来自南加州大学和Facebook的7名作者共同完成了论文《 XORing Elephants: Novel Erasure Code for Big Data》。论文作者开发了Erasure Code家族的新成员——Locally Repairable Codes(即本地副本存储,以下简称LRC,它基于XOR。),明显减少修复数据时的I/O和网络流量。他们将这些编码应用在新的Hadoop组件中,并称之为 HDFS–Xorbas,并在Amazon AWS上和Facebook内部做了测试。
从Reed Solomon code到LRC
大约十年前,业界开始采用 Reed Solomon code对数据分发两份或三份,替代传统的RAID5或RAID6。由于采用了廉价的磁盘替代昂贵的存储阵列,所以这种方法非常经济。Reed Solomon code和XOR都是Erasure Code的分支。其中,XOR只允许丢失一块数据,而Reed Solomon code可以容忍丢失多块数据。
但标准的Reed Solomon code并不能很好的解决超大规模Hadoop负载。因为数据修复的时间和花费(主要为I/O和网络流量)成本较高。同时,在一段时间内,指数级增长的数据超出了互联网公司的基础设施能力。三副本有时候也不能满足更高的可靠性需求。
现在,这些互联网巨头设计的存储系统标准为:即便四个存储对象同时失效(这些对象包括磁盘、服务器、节点,甚至整个数据中心),也不能失去任何数据(目前Reed Solomon code是采用(10,4)策略,即10个数据块生成4个校验文件,可以容忍丢失4块数据。)。从这篇论文来看,Facebook采用Erasure Code方式后,相对于Reed Solomon code只需要60%的I/O和网络流量。
论文作者分析了Facebook的Hadoop集群中的3000个节点,涉及45PB数据。这些数据平均每天有22个节点失效,有些时候一天的失效节点超过100个,见图1。
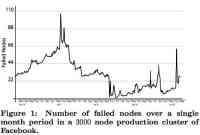
图1:日节点失效图
Hadoop集群的网络经常被被动占用,几个活跃的磁盘就可以占满1Gb带宽,修复失效数据产生的拥堵是不可能忽略不计的。一个理想的存储方案不仅要保证存储效率,还要减少修复数据所需的流量。
LRC测试结果的主要指标:
磁盘I/O和网络流量比Reed Solomon code减少一半; LRC比Reed Solomon code多占用14%的存储空间; 修复时间大幅缩短; 更强的可靠性; 对网络流量需求降低将实现适当的数据物理分布,甚至跨数据中心分布。

表1:LRC与Reed Solomon code、传统Hadoop三副本策略对比。LRC比Reed Solomon code的无故障运行时间提升两个数量级,修复流量减少一半。

图2:LRC与Reed Solomon code在多节点、多数据块失效的情况下,HDFS读取数据量、网络流量和修复时间的对比,LRC基本上比Reed Solomon code节省一半资源。
包括 HDFS-3544在内,业界正在不断追求高可靠下对网络带宽的节省方法,这对于互联网巨头和云计算基础架构服务商而言的意义不言而喻。由南加州大学、韦恩州立大学和微软共同参与的《 Simple Regenerating Codes》也在朝这个方向努力。值得注意的是,前文所说的LRC、HDFS-3544和《Simple Regenerating Codes》都是通过增加本地数据,来减少修复数据需要的网络流量。
在 ATC2012上,微软Azure工程师Cheng Huang和他的同事分享了《 Erasure Coding in Windows Azure Storage》。Cheng Huang表示,微软在Azure上也使用了LRC技术。 这里可以看到Cheng Huang此次分享视频。另外,Cheng Huang也参与了《Simple Regenerating Codes》。
在国内,Azure在世纪互联北京、上海的两个数据中心部署了服务。在接受CSDN采访时,微软云计算与服务器事业部总经理严治庆 透露:
Windwos Azure上的数据要存放6份,即使是虚机的本地存储也不例外。在中国,没有一家公有云计算的公司愿意去承诺三个9这样的 SLA,但微软会承诺3个9或更高。
关于HDFS–Xorbas、LRC和GFS2
目前,HDFS–Xorbas基于Facebook的HDFS-RAID版Hadoop( GitHub入口、 Apache入口)修改而来,并在 GitHub上托管代码。
