1.Windows 7 32 Bit OS(你懂的)
2.Apache Hadoop 2.2.0-bin(hadoop-2.2.0.tar.gz)
3.Apache Hadoop 2.2.0-src(hadoop-2.2.0-src.tar.gz)
3.JDK 1.7
4.Maven 3.2.1(apache-maven-3.2.1-bin.zip)
5.Protocol Buffers 2.5.0
6.Unix command-line tool Cygwin(Setup-x86.exe)
7.Microsoft Windows SDK v7.1
Apache Hadoop 2.X推荐运行环境是64Bit机器,因为实际运行过程中要超过4GB内存嘛!32Bit适合个人开发调试学习使用。
前言:由于Apache Hadoop 2.2.0发行版使用的动态链接库(bin\hadoop.dll、libwinutils.lib、winutils.exe)是Windows 64bit的,所以需要使用源代码重新编译成32bit的(有可能你下载回来的hadoop-2.2.0.tar.gz发行包里没有这些Windows动态库的)。如果你的系统盘是SSD的话,建议将安装在C盘根目录。
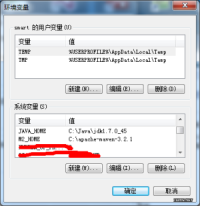
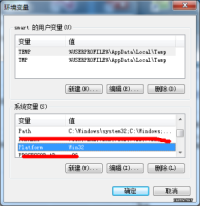
(工具软件:3,4,5,6,7)安装过程不再详述,一路Next就行(JavaSE推荐根目录:c:\java)。重点在环境变量的配置部分,增加以下环境变量到“系统变量”中(Java路径不能有空格):
JAVA_HOME=C:\Java\jdk1.7.0_45
Platform=Win32
M2_HOME=C:\apache-maven-3.2.1
Path=;C:\cygwin\bin;C:\apache-maven-3.2.1\bin;C:\protoc-2.5.0-win32;
配置示例(别忘了设置Path哦):
将hadoop-2.2.0-src.tar.gz源代码解压到D盘根目录,看上去路径如下:D:\hadoop-2.2.0\
Apache Hadoop svn 代码库地址:http://svn.apache.org/repos/asf/hadoop/common/tags/release-2.2.0
需要手工修正源代码的几处编译错误:
修改文件:\hadoop-common-project\hadoop-auth\pom.xml
修改内容:在大约56行的位置增加一个Xml配置节点。
<dependency>
<groupId>org.mortbay.jetty</groupId>
<artifactId>jetty-util</artifactId>
<scope>test</scope>
</dependency>
修改示例:
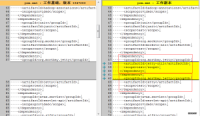
修改文件:hadoop-common-project\hadoop-common\src\main\native\native.sln
修改内容:用记事本打开文件。
替换内容:
GlobalSection(ProjectConfigurationPlatforms) = postSolution
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|Mixed Platforms.ActiveCfg = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|Mixed Platforms.Build.0 = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|Win32.ActiveCfg = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|Win32.Build.0 = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|x64.ActiveCfg = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|x64.Build.0 = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Release|Mixed Platforms.ActiveCfg = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Release|Mixed Platforms.Build.0 = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Release|Win32.ActiveCfg = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Release|Win32.Build.0 = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Release|x64.ActiveCfg = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Release|x64.Build.0 = Release|x64
EndGlobalSection
新内容:
GlobalSection(ProjectConfigurationPlatforms) = postSolution
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|Win32.ActiveCfg = Release|Win32
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|Win32.Build.0 = Release|Win32
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|x64.ActiveCfg = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|x64.Build.0 = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Release|Win32.ActiveCfg = Release|Win32
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Release|Win32.Build.0 = Release|Win32
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Release|x64.ActiveCfg = Release|x64
{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Release|x64.Build.0 = Release|x64
EndGlobalSection
修改示例:
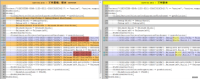
修改文件:hadoop-common-project\hadoop-common\src\main\native\native.vcxproj
修改内容:
查找替换”Release|x64“为”Release|Win32“
查找替换”<Platform>x64</Platform>“为”<Platform>Win32</Platform>“
修改示例:
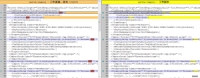
右键单击”D:\hadoop-2.2.0“文件夹,选择”管理员取得所有权“。否则编译过程中可能会发生”拒绝访问“错误(右键没有显示该菜单的,自行网上查找注册表修改方法)。
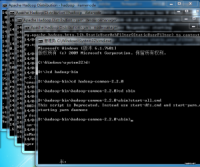
打开“开始”--“所有程序”--“Microsoft Windows SDK v7.1”--“Windows SDK 7.1 Command Prompt”,进入VC++的命令行工具(一定要从此处进入方可顺利编译Hadoop源代码,记着是以管理员身份运行)。命令如下:
切换至源代码根目录,执行编译命令:mvn package -Pdist,native-win -DskipTests -Dtar
示例运行结果
Setting SDK environment relative to C:\Program Files\Microsoft SDKs\Windows\v7.1
\.
