XSKY开发了基于对象存储XEOS的专用Hadoop HDFS高性能客户端XSKY HDFS Client。
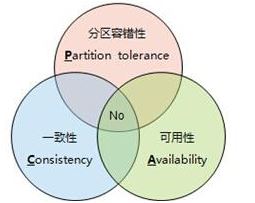
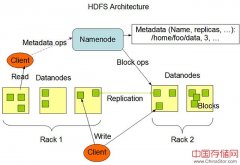
大数据分布式系统架构中CAP原理指的是,一致性(Consistency)、可用性(Availability)、分区容忍性(Partition tolerance)这三个要素最多只能同时实现两点,不可能三者兼顾。
证券交易数据属于典型的结构化数据,采用Sql on Hadoop[1]技术,既可用廉价PC服务器获得良好的容量线性扩展能力,又可提供便于统计分析的SQL接口方便数据应用开发。
本文总结Hadoop十个认识误区,帮助大家更好地理解和学习Hadoop。由于Hadoop本身是由并行运算架构(MapReduce)与分布式文件系统(HDFS)所组成,所以我们也看到很多研究机构或教育单位,开始尝试把部分原本执行在HPC 或Grid上面的任务
本文旨在提供最基本的,可以用于在生产环境进行Hadoop、HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用。
在mapreduce中设计了Speculator接口作为推断执行的统一规范,DefaultSpeculator作为一种服务在实现了Speculator的同时继承了AbstractService,DefaultSpeculator是mapreduce的默认实现。
今天的教程介绍的是3个节点的Hadoop平台建设。本次安装规划使用三个节点,每个节点都使用centos系统。

“红象数据高铁-CRH4”的RedHadoop Enterprise CRH4 For POWER版软件,是全球第一个支持OpenPOWER服务器的Hadoop商业版本。
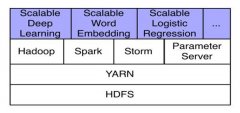
Hadoop集群已成为Yahoo大规模机器学习的首选平台,为了在这些强化的Hadoop集群上支持深度学习,我们基于开源软件库开发了一套完整的分布式计算工具,它们是Apache Spark和Caffe。
3节点hadoop集群的安装配置完成后,就是测试hadoop集群是否安装成功的方法,可以用jps命令和实例进行验证集群是否安装配置成功。

四个节点上均是CentOS6.0系统,并且有一个相同的用户hadoop。Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行
三节点hadoop集群配置和测试过程分享,系统:Ubuntu12.04,java版本:JDK1.7,机器分配:一台master,两台slave。
拥有Hadoop及其类似大数据工具,包括Cassandra、CouchDB、MongoDB以及Riak等等丰富使用经验同样会受到人才市场的热烈欢迎,以下关于Hadoop及相关专业知识的指导性意见。

由Cloudera 及O'Reilly主办的Strata + Hadoop World会议,是全球公认的最有影响力的大数据峰会,华为产品与解决方案CTO 李三琦做了主题为《Toward Big Data Driven Network》的keynote精彩发言.
东盟大多数国家使用的是开源软件,如Apache Hadoop,而还要一些公司使用其他基于Hadoop或MongoDB的开放源码。