因为项目的需要,学习使用了Hadoop,和所有过热的技术一样,“大数据”、“海量”这类词语在互联网上满天乱飞。Hadoop是一个非常优秀的分布式编程框架,设计精巧而且目前没有同级别同重量的替代品。另外也接触到一个内部使用的框架,对于Hadoop做了封装和定制,使得更满足业务需求。我最近也想写一些Hadoop的学习和使用心得,但是看到网上那么泛滥的文章,我觉得再写点笔记一样的东西实在是没有价值。倒不如在漫天颂歌的时候冷静下来看看,有哪些不适合Hadoop解决的难题呢?
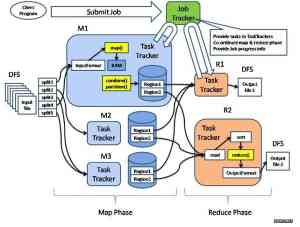
这张图就是Hadoop架构图,Map和Reduce是两个最基本的处理阶段,之前有输入数据格式定义和数据分片,之后有输出数据格式定义,二者中间还可以实现combine这个本地reduce操作和partition这个重定向mapper输出的策略行为。可以增加的定制和增强包括:
输入数据和输出数据的强化,例如通过数据集管理起来,可以统一、合并各式数据集,甚至也可以给数据增加过滤操作作为初筛,事实上业务上的核心数据源是种类繁多的;
数据分片策略的扩展,我们经常需要把具备某些业务共性的数据放到一起处理;
combine和partition的扩展,主要是有一些策略实现是在很多Hadoop的job中都是通用的;
监控工具的扩展,这方面我也见过别的公司内部定制的工具;
通讯协议和文件系统的增强,尤其是文件系统,最好能用起来像接近本地命令一样,这样的定制在互联网上也能找得到;
数据访问的编程接口的进一步封装,主要也是为了更切合业务,用着方便;
……
这些定制从某种程度上也反应了Hadoop在实际使用中略感局限或者设计时无暇顾及的地方,但是这些都是小问题,都是通过定制和扩展能够修复的。但是有一些问题,是Hadoop天生无法解决的,或者说,是不适合使用Hadoop来解决的问题。
1、最最重要一点,Hadoop能解决的问题必须是可以MapReduce的。这里有两个特别的含义,一个是问题必须可以拆分,有的问题看起来很大,但是拆分很困难;第二个是子问题必须独立——很多Hadoop的教材上面都举了一个斐波那契数列的例子,每一步数据的运算都不是独立的,都必须依赖于前一步、前二步的结果,换言之,无法把大问题划分成独立的小问题,这样的场景是根本没有办法使用Hadoop的。
2、数据结构不满足key-value这样的模式的。在Hadoop In Action中,作者把Hadoop和关系数据库做了比较,结构化数据查询是不适合用Hadoop来实现的(虽然像Hive这样的东西模拟了ANSI SQL的语法)。即便如此,性能开销不是一般关系数据库可以比拟的,而如果是复杂一点的组合条件的查询,还是不如SQL的威力强大。编写代码调用也是很花费时间的。
3、Hadoop不适合用来处理大批量的小文件。其实这是由namenode的局限性所决定的,如果文件过小,namenode存储的元信息相对来说就会占用过大比例的空间,内存还是磁盘开销都非常大。如果一次task的文件处理较大,那么虚拟机启动、初始化等等准备时间和任务完成后的清理时间,甚至shuffle等等框架消耗时间所占的比例就小得多;反之,处理的吞吐量就掉下来了。
4、Hadoop不适合用来处理需要及时响应的任务,高并发请求的任务。这也很容易理解,上面已经说了虚拟机开销、初始化准备时间等等,即使task里面什么都不做完整地跑一遍job也要花费几分钟时间。
5、Hadoop要处理真正的“大数据”,把scale up真正变成scale out,两台小破机器,或者几、十几GB这种数据量,用Hadoop就显得粗笨了。异步系统本身的直观性并不像那些同步系统来得好,这是显而易见的。所以基本上来说,维护成本不会低。
自动安装的Hadoop在/usr/local/Cellar/hadoop路径下。需要注意的是,在使用brew安装软件时,会自动检测安装包的依赖关系,并安装有依赖关系的包
数据不仅代表着生产力,还将成为重要的资产,或许在将来,我们留给下一代的资产,不是银行里有多少存款,而是信息资产;也许10年、15年之后,会有国家的数据银行,相对今天的财富资产,里面保存的是我们的信息资产。
Netflix已经把触角深入到大数据工作负载的领域。Netflix是一个“重量级”的Hadoop用户,在2012年6月份Gigaom的记者Derrick Harris就撰文阐述了Netflix如何收集用户的数据,进而使用一些方法来对这些数据进行分析.
YARN本质上是Hadoop的新操作系统,突破了MapReduce框架的性能瓶颈。Murthy认为Hadoop和YARN的组合是企业大数据平台致胜的关键。
想知道Hadoop在Aix下的安装是否会有什么不同,于是心血来潮的安装了一遍,过程记录如下:1.在Aix上安装解压缩软件,安装Java等,这里就不说了。2.下载Hadoop0.21.0版本,并解压至特定目录下,这里解压到 /home/cqq/hadoop-0.21.0。
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










