前言
做大数据相关的后端开发工作一年多来,随着Hadoop社区的不断发展,也在不断尝试新的东西,本文着重来讲解下Ambari,这个新的Apache的项目,旨在让大家能够方便快速的配置和部署Hadoop生态圈相关的组件的环境,并提供维护和监控的功能.
作为新手,我讲讲我自己的学习经历,刚刚开始学习的时候,当然最简单的 Google 下Hadoop ,然后下载相关的包,在自己的虚拟机(CentOS 6.3) 上安装一个单机的Hadoop版本用来做测试,写几个测试类,然后做下CRUD测试之类的,跑跑Map/Reduce的测试,当然这个时候对于Hadoop还不是很了解,不断的看别人的文章,了解下整体的架构,自己所做的就是修改conf下的几个配置文件,让Hadoop能够正常的跑起来,这个时候几种在修改配置上,这个阶段之后,又用到了HBase,这个Hadoop生态圈的另外一个产品,当然还是修改配置,然后 start-all.sh , start-hbase.sh 把服务起起来,然后就是修改自己的程序,做测试,随着用Hbase 学了下 Zookeeper 和Hive等, 接着过了这个操作阶段了之后,开始研究Hadoop2.0,还有CSDN上很多大牛的文章了之后, 算是对Hadoop的生态圈整体有一些了解,介于自己在公司所承担的开发所涉及到相关的技术仅仅就这些.但是作为一个爱好探索的人,是否想多了解下呢,它的性能怎么样? 它是具体如何运作的? 看大公司的那些PPT,人家(淘宝等大公司)动不动就是几十个,几百个,乃至几千个节点,人家是如何管理的,性能是怎么样的?看着PPT里面的那些性能测试的曲线,你是否也能够详细的了解,并且对自己的项目进行性能调优呢? 我貌似找到答案了,那就是 Ambari , 由 HortonWorks 开发的一个Hadoop相关的项目,具体可以上官方去了解.
了解Hadoop生态圈
现在我们经常看到的一些关键字有: HDFS,MapReduce,HBase,Hive,ZooKeeper,Pig,Sqoop,Oozie,Ganglia,Nagios,CDH3,CDH4,Flume,Scribe,Fluented,HttpFS等等,其实应该还有更多,Hadoop生态圈现在发展算是相当繁荣了,而在这些繁荣的背后又是谁在推动的呢? 读过Hadoop历史的朋友可能知道,Hadoop最早是始于Yahoo,但是现在主要是由 HortonWorks 和 Cloudera 这2家公司在维护者,大部分的commiter 都属于这2家公司,所以现在市面上看到的主要有2个版本,CDH系列,和社区版, 我最早用的是社区版本,后来换到CDH3,现在又换回社区版,因为有Ambari.当然,用什么和不用什么,只要自己的技术到家,还是都能修改的跑的正常的.这里就不多说了. 讲了这么多废话了,开始讲 Ambari安装吧.
开始部署
首先了解下Ambari, 项目地址在:http://incubator.apache.org/ambari/
安装文档在: http://incubator.apache.org/ambari/1.2.2/installing-hadoop-using-ambari/content/index.html
安装的时候请大家先看下安装文档吧,安装文档必须认真看,结合自己当前所使用的系统版本,配置不同的源,而且安装过程中需要的时间相对比较长,所以需要认真的做好安装文档的每个步骤. 这里我就说我遇到的一些问题.(也可参考hadoop集群监控工具ambari安装)
以下说说我自己的安装过程.
机器准备:
我的测试环境采用 9 台 HP 的机器,分别是 cloud100 - cloud108 , cloud108做为管理节点.
Ambari安装的环境路径:
各台机器的安装目录:
/usr/lib/hadoop
/usr/lib/hbase
/usr/lib/zookeeper
/usr/lib/hcatalog
/usr/lib/hive
Log路径, 这里需要看出错信息都可以在目录下找到相关的日志
/var/log/hadoop
/var/log/hbase
配置文件的路径
/etc/hadoop
/etc/hbase
/etc/hive
HDFS的存储路径
/hadoop/hdfs
安装过程需要注意的点:
1, 安装的时候,需要做好每台机器的ssh免密码登陆,可以参考CentOS6.4之图解SSH无验证双向登陆配置,做好之后,从 管理节点到各个集群节点之间,都能使用这个登陆.
2, 如果你的机器之前安装过 Hadoop的相关服务,特别是Hbase 里面配置了 HBASE_HOME 的环境变量,需要 unset掉, 这个环境变量会影响,因为我之前把这些路径放到 /etc/profile 里面导致影响了HBase,因为Ambari安装的路径和你之前安装的可能不一样.
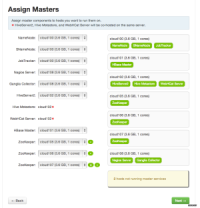
3,在服务选择页面的时候, NameNode 和 SNameNode 需要布置在一起, 我之前尝试做 HA 而把他们分开,但是SNameNode一直起不来,导致整个启动失败,接下来时间需要花在HA上.
3.png (161.09 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
4. JobTrakcer 不和Namenode在一起也会导致 启动不起来.
5. Datanode的节点 不能少于 Block replication 中数, 基本都是需要 >= 3.
4.png (89.18 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
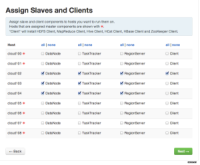
6. Confirm Hosts 的时候,需要注意里面的 Warning 信息,把相关的Warning都处理掉,有一些Warning会导致安装出错.
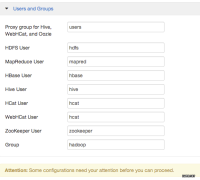
7. 记住安装中所新建的用户,接下来需要用到这些用户.