HDFS–Xorbas项目由 Maheswaran Sathiamoorthy维护,他是一名南加州大学谢明电子工程部的候选教授。咨询公司TechnoQWAN创始人Robin Harris在 文章中表示:论文中的几名作者已经创立了公司。
论文作者之一的 Dhruba Borthakur是Facebook的Hadoop工程师,他在2009年的一篇 博客中对Erasure Code进行了介绍:
我知道使用Erasure Code的想法来自 DiskReduce,这是一帮来自卡内基梅隆大学的家伙搞出来的。于是我借用了这个想法,并在Apache Hadoop上增加了这一功能 HDFS-503。
Dhruba强调,HDFS Erasure Code只是在HDFS之上的代码,并没有对HDFS内部代码进行修改。这样做的原因是HDFS代码已经十分复杂,不想自找麻烦把它弄的更复杂。
Dhruba还在Hadoop Summit 2012中的一个关于HDFS的 研讨会上谈到了HDFS-RAID在Facebook内部运行的情况。数据工程师 梁堰波在 博客中分享了Dhruba的观点:
存放在HDFS上的数据分为热数据和冷数据两种。热数据一般是存放三备份,因为这些数据经常会被用到,所以多备份除了高效冗余外还能起到负载均衡的作用。对于冷数据,并非一定要在HDFS里面保存3个副本。Dhruba介绍了两种不同的RAID方案,对于不太冷的数据块A/B/C,通过XOR方式产生校验数据块,原来的数据块A/B/C各保留2个副本,校验数据块也有两个副本。这样,副本系数就从3减小到了2.6(理论值)。
对于很冷的数据,方案更加激进,由10个数据块通过Reed Solomon code生成4个校验文件,对于原来的数据块,只保留一个副本,校验数据块有2份副本。这样,副本系数就降到了1.2。
梁堰波在 博客分享了Dhruba介绍的分布式RAID文件系统实现原理,在2009年Dhruba的博客中也对此进行了介绍,可以分别查阅。
当然,Hadoop不过是GFS的开源实现,那么Google是如何解决数据修复带来的高成本呢?在Google GFS2(Colossus)中使用了Reed Solomon code来复制。在Google去年发表的《 Spanner: Google's Globally-Distributed Database》( CSDN摘译稿)中透露:
Reed Solomon code可以将原先的3副本减小到1.5副本,提高写入性能,降低延迟。
但是关于GFS2的信息,Google透露非常有限。Google首席工程师Andrew Fikes在Faculty Summit 2010会议上分享了《 Google的存储架构挑战》,他谈到了Google为什么使用Reed Solomon code,并列举了以下理由:
成本。特别是跨集群的数据拷贝。 提升平均无故障时间(MTTF)。 更灵活的成本控制和可用性选择。 参考资料: 王锐坚的博客 EMC中国研究院 颜开的博客 Highscalability StorageMojo
Hadoop故障排除:jps 报process information unavailable解决办法,jps时出现如下信息:4791 -- process information unavailable
解决方法could only be replicated to 0 nodes, instead of 1,1、停止hadoop脚本:bin/stop-all.sh(在进行2、3步前,注意数据的备份)2、删除主节点和从节点上的hadoop根目录下的临时文件夹,比如$HADOOP_HOME/hadooptmp。
hbase是什么? 首先hbase是一个在Hadoop的HDFS分布,hbase集群中的节点分为HMaster Server和HRegion Server两种,采用Master-Slave的模式,但是不像hadoop中的集群那样有单点故障的问题。
Hypertable on HDFS(hadoop) 安装,安装指南过程4.2.Hypertable on HDFS创建工作目录$ hadoop fs -mkdir /hypertable$ hadoop fs -chmod 777 。
hadoop dfs 常用命令行:* 文件操作* 查看目录文件* $ hadoop dfs -ls /user/cl** 创建文件目录* $ hadoop dfs -mkdir /user/cl/temp** 删除文件* $ hadoop dfs -rm /us
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










