Hadoop是基于Java开发的,所以要开发Hadoop相应的程序就得用JAVA。在linux下开发JAVA还数eclipse方便。
进入官网:http://eclipse.org/downloads/。
找到相应的版本进行下载,我这里用的是eclipse-SDK-3.7.1-linux-gtk版本。
2、解压
下载下来一般是tar.gz文件,运行:
$tar -zxvf eclipse-SDK-3.7.1-linux-gtk.tar.gz -c ~/Tool
这里Tool是需要解压的目录。
解完后,在tool下,就可以看到eclipse文件夹。
运行:
$~/Tool/eclipse/eclipse
每次运行时,输入命令行比较麻烦,最好能创建在左侧快捷菜单上。
$sudo gedit /usr/share/applications/eclipse.desktop
1)启动文本编译器,并创建文件,添加以下内容:
[Desktop Entry] Version=1.0 Encoding=UTF-8 Name=Eclipse3.7.1 Exec=eclipse TryExec=eclipse Comment=Eclipse3.7.1,EclipseSDK Exec=/usr/zjf/Tool/eclipse/eclipse Icon=/usr/ zjf/Tool/eclipse/icon.xpm Terminal=false Type=Application Categories=Application;Development; [注意上面的路径]
2)创建启动器
sudo gedit /usr/bin/eclipse 添加如下内容 #!/bin/sh export MOZILLA_FIVE_HOME="/usr/lib/mozilla/" export ECLIPSE_HOME="/usr/local/eclipse" $ECLIPSE_HOME/eclipse $*
3)添加可执行权限
sudo chmod +x /usr/bin/eclipse
4)在开始菜单中输入eclipse:
就会看到软件图标,然后将其拖到左侧工具条中即可。

直接在网上搜:hadoop-0.20.2-eclipse-plugin.jar
https://issues.apache.org/jira/secure/attachment/12460491/hadoop-eclipse-plugin-0.20.3-SNAPSHOT.jar
下载后,将jar包放在eclipse安装目录下的plugins文件夹下。然后启动eclipse
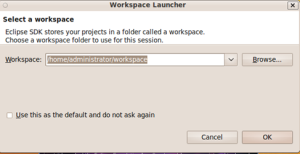
第一次启动eclpse后,会让我们设定一个工作目录,即以后建的项目都在这个工作目录下。
进入后,在菜单window->Rreferences下打开设置:
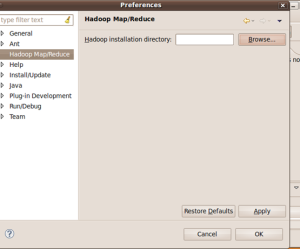
点击browse选择hadoop的源码下的Build目录,然后点OK
打开Window->View View->Other 选择Map/Reduce Tools,单击Map/Reduce Locations,会打开一个View,

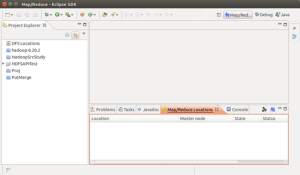
添加Hadoop Loacation,其中Host和Port的内容跟据conf/hadoop-site.xml的配置填写,UserName 是用户名,如
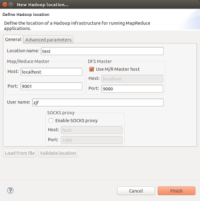
在配置完后,在Project Explorer中就可以浏览到DFS中的文件,一级级展开,可以看到之前我们上传的in文件夹,以及当是存放的2个txt文件,同时看到一个在计算完后的out文件夹。
现在我们要准备自己写个Hadoop 程序了,所以我们要把这个out文件夹删除,有两种方式,一是可以在这树上,执行右健删除。 二是可以用命令行:
$bin/hadoop fs -rmr out
用$bin/hadoop fs -ls 查看
环境搭建好了,之前运行Hadoop时,直接用了examples中的示例程序跑了下,现在可以自己来写这个HelloWorld了。
在eclipse菜单下 new Project 可以看到,里面增加了Map/Reduce选项:
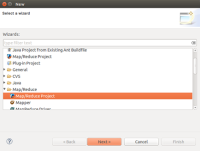
选中,点下一步:
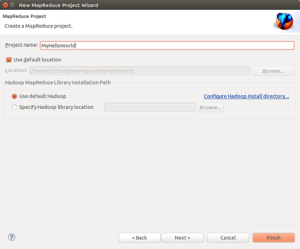
输入项目名称后,继续(next), 再点Finish
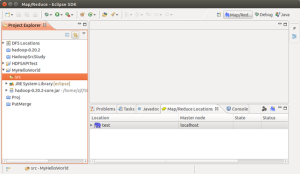