5.png (43.68 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
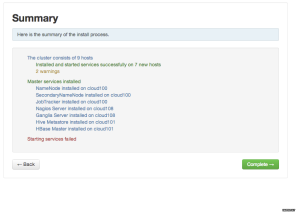
8. Hive和HBase Master 部署在同一个节点,这里当然你也可以分开. 设置好后就开始安装了.
6.png (59.13 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
9.如果安装失败的情况下,如何重新安装.
首先,先删除掉系统已经安装的文件相关的目录,
sh file_cp.sh cmd "rm -rf /usr/lib/hadoop && rm -rf /usr/lib/hbase && rm -rf /usr/lib/zookeeper"
sh file_cp.sh cmd "rm -rf /etc/hadoop && rm -rf /etc/hbase && rm -rf /hadoop && rm -rf /var/log/hadoop"
sh file_cp.sh cmd "rm -rf /etc/ganglia && rm -rf /etc/hcatalog && rm -rf /etc/hive && rm -rf /etc/nagios && rm -rf /etc/sqoop && rm -rf /var/log/hbase && rm -rf /var/log/nagios && rm -rf /var/log/hive && rm -rf /var/log/zookeeper && rm -rf /var/run/hadoop && rm -rf /var/run/hbase && rm -rf /var/run/zookeeper "
再在Yum remove 掉安装的相关的包.
sh file_cp.sh cmd "yum -y remove ambari-log4j hadoop hadoop-lzo hbase hive libconfuse nagios sqoop zookeeper"
我这里使用到了自己写的Shell,方便在多台机器之间执行命令:
https://github.com/xinqiyang/opshell/tree/master/hadoop
Reset下Ambari-Server
ambari-server stop
ambari-server reset
ambari-server start
10.注意时间的同步,时间问题会导致regionserver起不来
7.png (210.96 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
11. iptables 需要关闭,有的时候可能机器会重新启动,所以不单单需要 service stop 也需要chkconfig 关闭掉.
最后安装完成后,登陆地址查看下服务的情况:
http://管理节点ip:8080 , 比如我这里的: http://192.168.1.108:8080/ 登陆之后,需要设置之前在安装Ambari-server时候输入的账号和密码,进入
8.png (150.91 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
查看 ganglia的监控
9.png (168.44 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
查看 nagios 的监控
10.png (166.22 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
测试
安装完成后,看着这些都正常了,是否需要自己验证一下呢? 不过基本跑了冒烟测试后,正常的话,基本还是正常的,但是我们自己也得来操作下吧.
验证HDFS
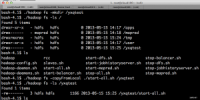
11.png (120.58 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
验证Map/Reduce
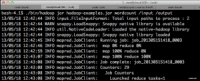
12.png (134.94 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
验证HBase
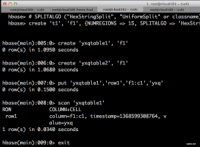
13.png (111.13 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
验证Hive
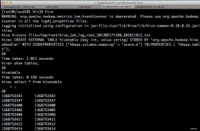
14.png (145.61 KB, 下载次数: 0)
下载附件 保存到相册
2014-4-25 23:12 上传
总结
到这里,相关的 hadoop 及 hbase 及hive 的相关配置就都配置完成了,接下来需要做一些压力测试.还有其他方面的测试, 对于Ambari带的是 HortonWorks 打包的rpm版本的 Hadoop相关的源码,所以这里可能会和其他的版本有一些不同,但是作为开发环境来说,暂时还是没有很多大的影响的,但是现在还没有在生产上使用, 所以也不管说如何的稳定,接下来我会在开发项目的过程中,将所遇到的Bug给列出来. 总体来说Ambari还是很值得使用的,毕竟能够减少很多不必要的配置时间,而且相对在单机环境下, 在集群环境下更能贴近生产做一些相关的性能测试和调优测试等等,而且配置的ganglia和nagios的监控也能够发布的让我们查看到集群相关的数据,总体来说还是推荐使用的,新东西有Bug是在所难免的,但是在用的过程中我们会不断的完善. 接下来如果有时间,会对Ambariserver的功能进行扩展,添加诸如redis/nginx之类的常用的高性能模块的监控选项. 这个有时间在弄了. 总之,欢迎使用Ambari.
原文链接:http://www.uml.org.cn/sjjm/201305244.asp
XSKY开发了基于对象存储XEOS的专用Hadoop HDFS高性能客户端XSKY HDFS Client。
原先支持Hadoop的四大商业机构纷纷宣布支持Spark,包含知名Hadoop解决方案供应商Cloudera和知名的Hadoop供应商MapR。
证券交易数据属于典型的结构化数据,采用Sql on Hadoop[1]技术,既可用廉价PC服务器获得良好的容量线性扩展能力,又可提供便于统计分析的SQL接口方便数据应用开发。
本文总结Hadoop十个认识误区,帮助大家更好地理解和学习Hadoop。由于Hadoop本身是由并行运算架构(MapReduce)与分布式文件系统(HDFS)所组成,所以我们也看到很多研究机构或教育单位,开始尝试把部分原本执行在HPC 或Grid上面的任务
数据产生后,意味着数据的采集工作已经完成,那么数据的输入与有效输出问题怎么破解?
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










