近期学习HIVE,通过动手操作,收获不小,现将遇到的6个问题及解决方法分享给大家,希望对大家学习HIVE有帮助,如下:
1.hive作业提交问题hive如何放到一个脚本中并行执行
有3个sql文件,a,b,c,需要并行执行,现在的做法是开3个hive的cli,分别运行a,b,c,比如有个个test.sh脚本内容如下
hive -f a.sql
hive -f b.sql
hive -f c.sql
然后去运行,结果成了跑完abc三个顺序运。
解决的办法:
hive -f a.sql
hive -f b.sql &
hive -f c.sql &
2.Hive查询表 数据全是NULL
sample.txt格式如下:
1 duck
2 chiken
3 pig
4 elephant
5 fish
6 monkey
7 donkey
8 duck
9 chiken
10 pig
HQL语句如下:create table animal(id INT,name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE;
LOAD DATA LOCAL INPATH '/tmp/sanple.txt' overwrite into table animal;
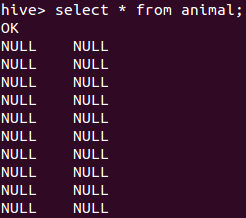
解决办法:
LOAD DATA LOCAL INPATH '/tmp/sanple.txt' overwrite into table animal FIELDS TERMINATED BY '\t';
解释:
数据分隔符的问题,定义表的时候需要定义数据分隔符,
FIELDS TERMINATED BY '\t'
这个字段就说明了数据分隔符是tab。
3.hive读取二进制文件
建了一个有45个double类型组成的表:
create table dht_tab(name1 DOUBLE ,name2 DOUBLE, ... ,name45 DOUBLE);
本地磁盘上有个名为“dhtnew.dh”的一个数据,可看为45*n个DOUBLE型的2进制字节的顺序文件组成。
将其导入的语句是:
load data local inpath 'dhtnew.dh' overwrite into table dht_tab;
但是后来查看的时候表是空的,貌似全部违反了schema。
解决办法:
两种解决方案
1、修改C Code,用文本输出,每个DOUBLE之间一个分隔符分割数据列
2、把原数据全部导入HDFS,然后写一个MAPREDUCE,重整这些数据到文本
4.hive 分隔符
解决办法:
1.确定一下ctrl+A没问题
2.row format delimited fields terminated by '\t'将分隔符修改成 tab
3.尝试hive默认的分隔符是‘\001’
5.hive 如何安全退出
解决办法:
1.hive> exit;
2.hive>quit;
3.更安全的办法:
exit;
hadoop job -kill jobid
---------------------------------------------------------------------------------------------------------------------------------------------------
6.HIVE和HBASE数据对接
在Hbase中有一张表TB_1
FNAME:"C1
随后,在Hive中创建了一张映射表TB_1
当HBASE的数据发生改变时,Hive可以读取到往HIVE里插入新数据后,HBASE里能看不到
解决办法:
HIVE的映射表无法更新HBASE中已存在的数据表
Hive是基于Hadoop的一个数据仓库工具,本质是将SQL转换为MapReduce程序,操作接口采用类SQL语法,提供快速开发的能力,Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
Apache Hive是一个构建于Hadoop(分布式系统基础架构)顶层的数据仓库,Apache HBase是运行于HDFS顶层的NoSQL(=Not Only SQL,泛指非关系型的数据库)数据库系统。区别于Hive,HBase具备随即读写功能,是一种面向列的数据库。
hive 是Hadoop中最常用的工具,可以说是必装工具,按apache官方文档,推荐使用svn下载后编译,推荐使用tar.gz包,直接安装,很简单搞定hadoop hive的安装。
配置hive+mysqlt的详细方法和步骤介绍,首先配置hive+mysqlt配置文件:Hive配置文件介绍•hive-site.xml hive的配置文件•hive-env.sh hive的运行环境文件•hive-default.xml.template 默认模板。
教你如何进行Hadoop + Hive + Map +reduce 集群安装部署:环境准备:CentOS 5.5 x64 (3台)10.129.8.52 (master) ======>> NameNode, SecondaryNameNode,JobTracker10.129.8.76。
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










