Ubuntu 12.04单机版环境中搭建hadoop详细教程
一. 你要安装Ubuntu这一步省略;
二. 在Ubuntu下创建hadoop用户组和用户;
1. 创建hadoop用户组:
| sudo addgroup hadoop |
如图:
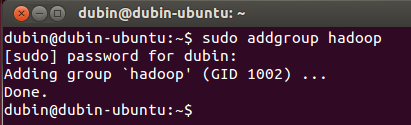
2. 创建hadoop用户:
| sudo adduser -ingroup hadoop hadoop |
如图:
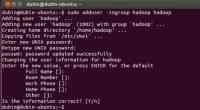
3. 给hadoop用户添加权限,打开/etc/sudoers文件:
| sudo gedit /etc/sudoers |
按回车键后就会打开/etc/sudoers文件了,给hadoop用户赋予root用户同样的权限。
在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL,
| hadoop ALL=(ALL:ALL) ALL |
如图:
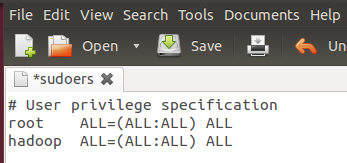
三. 在Ubuntu下安装JDK
使用如下命令执行即可:
| sudo apt-get install openjdk-6-jre |
如图:
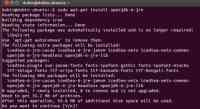
四. 修改机器名
每当ubuntu安装成功时,我们的机器名都默认为:ubuntu ,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定。
1. 打开/etc/hostname文件:
| sudo gedit /etc/hostname |
2. 将/etc/hostname文件中的ubuntu改为你想取的机器名。这里我取"dubin-ubuntu"。 重启系统后才会生效。
五. 安装ssh服务
这里的ssh和三大框架:spring,struts,hibernate没有什么关系,ssh可以实现远程登录和管理,具体可以参考其他相关资料。
安装openssh-server,
| sudo apt-get install ssh openssh-server |
这时假设您已经安装好了ssh,您就可以进行第六步了哦~
六、 建立ssh无密码登录本机
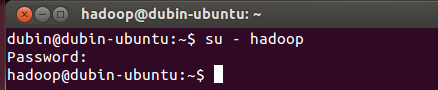
首先要转换成hadoop用户,执行以下命令:
| su - hadoop |
如图:
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1. 创建ssh-key,,这里我们采用rsa方式:
| ssh-keygen -t rsa -P "" |
如图:
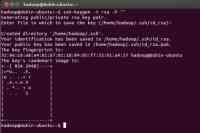
(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的)
2. 进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的:
| cd ~/.ssh cat id_rsa.pub >> authorized_keys |
如图:

(完成后就可以无密码登录本机了。)
3. 登录localhost:
| ssh localhost |
如图:
( 注:当ssh远程登录到其它机器后,现在你控制的是远程的机器,需要执行退出命令才能重新控制本地主机。)
4. 执行退出命令:
| exit |
七. 安装hadoop
我们采用的hadoop版本是:hadoop-0.20.203(http://www.apache.org/dyn/closer.cgi/hadoop/common/ ),因为该版本比较稳定。
1. 假设hadoop-0.20.203.tar.gz在桌面,将它复制到安装目录 /usr/local/下:
| sudo cp hadoop-0.20.203.0rc1.tar.gz /usr/local/ |
2. 解压hadoop-0.20.203.tar.gz:
| cd /usr/local sudo tar -zxf hadoop-0.20.203.0rc1.tar.gz |
3. 将解压出的文件夹改名为hadoop:
| sudo mv hadoop-0.20.203.0 hadoop |
4. 将该hadoop文件夹的属主用户设为hadoop:
| sudo chown -R hadoop:hadoop hadoop |
5. 打开hadoop/conf/hadoop-env.sh文件:
| sudo gedit hadoop/conf/hadoop-env.sh |
6. 配置conf/hadoop-env.sh(找到#export JAVA_HOME=...,去掉#,然后加上本机jdk的路径):
| export JAVA_HOME=/usr/lib/jvm/java-6-openjdk |
7. 打开conf/core-site.xml文件:
| sudo gedit hadoop/conf/core-site.xml |
编辑如下:
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!-- Put site-specific property overrides in this file. -->
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
8. 打开conf/mapred-site.xml文件:
| sudo gedit hadoop/conf/mapred-site.xml |
编辑如下:
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!-- Put site-specific property overrides in this file. -->
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>localhost:9001</value>
- </property>
- </configuration>
9. 打开conf/hdfs-site.xml文件:
| sudo gedit hadoop/conf/hdfs-site.xml |
编辑如下:
- <configuration>
- <property>
- <name>dfs.name.dir</name>
- <value>/usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2</value>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/usr/local/hadoop/data1,/usr/local/hadoop/data2</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>2</value>
- </property>
- </configuration>
10. 打开conf/masters文件,添加作为secondarynamenode的主机名,作为单机版环境,这里只需填写 localhost 就Ok了。
| sudo gedit hadoop/conf/masters |
11. 打开conf/slaves文件,添加作为slave的主机名,一行一个。作为单机版,这里也只需填写 localhost就Ok了。
| sudo gedit hadoop/conf/slaves |
八. 在单机上运行hadoop
1. 进入hadoop目录下,格式化hdfs文件系统,初次运行hadoop时一定要有该操作,
| cd /usr/local/hadoop/ bin/hadoop namenode -format |
2. 当你看到下图时,就说明你的hdfs文件系统格式化成功了。
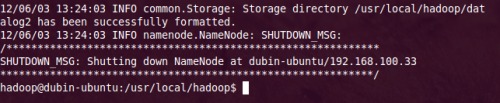
3. 启动bin/start-all.sh:
| bin/start-all.sh |
4. 检测hadoop是否启动成功:
| jps |
如果有Namenode,SecondaryNameNode,TaskTracker,DataNode,JobTracker五个进程,就说明你的hadoop单机版环境配置好了!
如下图:
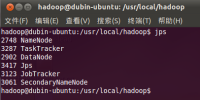
至此,一个hadoop的单机版环境就搭建好了,如果有什么问题,请给我提出来,咱们可以相互交流。
作者杜斌:http://www.db89.org/post/2012-06-03/hadoopdanjihuanjing
11月27日,Ubuntu图形库igraph发现拒绝服务重要漏洞,需要尽快升级。以下是漏洞详情。
ubuntu下教你如何安装JRE,openjdk-7-jre包只包含Java运行时环境(Java Runtime Environment)。如果是要开发Java应用程序,则需要安装openjdk-7-jdk包。
ubuntu修改主机名 1、查看Ubuntu当前主机名 在Ubuntu系统中,快速查看主机名有多种方法: 法一、在终端窗口中输入命令:hostname或uname n,均可以查看到当前主机的主机名; 法二、打开一个GNOME终端窗口,在命令提示符中可以看到主机名,主机名通常位于@符
笔者环境是Ubuntu 12.04版本,64位,安装在vmware workstation上,安装gcc的方法如下,sudo apt-get install build-essential。
为你的Ubuntu开启ssh是必须的,这样就可以通过ssd工具软件远程登录你的系统进行管理,方便,下面介绍如何开启Ubuntu ssh。
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