Targeting Windows 7 x86 DebugC:\Windows\system32>d:
D:\>cd D:\hadoop-2.2.0
D:\hadoop-2.2.0>mvn package -Pdist,native-win -DskipTests -Dtar
................................2.2.1版本编译完成大约需要16分钟左右
................................2.4.0版本编译完成大约需要22分钟左右(觉得编译过程慢的话:自己动手配置镜像服务器)
Hadoop编译成功后,程序集输出在: hadoop-common-project\hadoop-common\target\hadoop-common-2.2.0目录下。
1.解压缩”hadoop-2.2.0.tar.gz“至D盘如下目录:D:\hadoop-common-2.2.0
2.合并替换发行版本的64动态链接库:主要是是以下几个文件(bin\hadoop.dll、bin\hadoop.exp、bin\hadoop.lib、bin\hadoop.pdb、bin\libwinutils.lib、bin\winutils.exe、bin\winutils.pdb),从编译成功后的输出目录Copy到Apache发行版形同目录下替换即可。
3.修改配置文件
core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop-bin/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop-bin/data/datanode</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
其他配置文件保持默认即可。
4.配置Hadoop Hdfs运行环境变量(重要)
HADOOP_HOME=D:\hadoop-common-2.2.0
Path=D:\hadoop-common-2.2.0\bin
5.格式化hdfs文件系统
以管理员身份打开命令行,并切换到:D:\hadoop-common-2.2.0\bin目录下,执行命令:
hadoop namenode -format
如果不出意外,hdfs文件系统将格式化成功,你会在D:\hadoop-bin\data看到已经生成了namenode文件夹。
6.启动Hadoop HDFS服务器
同样管理员身份命令行,切换到:D:\hadoop-common-2.2.0\sbin目录下,执行命令:
start-all.cmd
不出意外,用浏览器打开:http://localhost:8042 或者 http://localhost:50070 会有惊喜哦!记得别把本地的端口占用了。
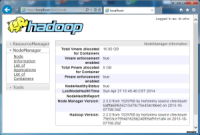
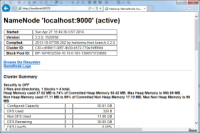
7.上传文件到HDFS
如果你对命令行熟悉的话,可以采用命令行的方式推送的HDFS。如果你的hdfs-site.xml配置文件时Copy我以上的示例的话,那么WEBHDFS默认是开启的,什么意思?就是通过Http RestFull风格API管理文件哦!另外还要记得把dfs.permissions设置为false,要不你没有权限上传文件的哦!
原文链接:http://www.cnblogs.com/smartbooks/p/3694760.html
Ubuntu 12.04单机版环境中搭建hadoop详细教程,在Ubuntu下创建hadoop用户组和用,创建hadoop用户。
在mac os上安装hadoop的文章不多,本文安装环境的操作系统是 MAC OS X 10.7 Lion,共分7步,注意第三个配置在OS X上最好进行配置,否则会报错“Unable to load realm info from SCDynamicStore”。
Nutch采用一个MR对爬取下来的文档进行清洗和封装成一个action列表。Nutch会将封装好的数据采用基于http的POST的方法发送一个请求数据包给solr的服务器,solr.commit();这个方法在前面一篇文章中解释有些偏差,solr的整个事务都是在solr服务器端的,这跟以前的的事务有所
、默认项目名称为MapReduceTools,然后在项目MapReduceTools中新建lib目录,先将hadoop下的hadoop-core-1.0.4.jar重命名为hadoop.core.jar,并把hadoop.core.jar、及其lib目录下的commons-cli-1.2.jar、commons-lang-2.4.jar、commons-configuration-1.6.jar、jackson-m
SAP特别设立了一个“大数据”合作伙伴理事会。该理事会致力于进行合作创新,研发基于SAP实时数据平台和Hadoop的新产品解决方案,探索新应用和架构
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。