然后在Project Explorer中就可以看到该项目了,展开,src发现里面啥也没有,于是右健菜单,新建类(new->new class):
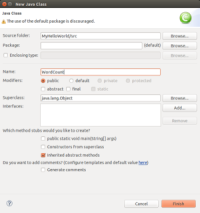
然后点击Finish,就可以看到创建了一个java类了:
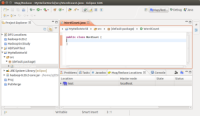
然后在这个类中填入代码:
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
System.out.println("key=" +key.toString());
System.out.println("Value=" + value.toString());
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
System.out.println("url:" + conf.get("fs.default.name"));
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
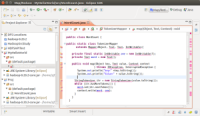
填入代码后,会看到一些错误,没关系,点击边上的红叉,然后选择里面的import即可;
如果想偷懒,则可以直接在类的开头帖入下面的这些引用:
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser;
这里,如果直接用源码来操作,可能会GenericOptionsParser这个类找不到定义,还是红叉,没关系,如果还是红叉,可以添加commons-cli-1.2.jar
这个jar包,在build/ivy/lib/Hadoop/Common下,右健Project Explorer中的MyHelloWorld工程,选择Build Path->Config Build Path
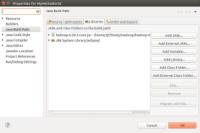
在Liberaries Tab页下,点击Add External JARs 在弹出窗口中,跟据前面说的目录,找到这个jar包,点确定后,回到工程,可以看到红叉消失,说明编译都通过了。
在确保整个工程没有错误后,点击上面的小绿箭头 ,然后在弹出的小窗口上,选择Run On Hadoop:
,然后在弹出的小窗口上,选择Run On Hadoop:
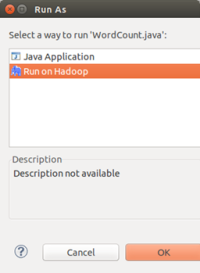
点OK后,会弹出小窗口:
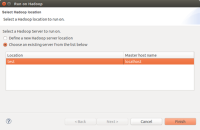
然手中选择Choose an existing server from the list below。然后找到之前配置的地址项,选中后,点Finish,然后系统不会Run起来,在控制台(双击可最大化)中可以看到运行结果:
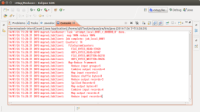
运行完后,用命令行可以看到 $bin/hadoop fs –ls 可以看到多了一个out文件夹,再用$bin/hadoop fs –cat out/*可以将out文件夹内容全显示出来,则可以看到单词的统计结果来。
问题1 :过程中,如果点了Run On Hadoop没有反应,则可能你下的这个有问题,重新到:https://issues.apache.org/jira/secure/attachment/12460491/hadoop-eclipse-plugin-0.20.3-SNAPSHOT.jar
上下载,然后将下载的插件重命名为"hadoop-0.20.2-eclipse-plugin.jar",放入eclipse中的plugins目录下。
问题2:运行后,如果结果里只输入了个usage <in> <out>,则需要修改下参数,在运行菜单边上小箭头,下拉,点击Run Configuration,:
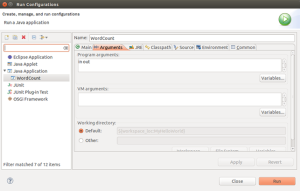
左边选中 JavaApplication中的 WordCount,右边,在Arguments中输入 in out。
然后再点Run 就可以看到结果了。
问题3:第二次运行会报错,仔细看提示,可以看到报错的是out目录已经存在,所以需要手动来删除一下。
Hadoop的框架最核心的设计就是:HDFS和MapReduce、HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










