扩展的敝端。
(2)假设故障很常见(Assume failures are common):在数据仓库架构级别,故障是不可避免且非常普遍的。假设一款服务器出故障的平均概率为1000天1次,那么10000台这种服务器每天出错的可能性将达到10次。因此,大规模向外扩展的应用场景中,一个设计优良且具有容错能力的服务必须能有效克服非常普遍的硬件故障所带来的问题,即故障不能导致用户应用层面的不一致性或非确定性。MapReduce编程模型能通过一系列机制如任务自动重启等健壮地应付系统或硬件故障。
(3)将处理程序移向数据(Move processing to the data):传统高性能计算应用中,超级计算机一般有着处理节点(processing node)和存储节点(storage node)两种角色,它们通过高容量的设备完成互联。然而,大多数数据密集型的处理工作并不需要多么强大的处理能力,于是把计算与存储互相分开将使得网络成为系统性能瓶颈。为了克服计算如此类的问题,MapReduce在其架构中将计算和存储合并在了一起,并将数据处理工作直接放在数据存储的位置完成,只不过这需要分布式文件系统予以支撑。
(4)顺序处理数据并避免随机访问(Process data sequentially and avoid random access):大数据处理通常意味着海量的数量难以全部载入内存,因而必须存储在磁盘上。然而,机械式磁盘寻道操作的先天性缺陷使得随机数据访问成为非常昂贵的操作,因此避免随机数据访问并以顺序处理为目的完成数据组织成为亟待之需。固态磁盘虽然避免了机械磁盘的某此缺陷,然而其高昂的价格以及并没有消除的随机访问问题仍然无法带来性能上的飞跃发展。MapReduce则主要设计用来在海量数据集上完成批处理操作,即所有的计算被组织成较长的流式处理操作,以延迟换取较大的吞吐能力。
(5)隐藏系统级别的细节:程序开发中,专业程序员公认的难题之一就是得同步追踪短期记忆的各种细节,简单如变量名,复杂如算法等;这会生较大的记忆负荷因为其需要程序员在开发过程中高度集中注意力,因此,后来才出现了各种各样的开发环境(IDE)以帮助程序员在一定程度上解决诸如此类的问题。开发分布式程序的过程更为复杂,程序员必须协调管理多个线程、进程甚至是主机之间的各种细节,而这其中,令人最为头疼的问题是分布式程序以无法预知的次序运行,以及以无法预知的模式进行数据访问。这必然大大增加竞争条件、死锁及其它臭名照著的问题出现的可能性。传统上,解决此类问题的办法无外乎使用底层设备如互斥量,并在高层应用类似“生产者 -消费者”队列的设计模式等;但基于这种方式设计的分布式程序极难理解并且很难进行调试。MapReduce编程模型通过为其内部少量的几个组件提供了一个简单且精心定义的接口,从而将程序员与系统底层的处理细节隔离开来。MapReduce实现了“运算什么”与“如何在多个节点并行运算”的隔离,前者可以程序员控制,后者则完全由MapReduce编程框架或运行时环境控制。
(6)无缝扩展(Seamless scalability):数据密集型的处理应用中扩展算法(scalable algorithm)是其核心要件。一个理想的扩展算法应该满足两种特性:数据扩展一倍时其处理时长的增长幅度不会越过原处理所需时长的一倍;其次,集群规模扩大一倍时,其处理时长降低至少一倍。进一步地,理想的扩展算法还应该能够处理种种规模如PB级别的数据,以及良好地运行于各种规模如数千节点的集群中,而且其无论运行时何种规模的集群、处理何种规模的数据,其程序并不需要做出修改,甚至连配置参数也不需要改动。然而,现实是残酷地,这种理想算法并不存在,Fred Brook在其经典的“人月神话”中有一个断言:为落后于预定计划的项目增加程序员只会让项目的完成时间进一步延后。这是因为并不能通过简单地将复杂任务切分为多个小任务并将其分配出去并行完成来获得线性扩展,也即是“一个妇女可以在10个月生出孩子,但十个妇女并不能在一个月内生出孩子来”。然而,这个断言于今至少在某此领域已经被MapReduce打破——MapReduce最激动人心的特性之一就是其处理能力随着节点的增加而线性增长,即集群规模增长N倍其处理相同规模数据的时长也会缩短N倍。
参考文献:
http://en.wikipedia.org/wiki/Big_data
http://www.datameer.com/product/big-data.html
在mapreduce中设计了Speculator接口作为推断执行的统一规范,DefaultSpeculator作为一种服务在实现了Speculator的同时继承了AbstractService,DefaultSpeculator是mapreduce的默认实现。
Ubuntu 12.04单机版环境中搭建hadoop详细教程,在Ubuntu下创建hadoop用户组和用,创建hadoop用户。
据测试结果得知,在使用了206个EC2节点的情况下,Spark将排序用时缩短到了23分钟。这意味着在使用十分之一计算资源的情况下,相同数据的排序上,Spark比MapReduce快3倍!
这篇文章将介绍基于物品的协同过滤推荐算法案例在TDWSpark与MapReudce上的实现对比,相比于MapReduce,TDWSpark执行时间减少了66%,计算成本降低了40%。
过去两年,Hadoop社区对MapReduce做了很多改进,但关键的改进只停留在了代码层,Spark作为MapReduce的替代品,发展很快,其拥有来自25个国家超过一百个贡献者,社区非常活跃,未来可能取代MapReduce。
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国—东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










