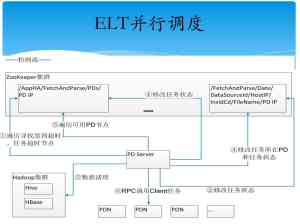
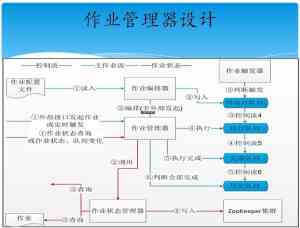
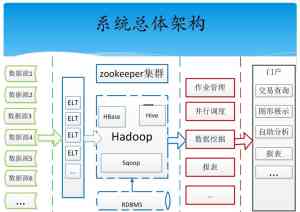
Nutch集成slor的索引方法介绍? ?* 建立索引? ?* @param solrUrl solr的web地址? ?* @param crawlDb 爬取DB的存放路径:\crawl\crawldb
我们想了个办法:把海量数据分成小块,让一台机器处理一小块数据,所有的机器同时工作。最后把结 果汇总起来。这就是“并行计算”。hadoop中的MapReduce就是专门用来做分布式计算的并行处理框架。hadoop就是用来解决大数据的存储和计算的。
以Hadoop Tutorial为主体带大家走一遍如何使用Hadoop分析数据!MapReduce框架由一个Jobracker(通常简称JT)和数个TaskTracker(TT)组成(在cdh4中如果使用了Jobtracker HA特性,则会有2个Jobtracer,其中只有一个为active,另一个作为standby处于inactive状态)。JobTr
重谈下MapReduce框架中用户经常使用的一些接口或类的详细内容。了解这些会极大帮助你实现、配置和优化MR任务。当然javadoc中对每个class或接口都进行了更全面的陈述,这里只是一个指引教程。
hadoop常见问题解决:WARN mapred.LocalJobRunner: job_local910166057_0001o
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










