序列化
序列化(serialization)是指将结构化的对象转化为字节流,以便在网络上传输或者写入到硬盘进行永久存储;相对的反序列化(deserialization)是指将字节流转回到结构化对象的过程。
在分布式系统中进程将对象序列化为字节流,通过网络传输到另一进程,另一进程接收到字节流,通过反序列化转回到结构化对象,以达到进程间通信。在Hadoop中,Mapper,Combiner,Reducer等阶段之间的通信都需要使用序列化与反序列化技术。举例来说,Mapper产生的中间结果(<key: value1, value2...>)需要写入到本地硬盘,这是序列化过程(将结构化对象转化为字节流,并写入硬盘),而Reducer阶段读取Mapper的中间结果的过程则是一个反序列化过程(读取硬盘上存储的字节流文件,并转回为结构化对象),需要注意的是,能够在网络上传输的只能是字节流,Mapper的中间结果在不同主机间洗牌时,对象将经历序列化和反序列化两个过程。
序列化是Hadoop核心的一部分,在Hadoop中,位于org.apache.hadoop.io包中的Writable接口是Hadoop序列化格式的实现。
Writable接口
Hadoop Writable接口是基于DataInput和DataOutput实现的序列化协议,紧凑(高效使用存储空间),快速(读写数据、序列化与反序列化的开销小)。Hadoop中的键(key)和值(value)必须是实现了Writable接口的对象(键还必须实现WritableComparable,以便进行排序)。
以下是Hadoop(使用的是Hadoop 1.1.2)中Writable接口的声明:
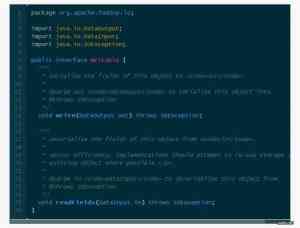
Writable类
Hadoop自身提供了多种具体的Writable类,包含了常见的Java基本类型(boolean、byte、short、int、float、long和double等)和集合类型(BytesWritable、ArrayWritable和MapWritable等)。这些类型都位于org.apache.hadoop.io包中。
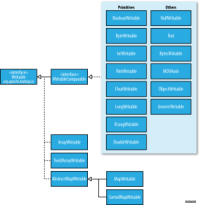
定制Writable类
虽然Hadoop内建了多种Writable类提供用户选择,Hadoop对Java基本类型的包装Writable类实现的RawComparable接口,使得这些对象不需要反序列化过程,便可以在字节流层面进行排序,从而大大缩短了比较的时间开销,但是当我们需要更加复杂的对象时,Hadoop的内建Writable类就不能满足我们的需求了(需要注意的是Hadoop提供的Writable集合类型并没有实现RawComparable接口,因此也不满足我们的需要),这时我们就需要定制自己的Writable类,特别将其作为键(key)的时候更应该如此,以求达到更高效的存储和快速的比较。
下面的实例展示了如何定制一个Writable类,一个定制的Writable类首先必须实现Writable或者WritableComparable接口,然后为定制的Writable类编写write(DataOutput out)和readFields(DataInput in)方法,来控制定制的Writable类如何转化为字节流(write方法)和如何从字节流转回为Writable对象。
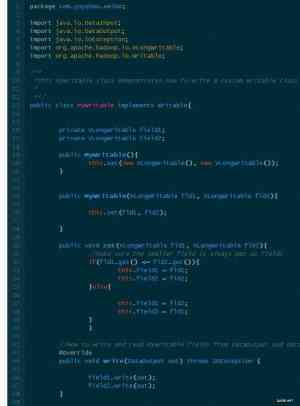
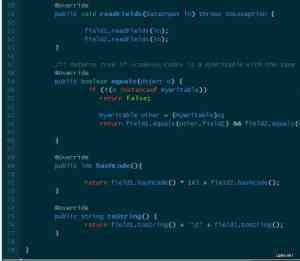
未完待续,下一篇中将介绍Writable对象序列化为字节流时占用的字节长度以及其字节序列的构成。
自动安装的Hadoop在/usr/local/Cellar/hadoop路径下。需要注意的是,在使用brew安装软件时,会自动检测安装包的依赖关系,并安装有依赖关系的包
数据不仅代表着生产力,还将成为重要的资产,或许在将来,我们留给下一代的资产,不是银行里有多少存款,而是信息资产;也许10年、15年之后,会有国家的数据银行,相对今天的财富资产,里面保存的是我们的信息资产。
Netflix已经把触角深入到大数据工作负载的领域。Netflix是一个“重量级”的Hadoop用户,在2012年6月份Gigaom的记者Derrick Harris就撰文阐述了Netflix如何收集用户的数据,进而使用一些方法来对这些数据进行分析.
YARN本质上是Hadoop的新操作系统,突破了MapReduce框架的性能瓶颈。Murthy认为Hadoop和YARN的组合是企业大数据平台致胜的关键。
想知道Hadoop在Aix下的安装是否会有什么不同,于是心血来潮的安装了一遍,过程记录如下:1.在Aix上安装解压缩软件,安装Java等,这里就不说了。2.下载Hadoop0.21.0版本,并解压至特定目录下,这里解压到 /home/cqq/hadoop-0.21.0。
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










